Thank you for your response, I guess you are referring to something like this?
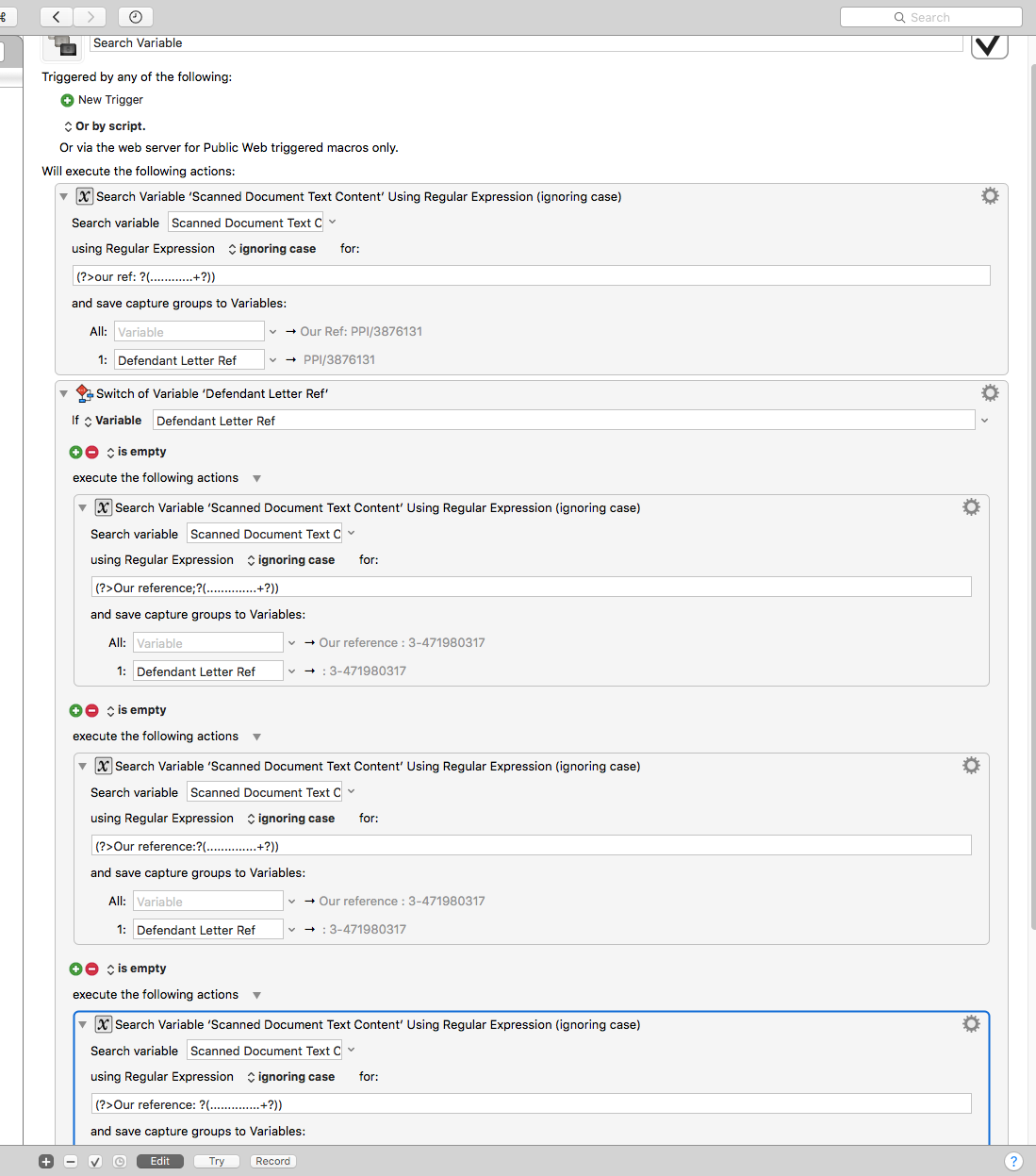
No, that's not what I meant. But it turns out that wasn't going to work anyway.
