So the difference is probably the shell -- use the same as you use in the Terminal and see if that helps.
If that posted shell script is complete then you didn't use a shebang line. IIRC when there's no shebang the default user shell is used which, in your case, is probably zsh. So try adding
#!/bin/zsh
...as the first line of your "Execute Shell Script" action (remembering that you may also have to set environment variables).
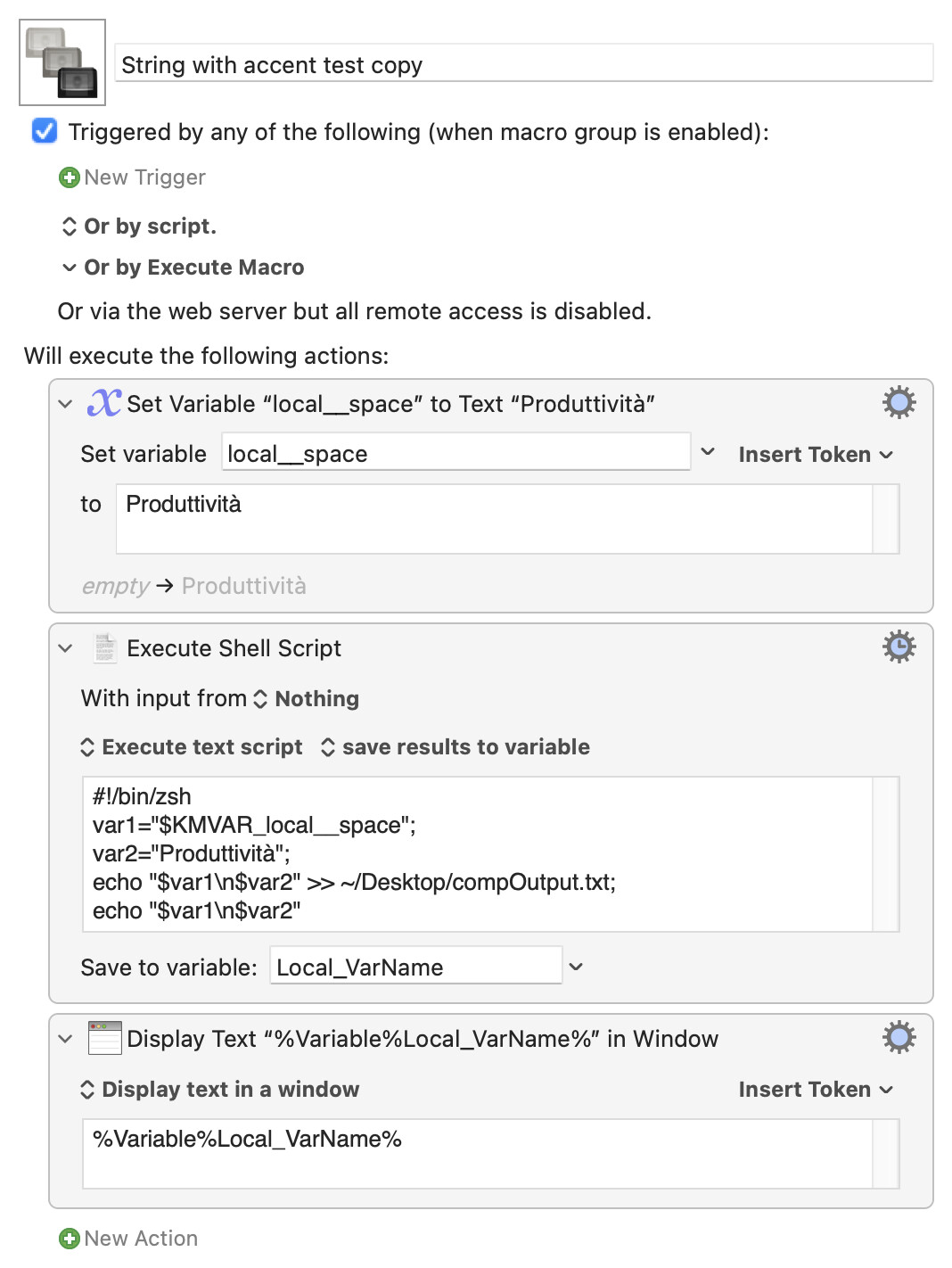
Yep, I see what you mean -- there appears to be a difference in the encoding of the à when passed by variable or typed into the KM "Execute Shell Script" action. If you run the following:
...but if you open the ~/Desktop/compOutput.txt file in BBEdit and "Zap Gremlins..." replacing with "HTML Entities" you get:
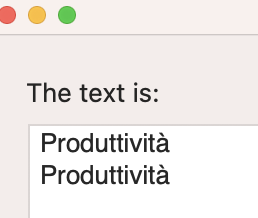
Produttività
Produttività
The first is a "Combining Grave Accent", "modifying" the previous character (the "a"), while the second is "Latin Small Letter A With Grave".
