![]() ︎
︎
Not enough indeed ![]() but thank you for your help.
but thank you for your help.
--Alain
tcsh gets closer but still seems to strip the diacritics from the variables when accessing them. For example:
#!bin/tcsh
setenv LANG en_US.UTF-8
setenv LC_CTYPE en_US.UTF-8
setenv LC_ALL en_US.UTF-8
setenv LANGSTATE en_US.UTF-8
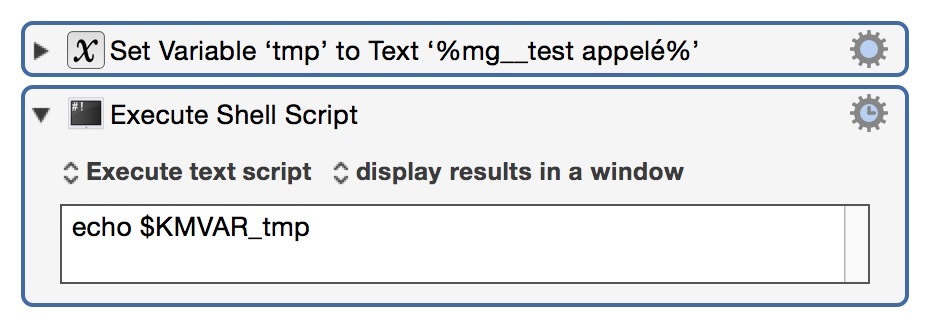
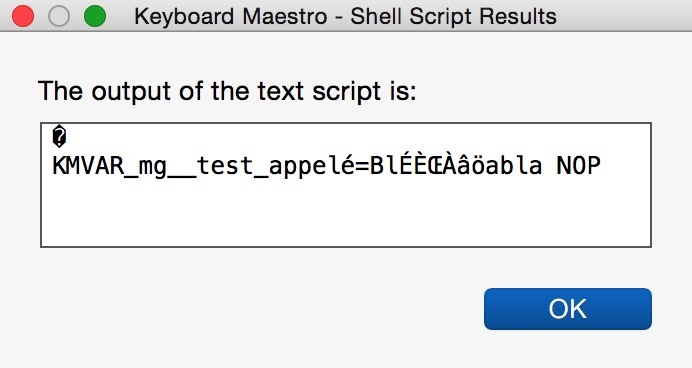
env | grep KMVAR_mg__test_appelé
echo $KMVAR_mg__test_appelé
displays this:
KMVAR_mg__test_appelé=BlÉÈŒÀâöabla NOP
KMVAR_mg__test_appele: Undefined variable.
Note how the accent is removed from the variable name in the error.
It’s probably possible somehow with tcsh, but I can’t see how at the moment. Might require reading through the source code.
I suppose you could always do an end-run around the environment variables. This works:
#!bin/tcsh
set v=`osascript -e 'tell app "Keyboard Maestro Engine" to get value of variable "mg__test appelé"'`
echo $v
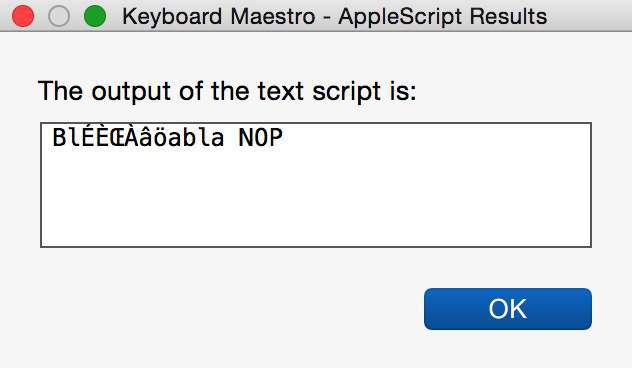
Here the very same code gives me:
KMVAR_mg__test_appelÃ: Undefined variable.
