Both TW (now BBEdit Lite) and KM use RegEx based on PCRE.
So, they are very similar, but with some differences. KM uses the RegEx engine provided by the macOS, which is ICU Regular Expressions.
TW has been deprecated, replaced with BBEdit Lite. From the BBEdit User's Manual, Chapter 8, p168:
BBEdit’s grep engine is based on the PCRE library package, which is open source software, written by Philip Hazel, and copyright 1997-2004 by the University of Cambridge, England. For details, see: http://www.pcre.org/
KM uses the ICU Regular Expressions, which Unicode Technical Standard #18. This is, in essense, PCRE, "The regular expression patterns and behavior are based on Perl's regular expressions"
However, as best as I can tell (@peternlewis and @ccstone might know more about this) , BBEdit does do some things differently:
- All text opened/pasted in BBEdit is converted to linefeed as the newline character, if that is set as your default "Line break" in Preferences.
- It appears that they have changed the use of
\r \nand\Rto all simply match "'hard' line break".
[The above items are under review 2018-08-10.]
From the BBEdit User's Manual, Chapter 8, p173:
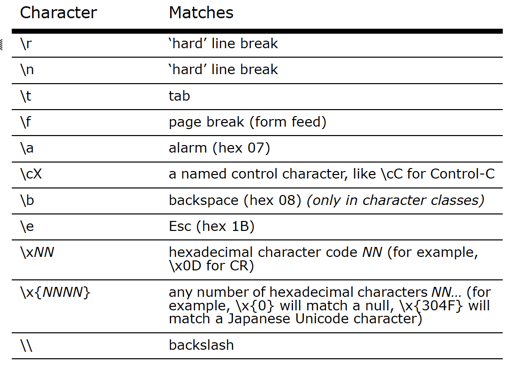
Personally, while I use BBEdit RegEx a lot to manipulate text, I rarely use it to develop RegEx patterns. For that, I mostly use Regex101.com
Sorry, but that is incorrect.
First of all, you need to use the backslash rather than the forwardslash.
Both BBEdit and KM can use both \r and \R, but they have different meanings, at least in ICU compliant apps like macOS and KM:

I'll try to post some RegEx references later.