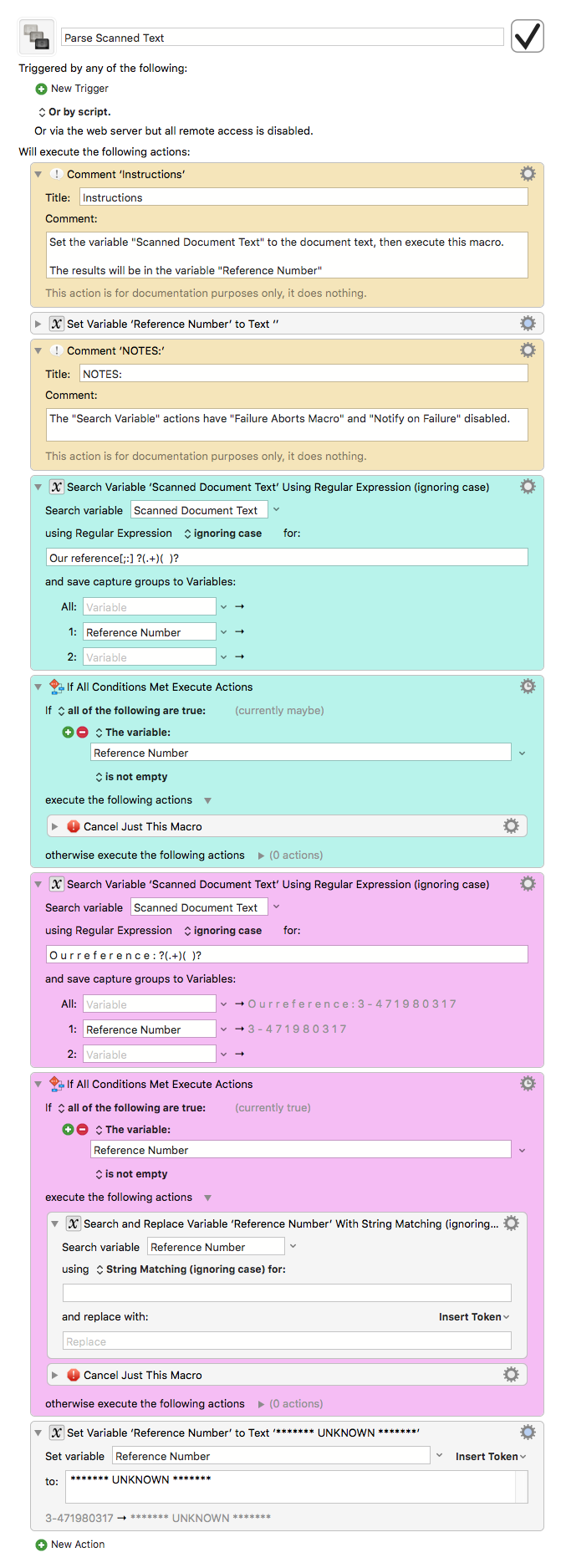
Try something like this. The idea is, you pass the OCR text in a variable called "Scanned Document Text". It tries to parse the variable. If it succeeds, the result is returned in the variable "Reference Number".
You add a "Search" action and an "If" action for each pattern you search for.
OCR Parsing Macros.kmmacros (9.3 KB)
This has a macro that you call to do the parsing:
I included a testing macro, which loops through some sample input, and shows the results:
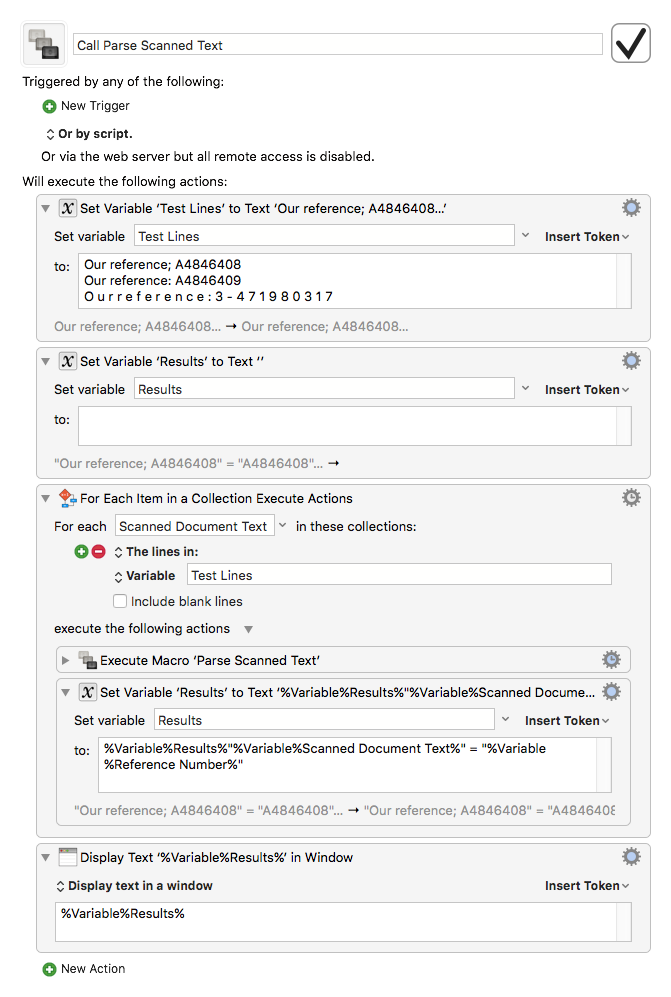
Let me know if this makes any sense at all to you. If you like it, I can whip up some additional regexes for the other examples you posted.