And:
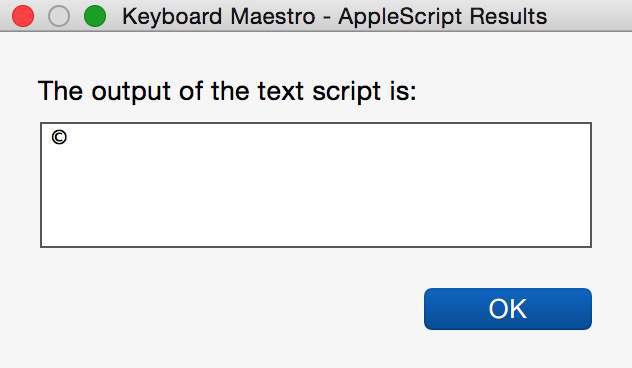
env | egrep KMVAR_mg__test_appel echo $KMVAR_mg__test_appelé
leads to
KMVAR_mg__test_appeleÌ=BlEÌEÌÅAÌaÌoÌabla NOP KMVAR_mg__test_appelÃ: Undefined variable.
This very basic too (hopefully) ![]()
--Alain
Yep. So as far as I can see, Keyboard Maestro puts them into the environment in the only possible way, and then the various shells simply do not support them from there. Your (@alain) results look like your shell is set to ISO-8859 (or some other 8 bit character set) instead of UTF-8 which is why you are seeing the bogus results from env | grep.
What I have to do to test switching to UTF-8?
The setenv stuff should do something:
setenv LANG en_US.UTF-8
setenv LC_CTYPE en_US.UTF-8
setenv LC_ALL en_US.UTF-8
setenv LANGSTATE en_US.UTF-8
I don’t really know which ones are required, what they do, or whether there are others that are also important, or some other setting.
I read it. Looks like an unresolved issue.
If you have text you'd like to add to the Wiki concerning this, please let us know. Otherwise, it is out of my skill/KB.
That issue has absolutely nothing to do with AppleScript -- it's a Shell Script problem.
-Chris
