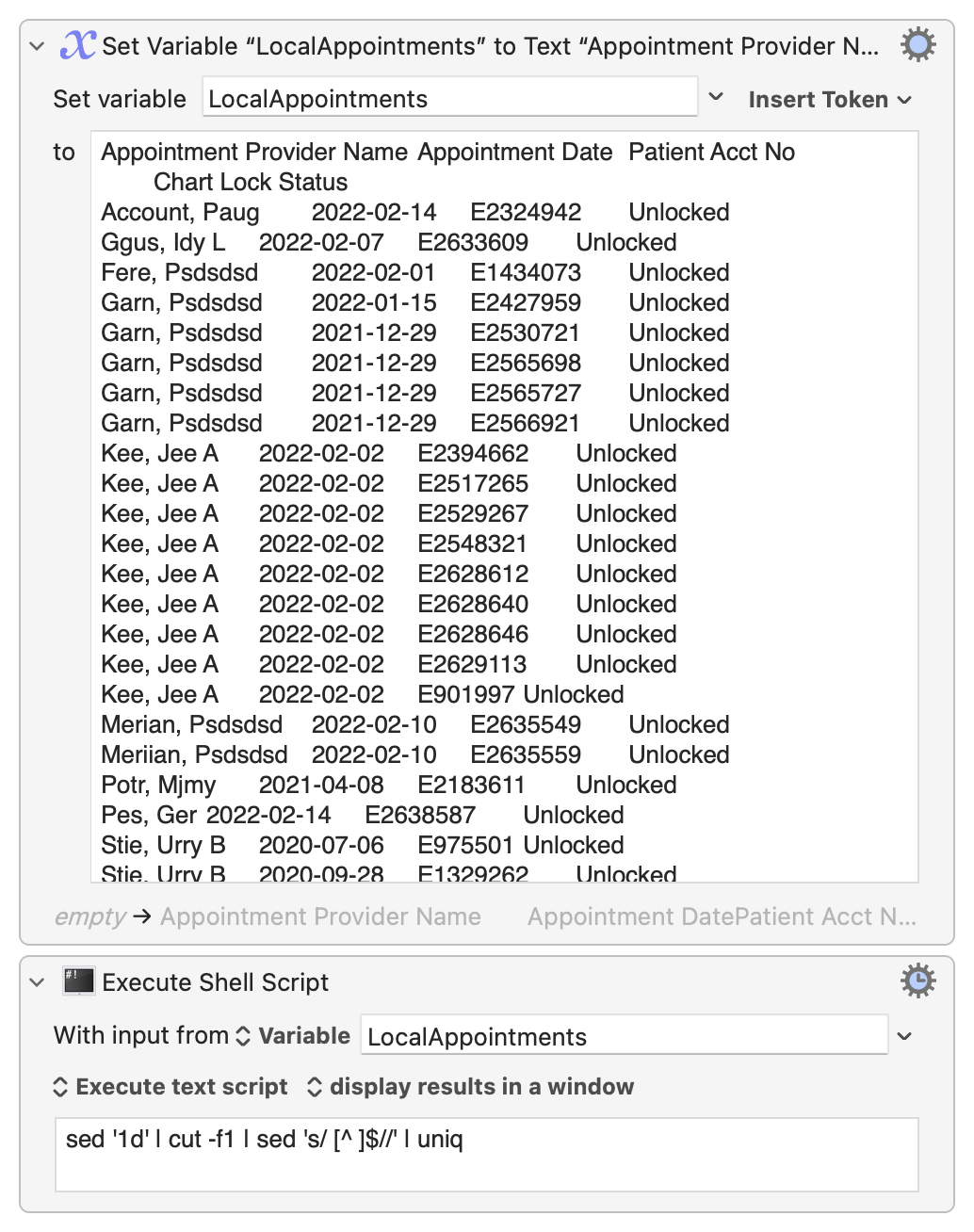
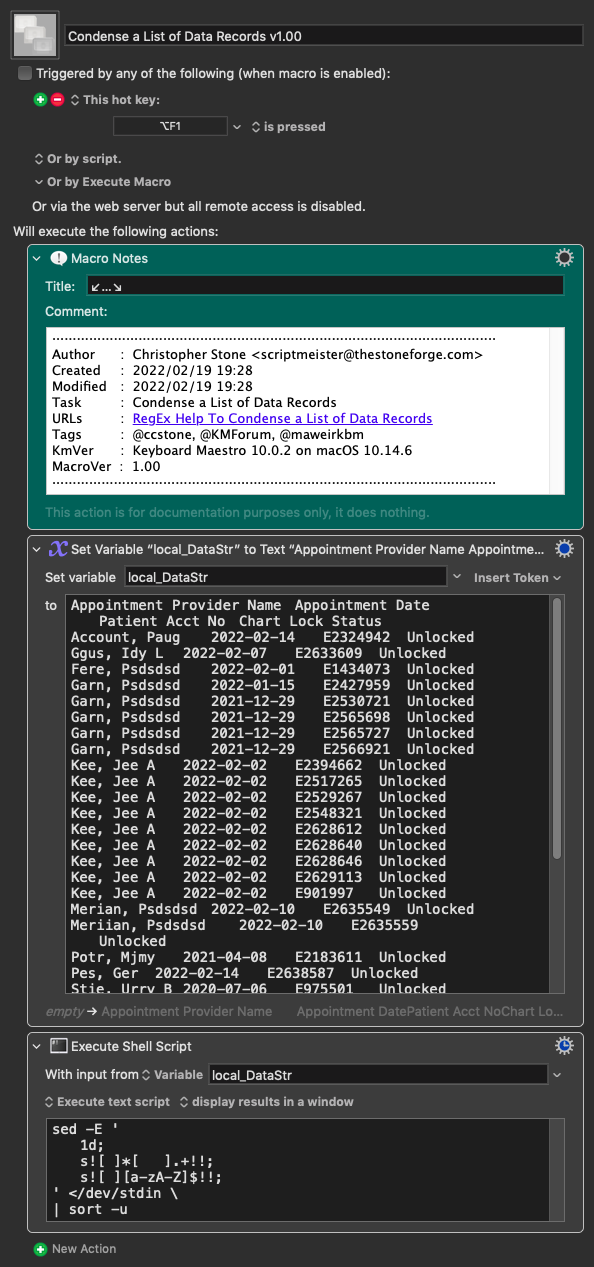
I have a file that contains variations of the data below, the formatting