Since I’m not yet on Yosemite, and don’t have a JS development setup yet, could some kind person (hint, hint @ComplexPoint ) help me out with what I think is a simple JS function to extract the contents of a code block on a web page?
By code block I mean like the one used in this forum, and many other web pages. Short code blocks aren’t a problem to copy, but long code blocks that scroll are more of a challenge.
Example:
repeat with currentNotebook in EVNotebooks
set currentNotebookName to (the name of currentNotebook)
copy currentNotebookName to the end of listOfNotebooks
end repeat
Well, that depends on the discipline within which the page is written – less predictable than one might hope, alas.
This site happens to be rather standards-compliant, and simply wraps code in a <code> block. That means that if we click somewhere in the code, we should then be able to use an extend select macro like this:
But nothing guarantees that other sites will use <code> blocks to wrap what they present as code.
If you open the veritrope site which you link to above in Chrome, and ctrl-click somewhere in that syntax coloured block, choosing Inspect Element from the drop down menu, you will find that it is simply a lot of formatting markup, without a code block in sight.
This macro won't help in that kind of case, and you would find yourself having to write a different macro for every site that adopted its own particular approach …
Wow! Many thanks for the quick responce, Rob. As always, you are outstanding.
Thanks for the tip on using the "Inspect Element" tool. Very cool!
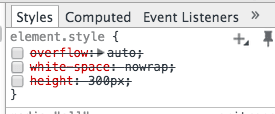
I found that I could change the HTML on the page just by unchecking the boxes in the Style column:
This allowed me to turn off the scrolling and turn on word-wrapping, making it much easier to select/copy.
The Veritrope site seems to use this for code blocks:
How hard would it be to use that to extract the code?
I'm wondering if it is reasonable to design a macro where the HTML tags denoting start of "code block" could be input/changed?
Sorry, I haven't looked at your macro/code yet. Should have done that first. Going to do that right now.
Hey Rob, if you're up for some more fun, I've been thinking about this, and doing a bit of research. Nothing urgent. What you already did is working well enough for most cases.
If I knew the web DOM better, I'd tackle this myself. But I'm still on a steep learning curve there.
My thought is this: Can we design a script that considers a number of possibilities, and then executes on the one that fits?
From my research, a lot of sites use the <pre> tag to start the code block. So maybe that is a common usage worth coding for.
The interesting thing is that when I use the "Inspect Elements" tool I can almost always spot by eye where the code block starts. If I can do it by eye, surely we (well, really you) can come up with a design to find the code.
Here's the results of my research. I hope it helps:
Well, no need to learn any more about the DOM, all you need to get a rough sense of is XPATH, which is a very rewarding (and actually rather small) search language.
A learning exercise ?
In the Chrome Inspect Element view of the HTML source, you can experiment directly:
⌘F
type a very simple XPATH like //a (all links, at any level of nesting in the HTML)
Thanks for all your help, Rob. I clearly need to go do my homework so I can better work these kind of problems. I've bought a couple of KIndle JS books, so I need to dig into one of them soon.
This is only for Safari — other browser support is left as an exercise for the reader.
** I have verified that the script will copy and compile properly, and I even tried the script on itself.
-Chris
set _date to short date string of (current date)
tell application "Safari"
tell front document
set selectedText to do JavaScript "
(function () {
var oSeln = window.getSelection(),
nodeTable = document.evaluate(
'./ancestor-or-self::code',
oSeln.anchorNode,
null, 0, 0
).iterateNext(),
rngDoc = nodeTable ?
document.createRange() : null;
if (nodeTable) {
oSeln.removeAllRanges();
rngDoc.selectNode(nodeTable);
oSeln.addRange(rngDoc);
}
})();
window.getSelection()+'';
"
set safariTitle to name
set safariURL to URL
end tell
end tell
set scriptHeader to "(*
====================================================
TITLE
====================================================
DATE: " & _date & "
AUTH:
REFR: " & safariTitle & "
: " & safariURL & "
*)
"
tell application "Script Editor"
activate
set newScript to make new document with properties {contents:scriptHeader & return & return & selectedText}
tell newScript to check syntax
end tell
While we are in mid-August optimisation and tweaking territory, glancing again at my JS code I notice a few things that could be adjusted or tightened up.
If we're only looking for one match, no need to heat the CPU in boreal summer by searching for more. Instead of leaving it to the default XPathResult.ANY_TYPE and using .iterateNext() to collect just the first (if any) match, we can look up the Result Type constants, specify XPathResult.FIRST_ORDERED_NODE_TYPE, and collect any match with .singleNodeValue().
XPATH expressions are chains of alternating 'Steps' and 'Filters'. We can broaden out the filter here with as many 'or' operators as we need. The simplest example might be: ./ancestor-or-self::*[self::code or self::pre]
We can include text collection inside the function with return oSeln.toString().
(and then perhaps, drop it into an Execute JS in Safari (and/or Chrome) action, directing the output to the clipboard).
Hmmm, I don't know about you, but I'm avoiding the hot, humid dogs days of August by hunkering down in my cold basement with lots of cold beer on ice. I'm fully optimized on being cool
But thanks for the update. It looks good as it adds more coverage.
I knew you could do it.
Same code seems to work in Chrome as well.
Or am I missing something?
I just tried it on the Evernote forum, and it worked well.
I'll test it on my other candidate sites.
The cases really look a bit too diverse for a single XPATH
MacScripter
//blockquote/div/p
Veritrope:
//span[@class='coMULTI']
//div[@id="content"]/*[self::pre or (self::p and @class='code')]
Github is a bit special. You might be better off clicking the RAW button:
(The raw page uses a <pre>)
On the pretty pages extend select would capture all the line numbers, so if you really wanted to copy from there you would have to write a slightly different, row-by-row (code cell but not number cell) function. Perhaps something roughly like:
Not sure I’m following you. As far as I can see the XPATH patterns vary by website …
You can know the paths on which particular site hold their code, but I don’t think there’s any way of travelling in the opposite direction – looking at the myriad branches and pathways of an HTML tree, and intuiting that some locations are holding code.
 ) help me out with what I think is a simple JS function to extract the contents of a code block on a web page?
) help me out with what I think is a simple JS function to extract the contents of a code block on a web page?