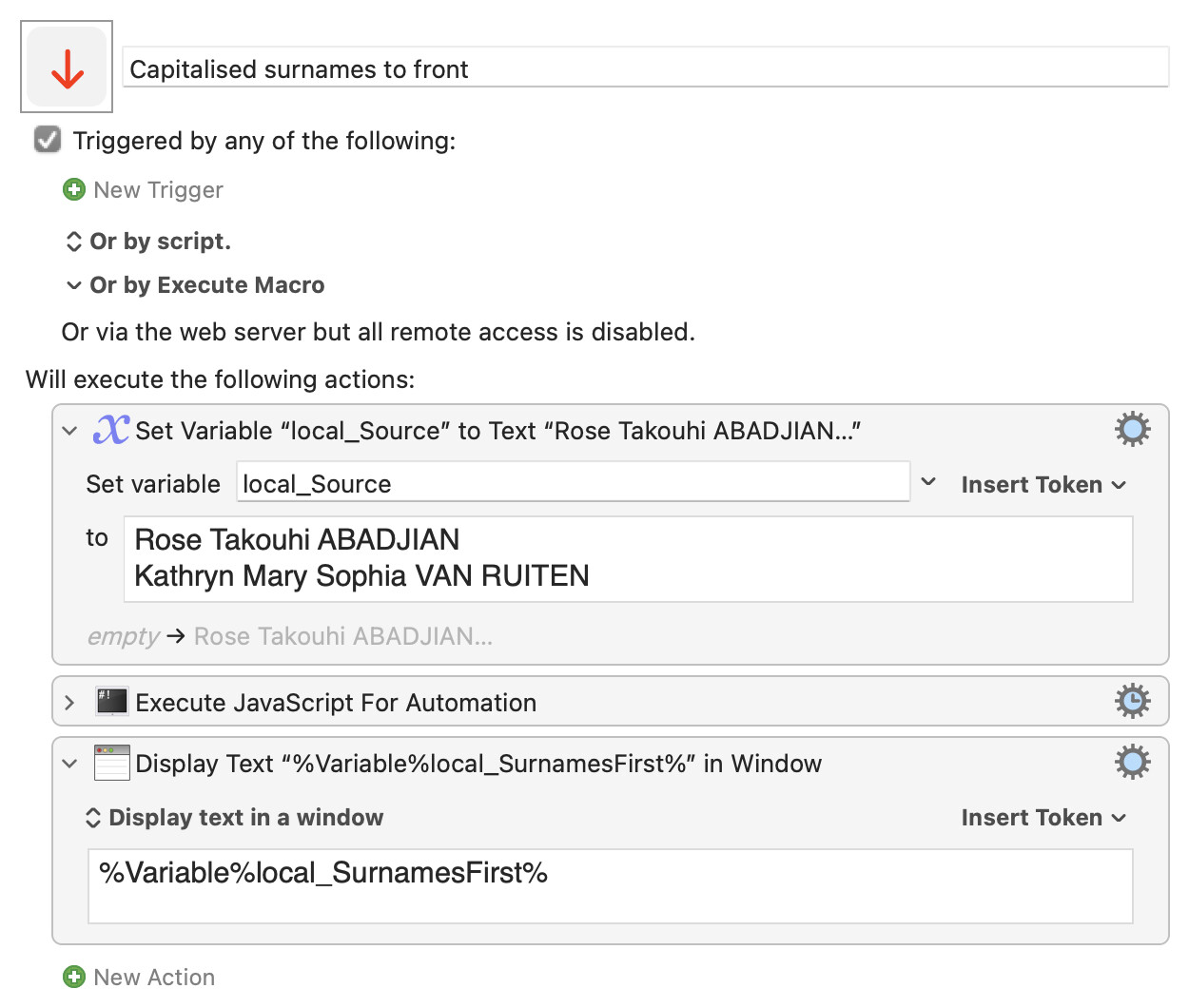
Names can have a multitude of special cases. (I've administered over 1000 names myself.) For example, if you had the name:
Harry S TRUMAN
which of the following would that be correctly converted to: (Truman's full legal middle name was "S")
TRUMAN, Harry S
S TRUMAN, Harry
Based on your instructions above, the second one is what would be chosen. But that doesn't look right.
There are also many unusual characters in names, like dashes and apostrophes. Which characters are allowed in your names? I've seen some names (even names of people who speak English) whose name begins with (or contains) an apostrophe. E.g., "D'arcy".
In any case, I'll try to write up a simple macro to help you, after posting this message, but my macro may fail on special cases like the ones above.
However making this work in your macro may take some finessing. That's because it's not clear to me exactly what you want. You said "if copy X I want to paste Y." For starters, I'm not sure if that means you want a single trigger to do both the copy and paste, or whether you want a separate macro to do the paste, or whether you want the paste to replace the currently selected text or not. So I can't really complete this macro until I know what you want.
P.S. There was a spelling mistake in the title of your post, so I fixed it. I hope you don't mind. I didn't know I had the authority to edit titles.
const main = () =>
kmvar.local_Source
.split("\n")
.map(
name => [...partition(isLower)(name.split(/\s+/u))]
.map(xs => xs.join(" "))
.toReversed()
.join(", ")
)
.join("\n");
// ------------------ GENERIC FUNCTIONS ------------------
// isLower :: String -> Bool
const isLower = s =>
// True if s contains a lower case character.