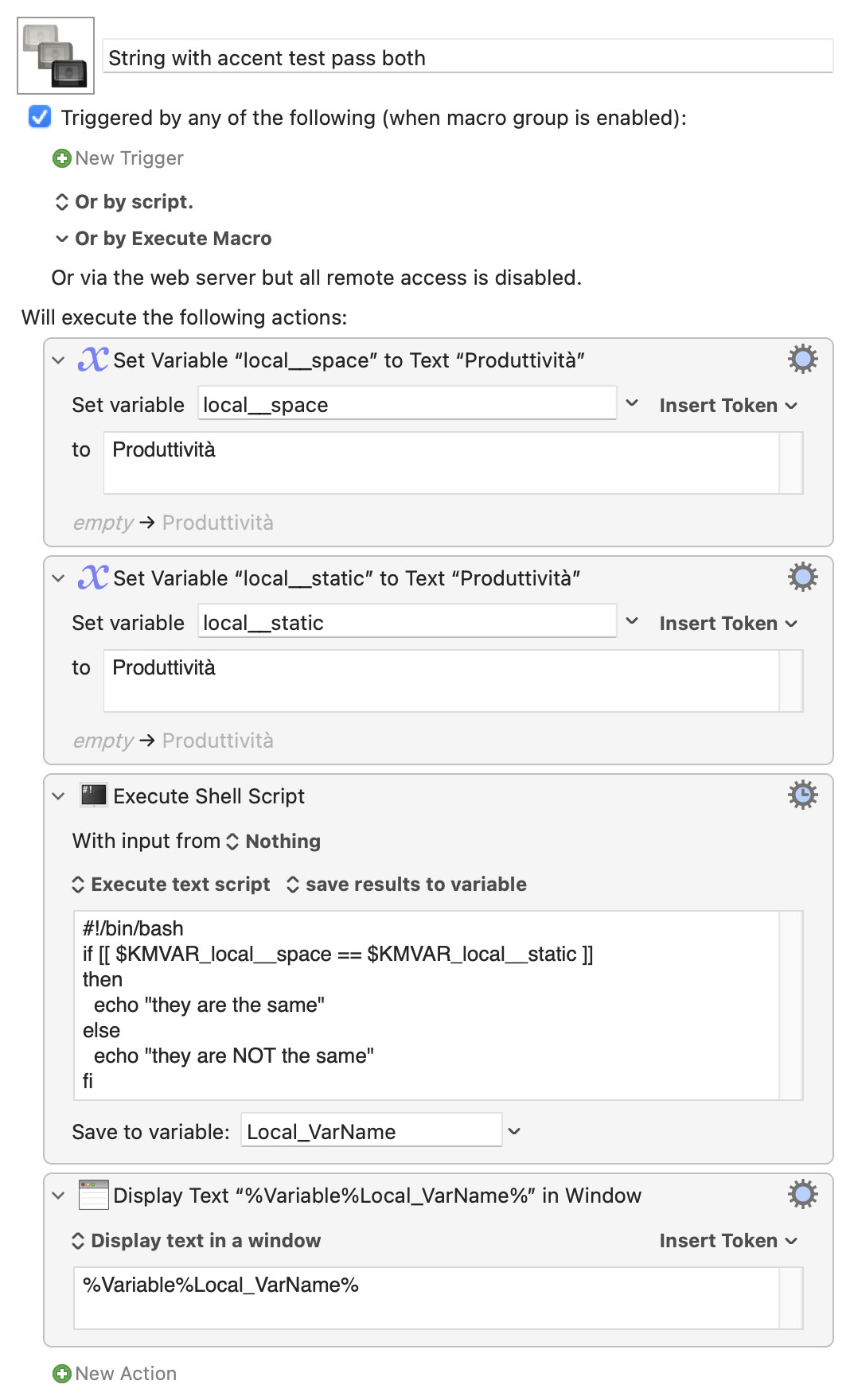
Rather than mess around any further I suggest you avoid the problem entirely by passing in the "fixed" string in your shell script as a KM variable as well -- that way, your diacritics will all be treated the same:
Thanks for the idea, but I can't do that. The fixed string I need to compare the parameter against is inside a database that is also used by other programs.
I guess I could try to add a "KM_value field" to the table, but definitely not my favourite option.