@JMichaelTX, @ccstone Please don't mind it's just a misunderstanding (maybe I wasn't explicit enough): I was just pointing out @JMichaelTX that I had already encountered difficulties regarding KM variables with diacritical characters, due to the shell interpretation through the natural interface in reaction at
Hoping to have been more clear ![]()
Cheers,
-Alain
There's monkey business when involving the shell with Unicode characters.
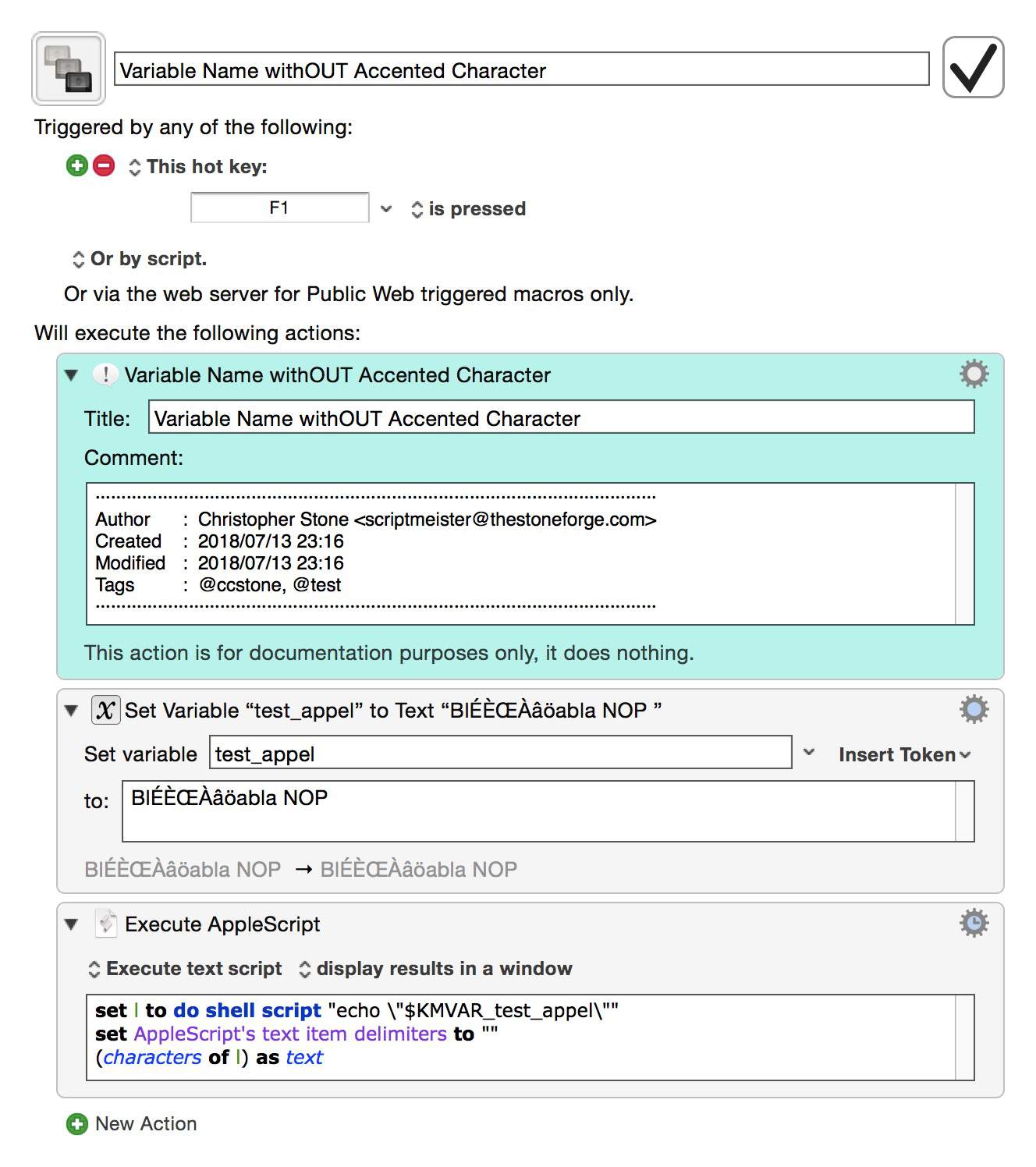
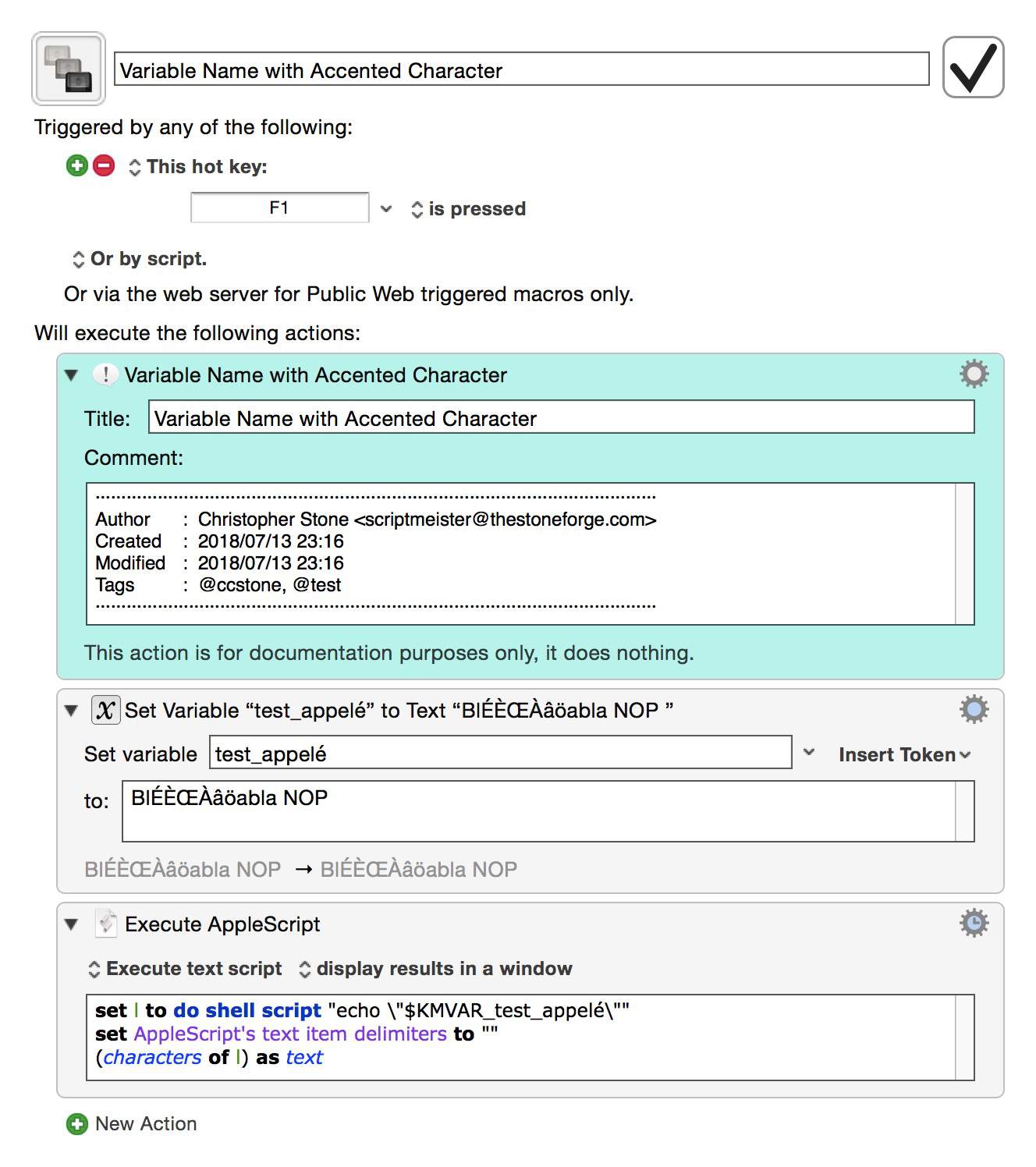
Accented Varaible Names -- 2-macros -- Test Group Macros.kmmacros (9.8 KB)
Note that the macro with the variable name ending in an accented character passes that character to the output...
-Chris
@ccstone Thank you Christopher for these careful and clear tests.
1- For the few KM  users who want to follow the discussion without doing these tests themselves here are their family portraits:
users who want to follow the discussion without doing these tests themselves here are their family portraits:
2- AppleScript appendix question: what is the instruction for?
set AppleScript's text item delimiters to "" (characters of l) as text
since deleting it (apparently) produces the same result?
-alain
