I think I may be more optimistic than @Nige_S about performance –
even in the worst case, where the parsing of the whole snippet archive file is done in real time.
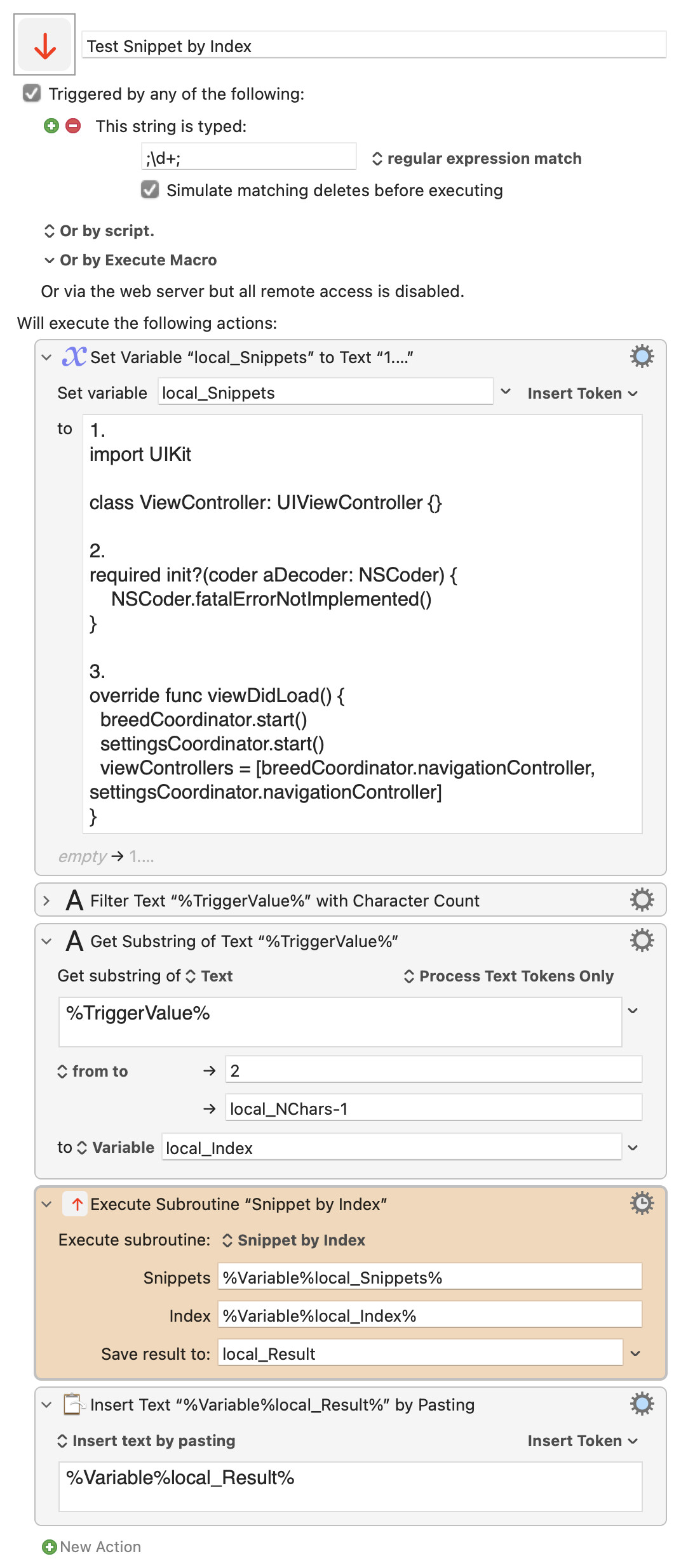
Here, to test and find out, is a subroutine:
- Install both the subroutine and the test macro which uses it, and
- paste the entire snippet archive into the variable
local_Snippets, then - specify the Index of a snippet to retrieve
Subroutine – Snippet by Index.kmmacros (4,5 Ko)
Test Snippet by Index.kmmacros (3.9 KB)
Expand disclosure triangle to view JS source
return (() => {
"use strict";
// Snippet by index from snippets text in format:
// 1.
// Codeline
// Codeline
// Codeline
// ...
// 2.
// Codeline
// Codeline
// Codeline
// etc
const main = () => {
const index = kmvar.local_Index;
return isNaN(index)
? `Expected numeric index, saw: "${index}"`
: unlines(
snippetsTextAsDict(
kmvar.local_Snippets
)[index] || [`Index "${index}" not found.`]
);
};
// snippetsTextAsDict :: String -> {Index :: [String]}
const snippetsTextAsDict = source => {
const rgxNumberLine = /(^\d+)\./u;
return lines(source).reduce(
([i, dict], s) => {
const
m = s.match(rgxNumberLine),
isMatched = null !== m,
k = isMatched
? m[1]
: "";
return isMatched
? newOrDuplicateIndex(k)(dict)
: [
i,
Object.assign(
dict,
{[i]: dict[i].concat(s)}
)
];
},
[0, {}]
)[1];
};
const newOrDuplicateIndex = k =>
dict => [
k,
Object.assign(dict, {
[k]: dict[k]
? dict[k].concat(
`WARNING - SNIPPET INDEX (${k}.) REUSED:\n`
)
: []
})
];
// --------------------- GENERIC ---------------------
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single string
// which is delimited by \n or by \r\n or \r.
0 < s.length
? s.split(/\r\n|\n|\r/u)
: [];
// unlines :: [String] -> String
const unlines = xs =>
// A single string formed by the intercalation
// of a list of strings with the newline character.
xs.join("\n");
// MAIN ---
return main();
})();