1 Like
@DanThomas makes a good point here:
As with most designs, every method has its tradeoffs. In this case, it is maintenance of many different "Switch" statements vs one RegEx you can maintain and test using regex101.com.
My preference here would be to use one RegEx.
To greatly simplify things, the first step I would do is to remove ALL [SPACES] in the source text.
(this is easily done with a KM Action to "Search and Replace" in a Variable.)
Having done that, here is a RegEx that is not too complex:
(?mi).*(?:(?:ref.*(?:\:|;|u|com))|re:)(.+)[ \t]*
See: regex101: build, test, and debug regex
Here is how it matches ALL of the cases in your source text:
The text highlighted in green is the captured reference#.
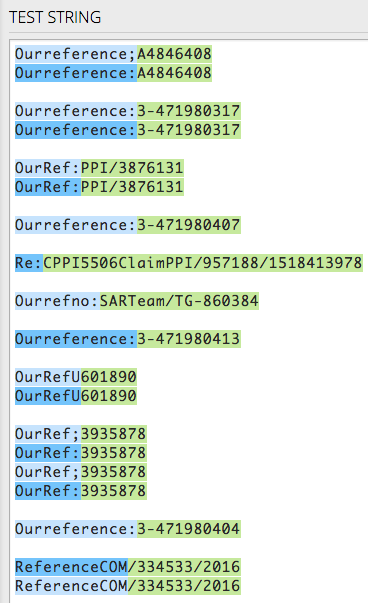
Note that I assumed/used both "U" and "COM" as delimiters, and thus are NOT included in the captured ref no. If you need these to be part of the ref no, let me know and I'll make some adjustments.
Here is the regex101.com explanation:
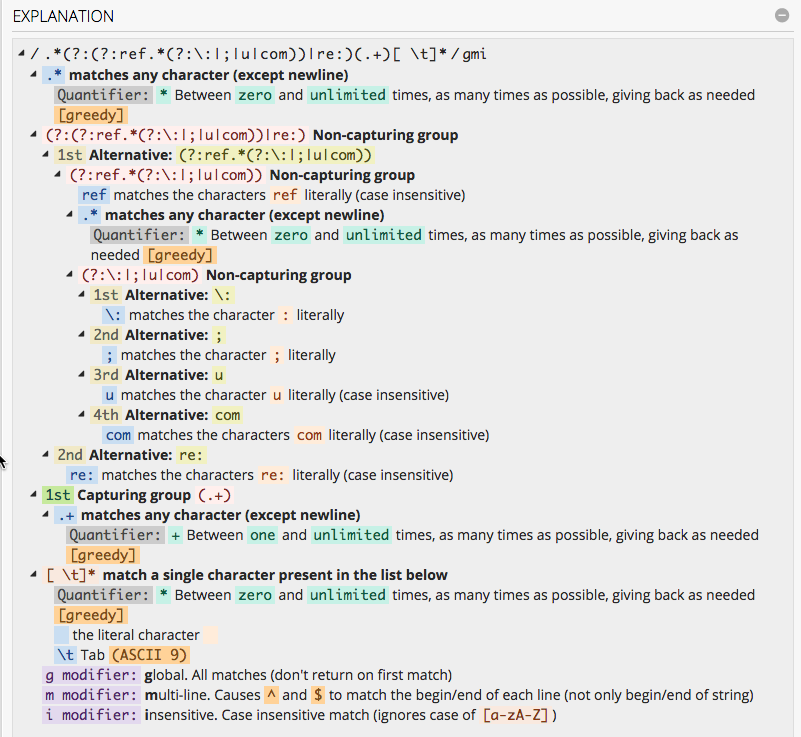
IMO, this would not be that hard to maintain/change if you discover new cases. Just open up regex101.com link and add the new case to the existing source text.
Good luck, and let us know how it goes.
1 Like
He can't do this, because he tells the end of the reference number either by the end of the string, or by 2 or more trailing spaces. Otherwise I would have recommended it.
Having done that, here is a RegEx that is not too complex:
LOL. Perhaps not for those of us who can read regular expressions, but I guarantee the other 99.95% of the population would beg to disagree, even with regex101's help. ![]()
But if the OP finds this readable, then by all means, go for it! ![]()
I'm not sure that is a firm requirement.