Folks who are new to shell scripting and who might be looking here for help/advice/guidance should note that the above syntax is for tcsh.
It is more common to use bash or now zsh since it is now the default shell.
In those, you assign variables differently:
LC_ALL=en_US.UTF-8
LC_CTYPE=en_US.UTF-8
LANG=en_US.UTF-8
LANGSTATE=en_US.UTF-8
There are also cases where you might need to use:
LC_ALL=C
if you have a tool that is being fed UTF-8 but can't handle UTF-8, that might help.
I've stumbled upon this thread while trying to solve a problem I have.
I'm passing a string with an accent (in the value, not the name) to a shell action and it doesn't work as expected, just like said here.
What's making me thinking is that I don't have the same problem when I run the script in the shell. Let me give you an example:
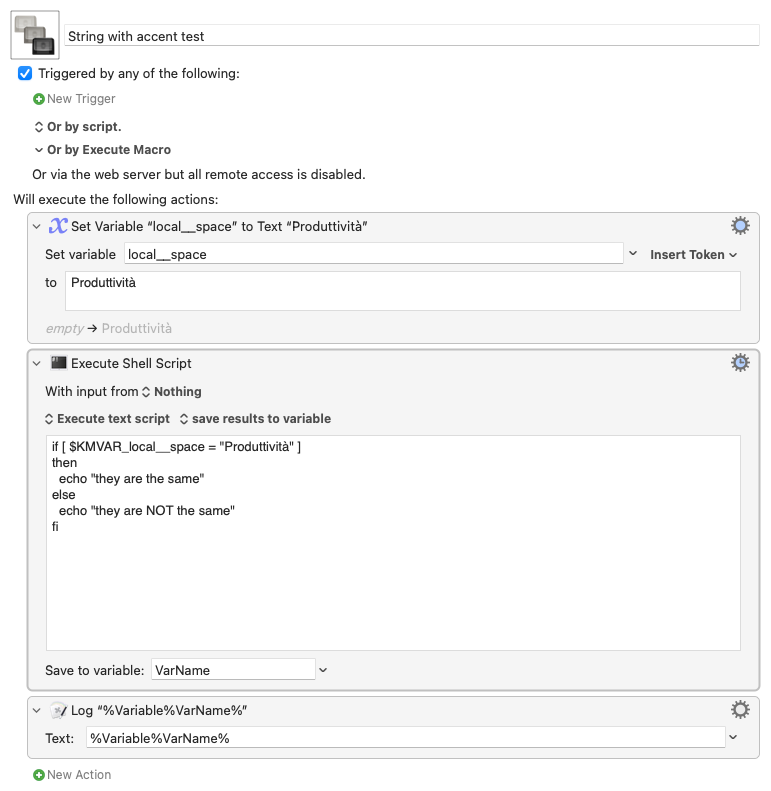
String with accent test Macro (v10.2)
String with accent test.kmmacros (2.3 KB)
This macro returns they are NOT the same
However, I've created this script:
if [ $1 = "Produttività" ]
then
echo "they are the same"
else
echo "they are NOT the same"
fi
and then I run it with
% ./x.sh Produttività
and the result is they are the same
I've also tried adding to set the languages to UTF-8 as suggested in this post, but that didn't work either.
