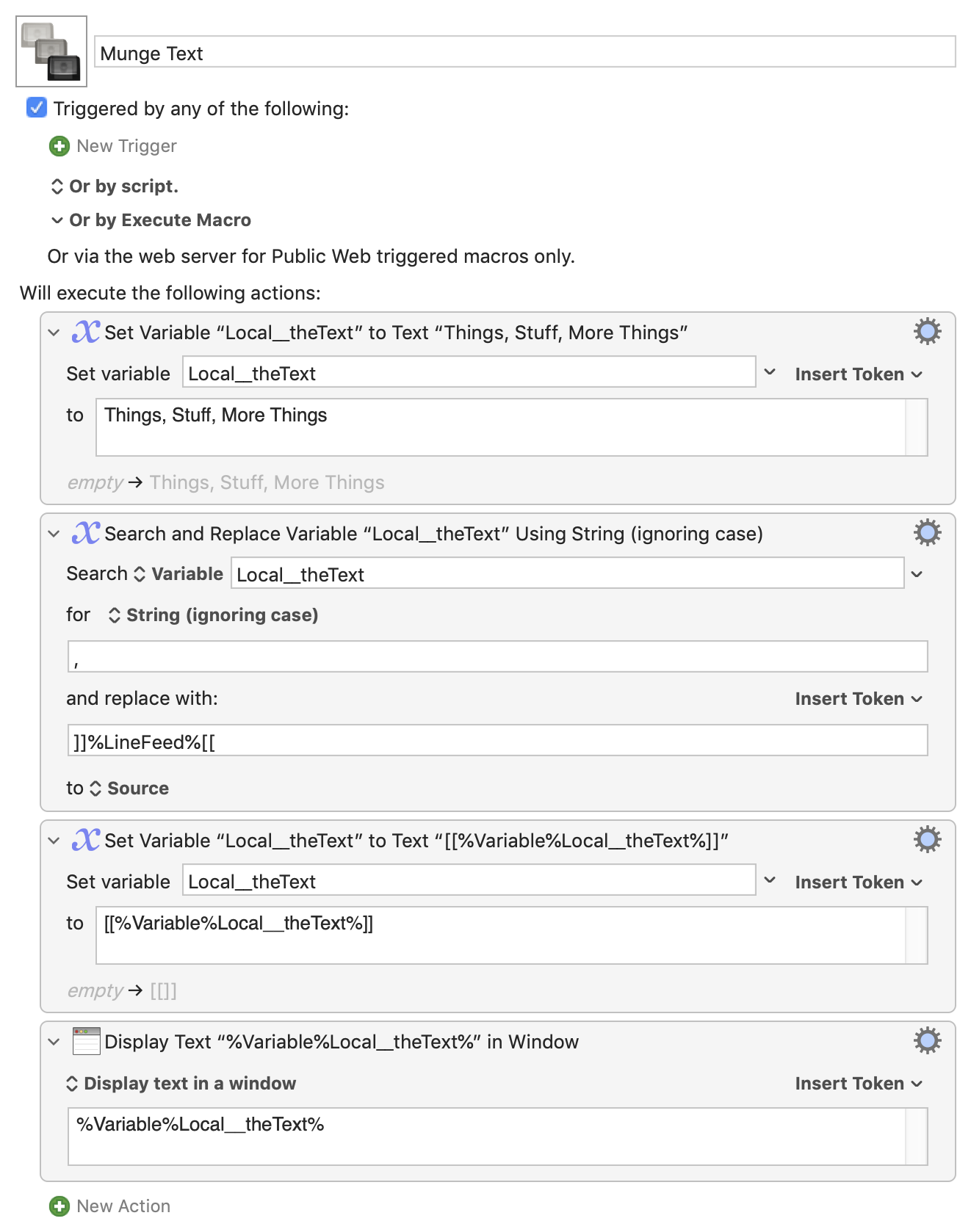
But we can only go by what we're given. And what we've been given in this case is that "the only separator being used is , ".
Of course, if OP was talking to us about this our first questions would be "That's not CSV output from any of the systems you're likely to be using. Where's the input coming from? Are you sure about that separator? Will it always and only be that, will there also be , in any of the strings that we'd need to account for, any other potential gotchas?". And so on.