After I removed all spaces the RegEx correctly identified the ref numbers in all cases.
@demirtas1, please post a REAL example of source text that we can use to test with.
Do you really need trailing spaces AFTER the reference no, or just the end of line?
Well, I don't have any real statistics, but if I can read it, then it can't be that hard. ![]()
Most of my RegEx is simply alternatives (the text separated by vertical bars).
I think anyone with basic knowledge of RegEx can read the RegEx101.com explanation, and understand it.
IOW, if @demirtas1 can read/understand the RegEx patterns you have posted, then, with a bit of study, should be able to read/understand the explanation.
All just my 2¢, of course.
It is. He mentions it somewhere above.
But I agree that with more specific examples, we can surely provide better responses.
If 2 or more spaces IS a requirement, then it is still easy to deal with:
- Replace all [2 or more spaces] with something, like "[2SP]"
- Then replace all spaces with nothing.
So you get this, easy enough to parse:
Ourreference;A4846408[2SP]moretext
Ourreference:A4846408
2 Likes
This regex will find the remainder:
(?:(?:[Oo][ ]*u[ ]*r)?[ ]*[rR][ ]*e[ ]*f[ ]*(?:e[ ]*r[ ]*e[ ]*n[ ]*c[ ]*e[ ]*)?(?:n[ ]*o[ ]*)?[;:]?[ ]*|[rR][ ]*e[ ]*[;:][ ]*)(.*)
After that you deal with the remainder any way you like, searching for multiple spaces, removing spaces, etc.
1 Like
Sometimes the code of this macro thinks that your ref is the same as our ref:
please use this expression Our ref[;:] ?(.+)( )?
from the OCR text below is would grab the result ‘I Ippi/aa/aaaa’
15 September 2016 O u r R e f : WC / 1 1 1 0 1 1 1 1 2 1 / 1 1 1 1 1 1
Your Ref; I Ippi/aa/aaaa
Strictly Private and Confidential
De a r Si r s
how can I get the code to recognise that ‘your’ is not ‘our’?
One way would be change it to be case-sensitive. Another would be to add \b to to the front of it.
1 Like
And what can I do for the actual result which is stored as a variable to have not spaces inside it? ’ '*
Use Search and Replace. Search for a Space, replace with nothing. I think I show that in one of the match conditions - it may not be obvious because you can’t see the space in the edit box.
1 Like
Very helpful!
1 Like
You can use a negative look-behind assertion.
(?<![Yy][ ]{0,2})
Note that instead of [ ]* I used [ ]{0,2} (ie, 0 1 or 2 spaces) because “The length of possible strings matched by the look-behind pattern must not be unbounded (no * or + operators.)”.
Great, sometime we get the ref. but then straight after the ref on the same line the computer sees the date in the current form. we would want to get rid of this. which action should i use and how can i do?
eg ref: A4512245 15 March 2016
or
A1112245 20 September 2016
I How can we filter this layout from the variable
Does this happen in all formats, or only certain ones?
it can happen in all.
But the important thing is that the first string that we save as the variable is the actual ref that we need. Sometimes we get the date at the end of the ref but this is not all the time but at the moment I can say 2 in 10 times, so 20%.
Try something like this:
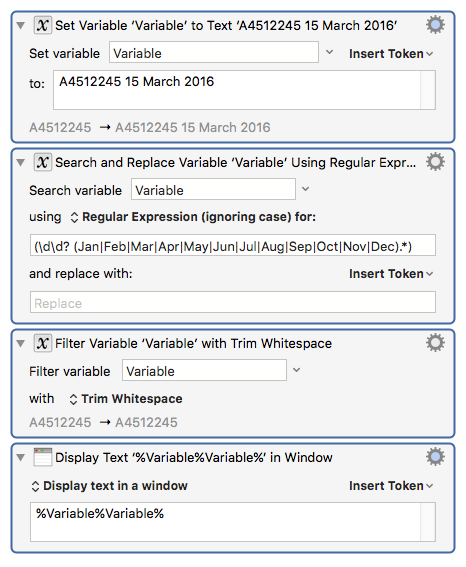
Here's the regex string:
(\d\d? (Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec).*)
1 Like
and how would I be able to save the date as a variable?
it could be in the form of DD/MM/YYYY or DD/Jan/2016 either in digits only or alphanumeric.
Well, you can extract the date string first, with a Search action. But as to how to convert it to a different date format, I don’t know. You should start a separate topic to ask how to convert that date string to a different date format.