I've also tried enclosing the shell script inside an Apple Script, but that didn't work either.
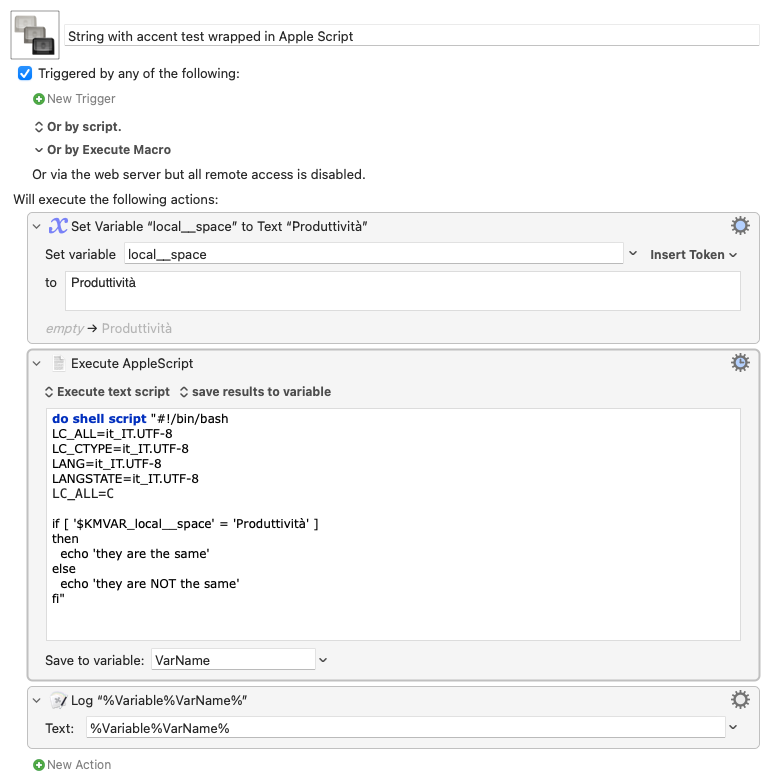
String with accent test wrapped in Apple Script Macro (v10.2)
String with accent test wrapped in Apple Script.kmmacros (2.4 KB)
I wonder if there is anything else I can try, you know, maybe a couple years later something changed 
Thanks,
Francesco
So the difference is probably the shell -- use the same as you use in the Terminal and see if that helps.
If that posted shell script is complete then you didn't use a shebang line. IIRC when there's no shebang the default user shell is used which, in your case, is probably zsh. So try adding
#!/bin/zsh
...as the first line of your "Execute Shell Script" action (remembering that you may also have to set environment variables).
