I have a script that creates a list of file names for selection in KM. A simple sed command
ls | sed -e 's/.[^.]*$//'
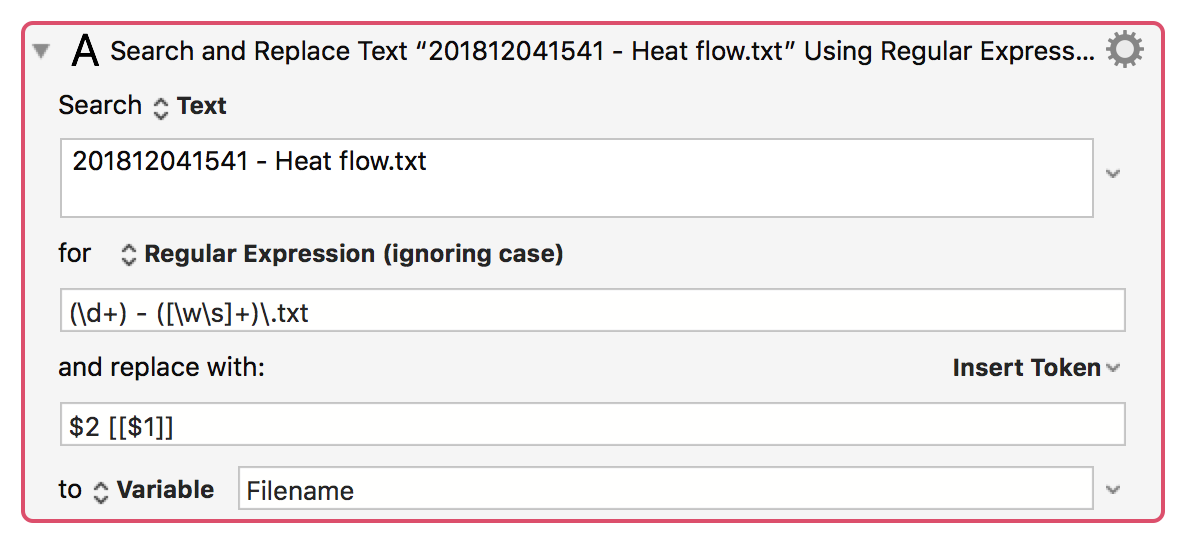
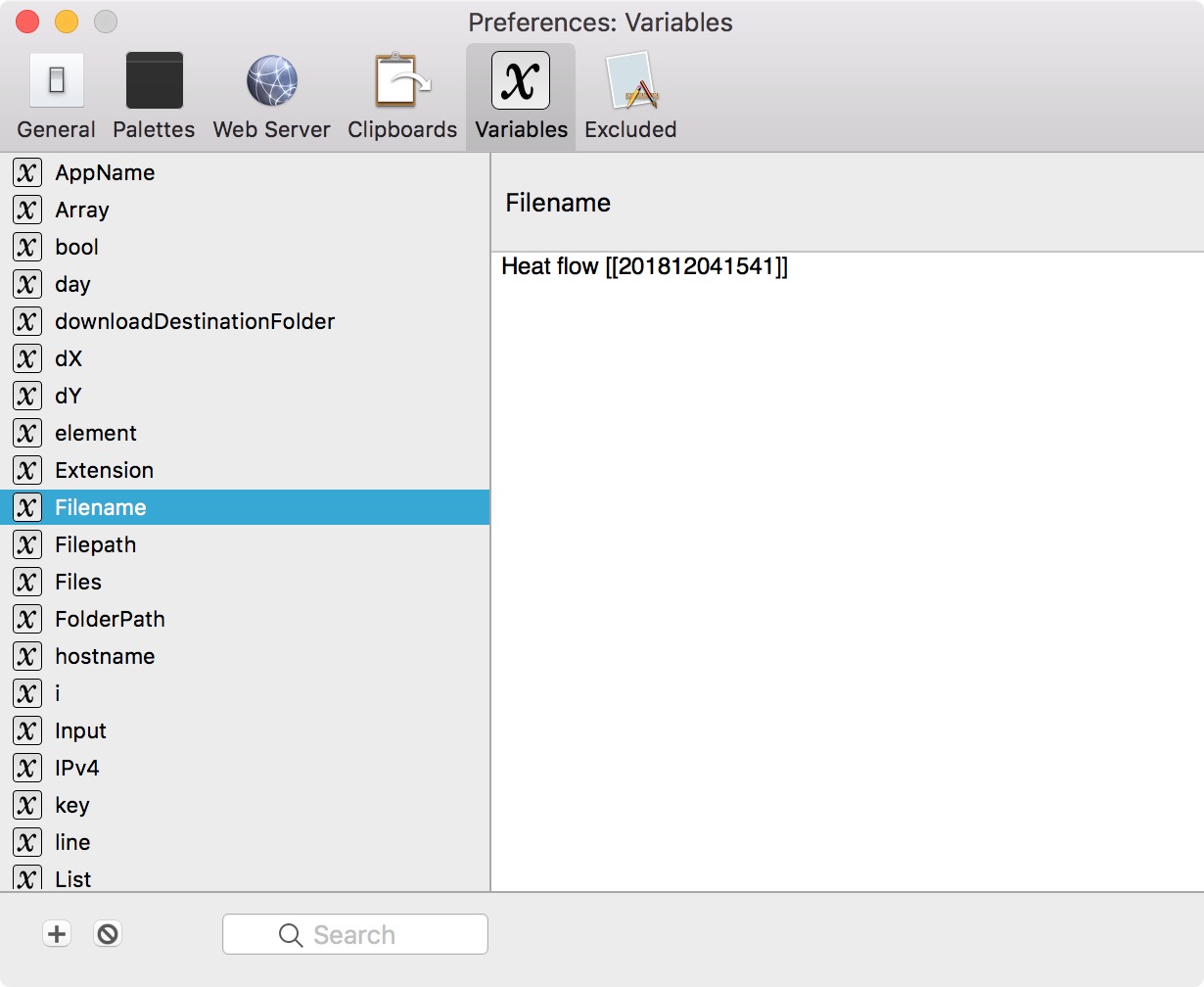
These file names all have the format of 201812041541 - Heat flow.txt and the result is 201812041541 - Heat flow
What I'm trying is to get the same list of file names in the format Heat flow [[201812041541]]
I'm not sure at all how to proceed. Grab a couple of pieces of a line and swap their positions and add '[[]]'. Sed? AWK? Something else? Suggestions.
Yes! Thank you, Chris, for this great help. I'd like to learn a bit about the particulars of how regex is used here so I can apply the principles in other macros. I can't express enough my appreciation for your sharing of your expertise.
Correct me if I'm wrong. But at a high-level sed is used to create the two variables ($1 and $2) and awk is used to swap their places?
Now I just need to refine this a little as there are a group of file names that don't have the "-" between the ID and Name. As in 201811151027 Causal Chain.txt. The file name is always made up of an ID (Machine date and time) followed by a space then sometimes a "-", sometimes just text. But always the first space in the filename.
Here is a partial output of the command. You can see it works in the instance I asked about but I failed to appreciate the differences in my naming conventions.
Output
Don't Shoot the Dog [[201811151030]]
[[201811151032 How to Take Smart Notes]]
