Thanks for sharing this approach. It definitely helped put me on the right track to using XPaths.
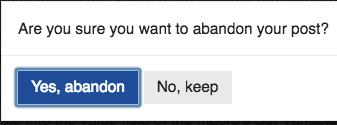
Unfortunately, your JavaScript doesn't work properly for me when used to click on the "cancel" link to a KM Forum reply or new topic:
- It does click on the link
- But then it causes the popup button "Yes, abandon" to be closed without clicking.
Here is the XPath that I used:
//*[@id="reply-control"]/div[2]/div[3]/div/div[3]/a
However, I found this simple script to work very well:
clickOnLink(document.kmvar.xPath);
function clickOnLink (pXPathStr) {
var elemFound = document.evaluate(
pXPathStr, document, null, 0, null
).iterateNext();
if (elemFound) {
elemFound.click();
}
else {
alert('Element NOT FOUND for XPath:\n' + pXPathStr);
}
};
I don't really understand the purpose of the function(e) in your script, but I don't seem to need it.