Thanks Nige_S, but unfortunately adding the shebang doesn't change the result 
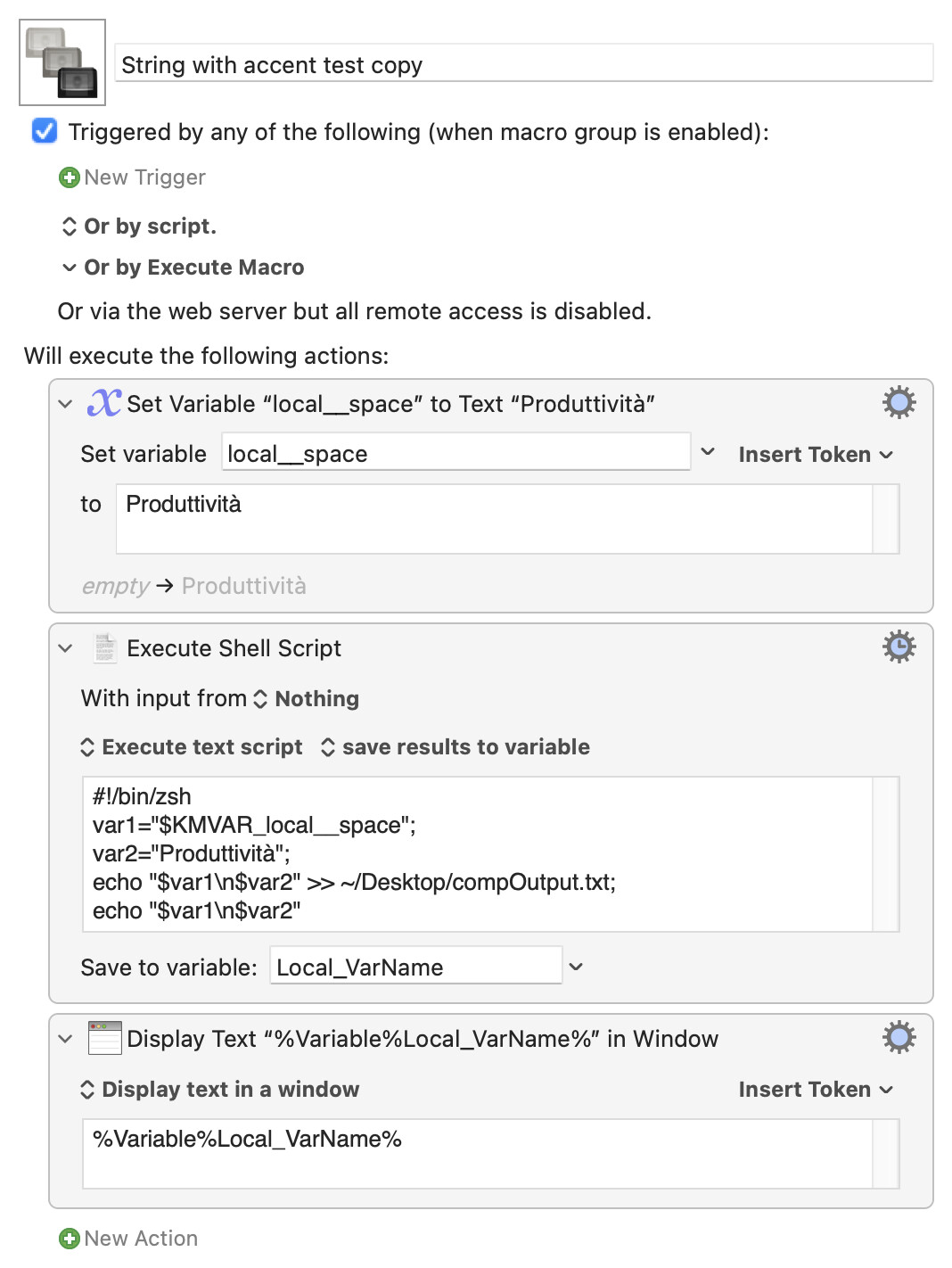
Yep, I see what you mean -- there appears to be a difference in the encoding of the à when passed by variable or typed into the KM "Execute Shell Script" action. If you run the following:
String with accent test copy.kmmacros (3.3 KB)
...then the displayed output looks the same:
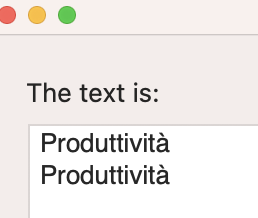
...but if you open the ~/Desktop/compOutput.txt file in BBEdit and "Zap Gremlins..." replacing with "HTML Entities" you get:
Produttività
Produttività
The first is a "Combining Grave Accent", "modifying" the previous character (the "a"), while the second is "Latin Small Letter A With Grave".