I'll think about it.
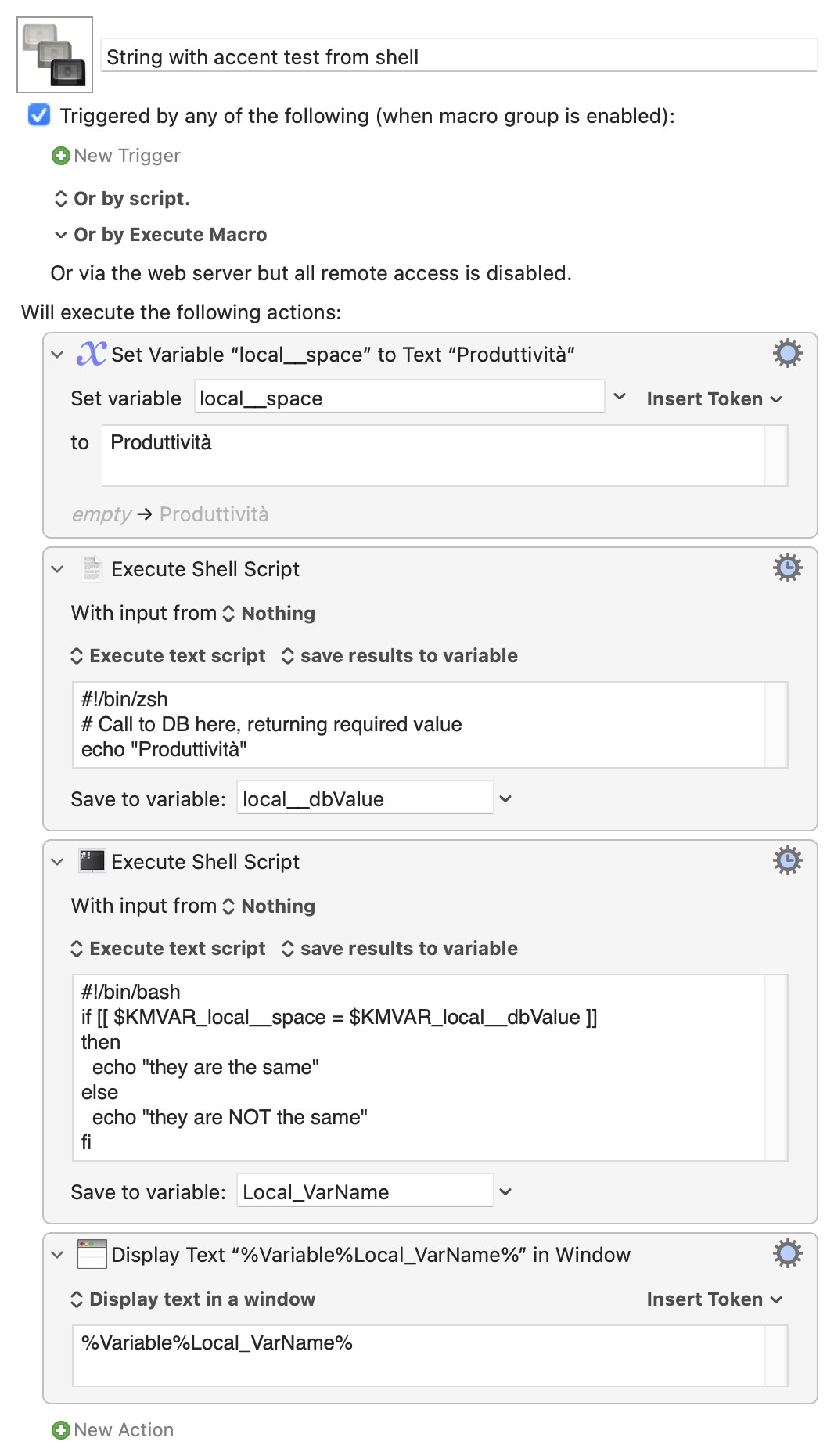
How were you going to reference it from your shell script (if, indeed, you were)? Perhaps you can pull it into a KM variable then push it back out in the script action:
If you can't pull it from the DB then you might be able to build a "translation table" and convert between character entities. Difficult to suggest more without knowing more details of your proposed implementation. Plus I'm already w-a-y outside my Unicode abilities!
There are many characters in unicode that have multiple ways to encode essentially the same encoding (and that is ignoring case discrepancies).
In this case there is the U+00E0 à character, and the a+combining accent U+0300 character.
You either need to precompose or decompose both strings before comparing them, or use a comparison that is precompose/decompose agnostic if you want to ensure that they match despite their differences.