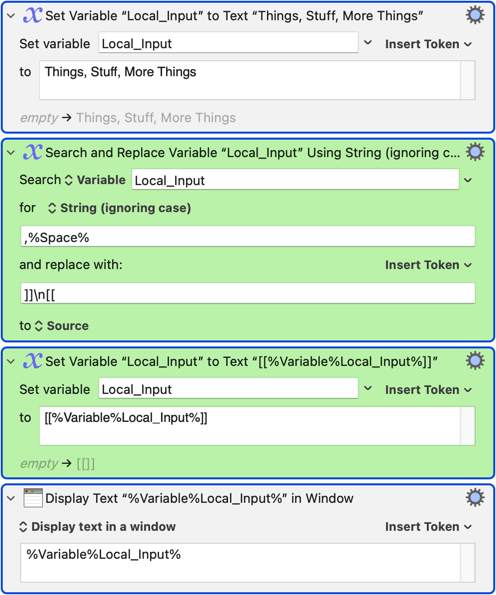
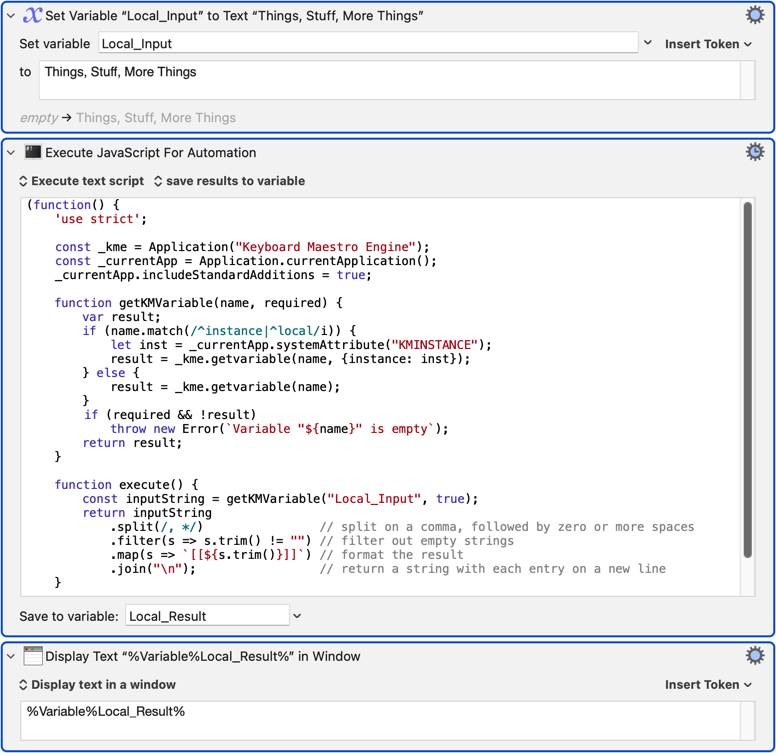
That was my bad -- I should have used the %Space% token in the macro to make that more obvious. That'll bite me when I revisit it next week/month/year!
Yes. And while there's no CSV standard as such, comma-space is "non-standard" enough, and consistently used by OP (albeit, I agree, over a small sample), that we should either take it literally or ask about it -- not assume we can treat it as a "normal" CSV and simply trim spaces.
But -- and here's an assumption, or rather inference, of my own -- I don't think OP is processing CSV or some variant. I think this is text selected in a document and eg being converted into Markdown "internal links" for Obsidian or similar.
Ideally you'd sanitise at data entry -- think form validation, or even autocorrect (which, in OP's case, could ensure that every , is followed by a space). Our Admin team were frequently mis-entering in our HR database, hitting Return or space at the end of a first name for example, so I've put in an auto-calc triggered by field exit that strips any trailing non-alphas.
Otherwise it depends on the "rules" and the "mistakes". So for OP's text you could decide that the "rule" was, indeed, strict comma-separated and that strings couldn't contain Returns or tabs -- they'd be treated as "wrong" separators. So you could S'n'R for one or more Returns and/or tabs, replacing them with a single comma, then replace any space-comma or comma-space with a single comma. But it's more maintainable to clean up your data first then use a simple split than to try and create "one split to rule them all".
All this is, of course, only my opinion -- YMMV