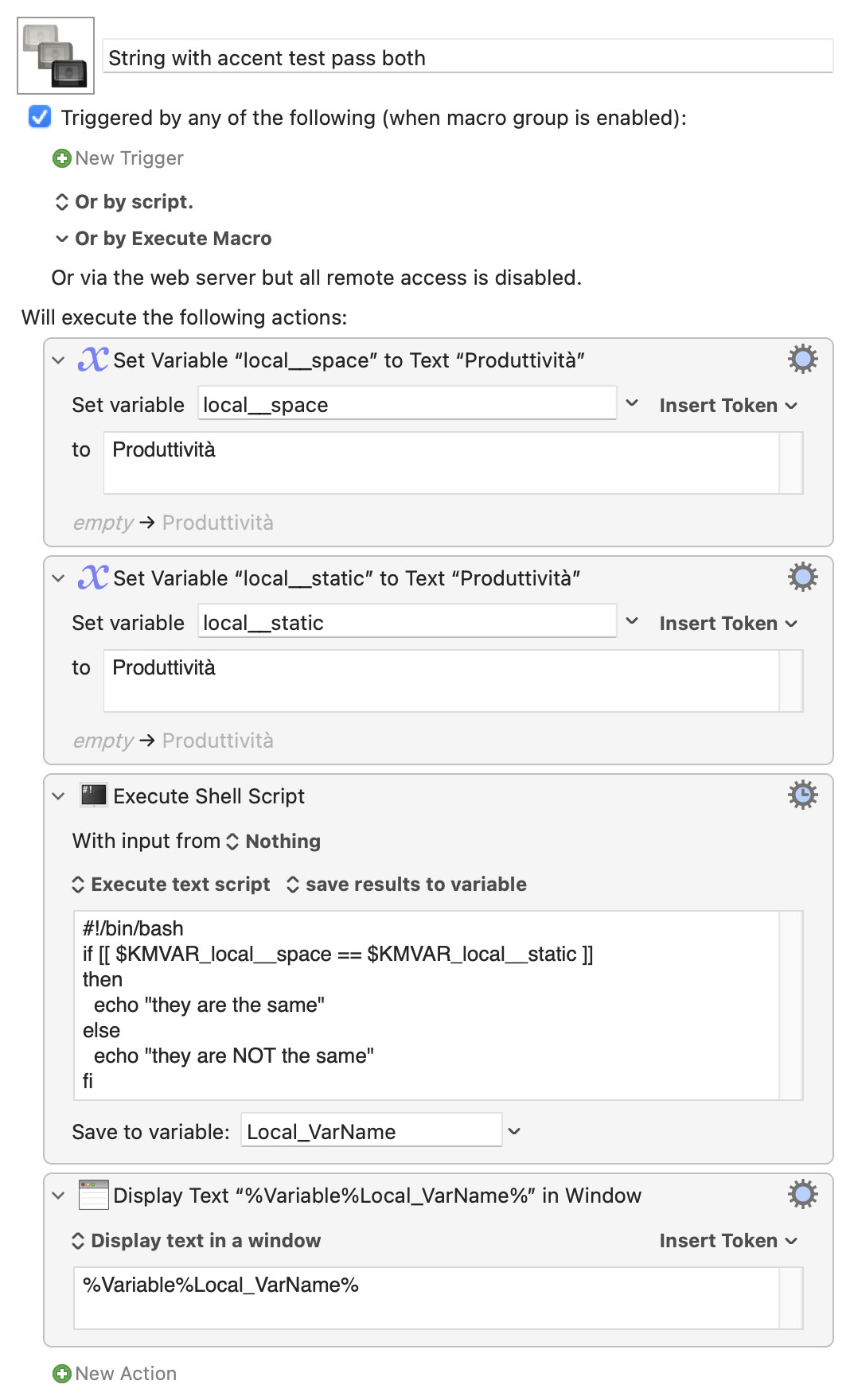
Rather than mess around any further I suggest you avoid the problem entirely by passing in the "fixed" string in your shell script as a KM variable as well -- that way, your diacritics will all be treated the same:
String with accent test pass both.kmmacros (3.6 KB)
@peternlewis -- am I on the right track, or spouting my usual nonsense?
Thanks for the idea, but I can't do that. The fixed string I need to compare the parameter against is inside a database that is also used by other programs.
I guess I could try to add a "KM_value field" to the table, but definitely not my favourite option.
I'll think about it.
Thanks anyway!