[[201811151033 Making the most of life]]
[[201811151036 The Other End of the Leash]]
Body space [[201811151039]]
Quanta [[201811151116]]
Original filenames
201811151030 - Don't Shoot the Dog.txt
201811151032 How to Take Smart Notes.txt
201811151033 Making the most of life.txt
201811151036 The Other End of the Leash.txt
201811151039 - Body space.txt
201811151116 - Quanta.txt
Nyet. Sed is removing the file suffix and then turning the space and/or “-” separator into a tab for later use in Awk.
In Awk I've changed the field-separator “FS” into a tab and then I'm simply printing field numbers and literal strings. (If I didn't change the FS then Awk would consider any contiguous horizontal whitespace to be field-separators.)
Here's an updated script to fit your file-naming convention:
ls -1 ~/'test_directory/FOLDER 01/' \
| sed -E '
# Remove file suffix
s!\.[^.]+$!!
# Replace only the first contiguous space(s) and/or dash(s) with a tab.
s![[:space:]-]+! !
' \
| awk 'BEGIN { FS = "\t" }; { print $2 " [["$1"]]"}'
Here's how to do it with just Sed:
ls -1 ~/'test_directory/FOLDER 01/' \
| sed -E '
# Remove file suffix
s!\.[^.]+$!!
# Use Capture-Groups to Reverse Name/Date
s!^([0-9]+)[[:space:]-]+(.+)!\2 [[\1]]!
'
NOTE – In Bash a “\” at the end of a line is the continuation-character, which allows breaking long lines into more than one line. Using this with care can make a script MUCH more readable.
In Sed I'm simply using capture-groups to move things around.