(/\p{Ll}/u).test(s);
// partition :: (a -> Bool) -> [a] -> ([a], [a])
const partition = p =>
// A tuple of two lists - those elements in
// xs which match p, and those which do not.
xs => [...xs].reduce(
([a, b], x) =>
p(x)
? [a.concat(x), b]
: [a, b.concat(x)],
[[], []]
);
return main();
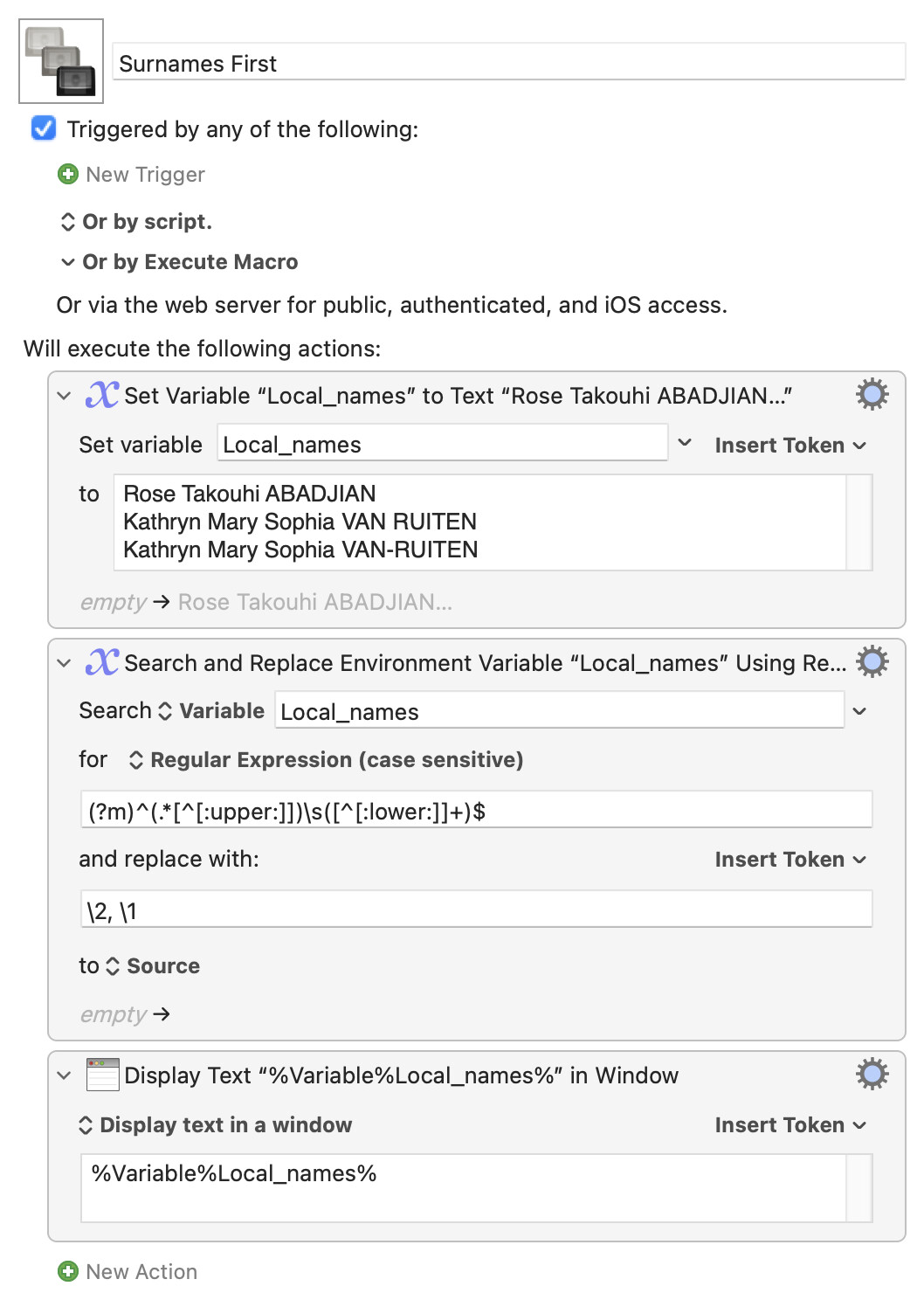
Bearing in mind @Airy's warning about single capital letter middle (or fore) names, you might formulate your rule as "the surname is the non-lowercase characters from the last non-uppercase character and space to the end of the string".
Putting it in that weird way accounts for numbers, punctuation, and spaces in either part. And since KM regex engine can use POSIX character classes we can search for:
(?m)^(.*[^[:upper:]])\s([^[:lower:]]+)$
...replacing with \2, \1 (second match group, comma, space, first match group).
Names are difficult. If you have any control over the source data then move to split it into at least "Forename", "Middle Names", and "Surname" fields. If you don't have any control then make your displeasure known to the person who does, in whatever way it takes to get them to change things!
It sounds like you have a solution. Also, I'm sorry for not knowing that "Forename" was a synonym for "First Name." I have never seen that word in my life.
I’m grabbing the name from wherever. It might be on a website, I may copy the text from a screenshot.
When I grab the name, I then search for it in my desktop software Family Tree Maker, in which the index to look up the name is very much SURNAME, Forename.
And I will miss that damned comma when typing every time. The delete key is the most used on my keyboard, and I’m forever hitting the backslash instead by accident, making me hit delete that many more times.