Francesco
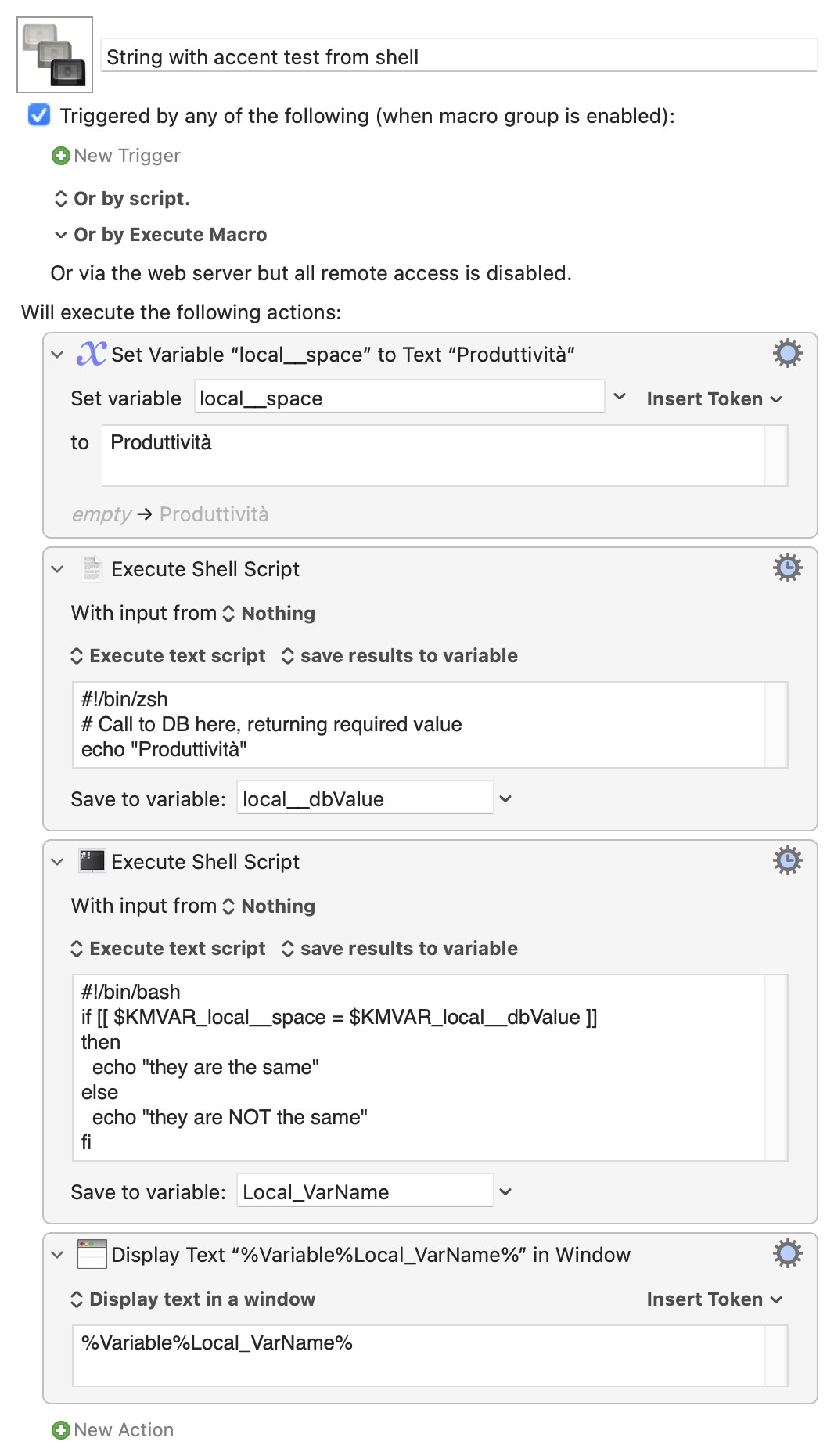
How were you going to reference it from your shell script (if, indeed, you were)? Perhaps you can pull it into a KM variable then push it back out in the script action:
String with accent test from shell.kmmacros (4.1 KB)
If you can't pull it from the DB then you might be able to build a "translation table" and convert between character entities. Difficult to suggest more without knowing more details of your proposed implementation. Plus I'm already w-a-y outside my Unicode abilities!
There are many characters in unicode that have multiple ways to encode essentially the same encoding (and that is ignoring case discrepancies).
In this case there is the U+00E0 à character, and the a+combining accent U+0300 character.
You either need to precompose or decompose both strings before comparing them, or use a comparison that is precompose/decompose agnostic if you want to ensure that they match despite their differences.