is consistent throughout the file;
Last name
First Name
Middle Initial (if available)
Date
Chart
Status
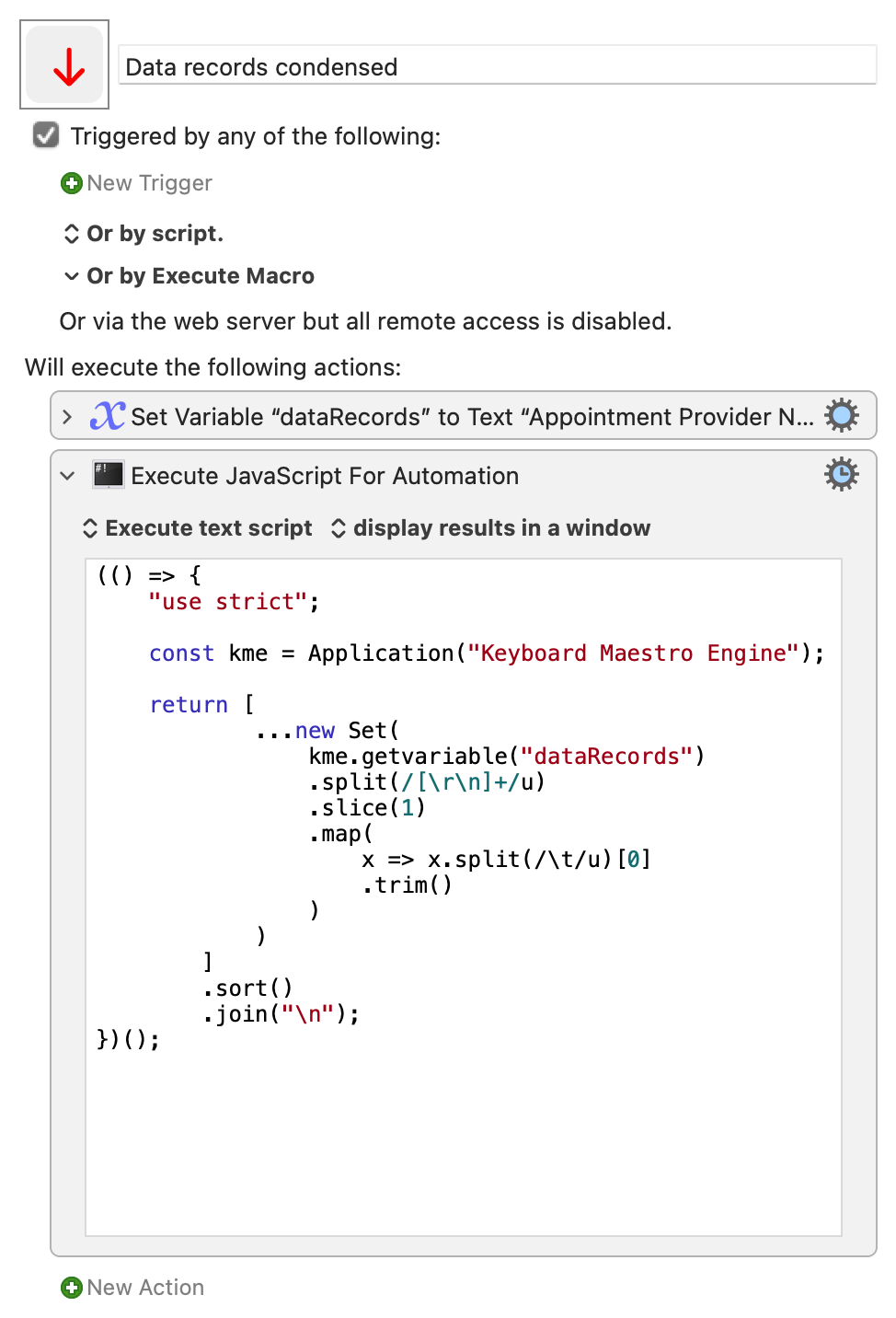
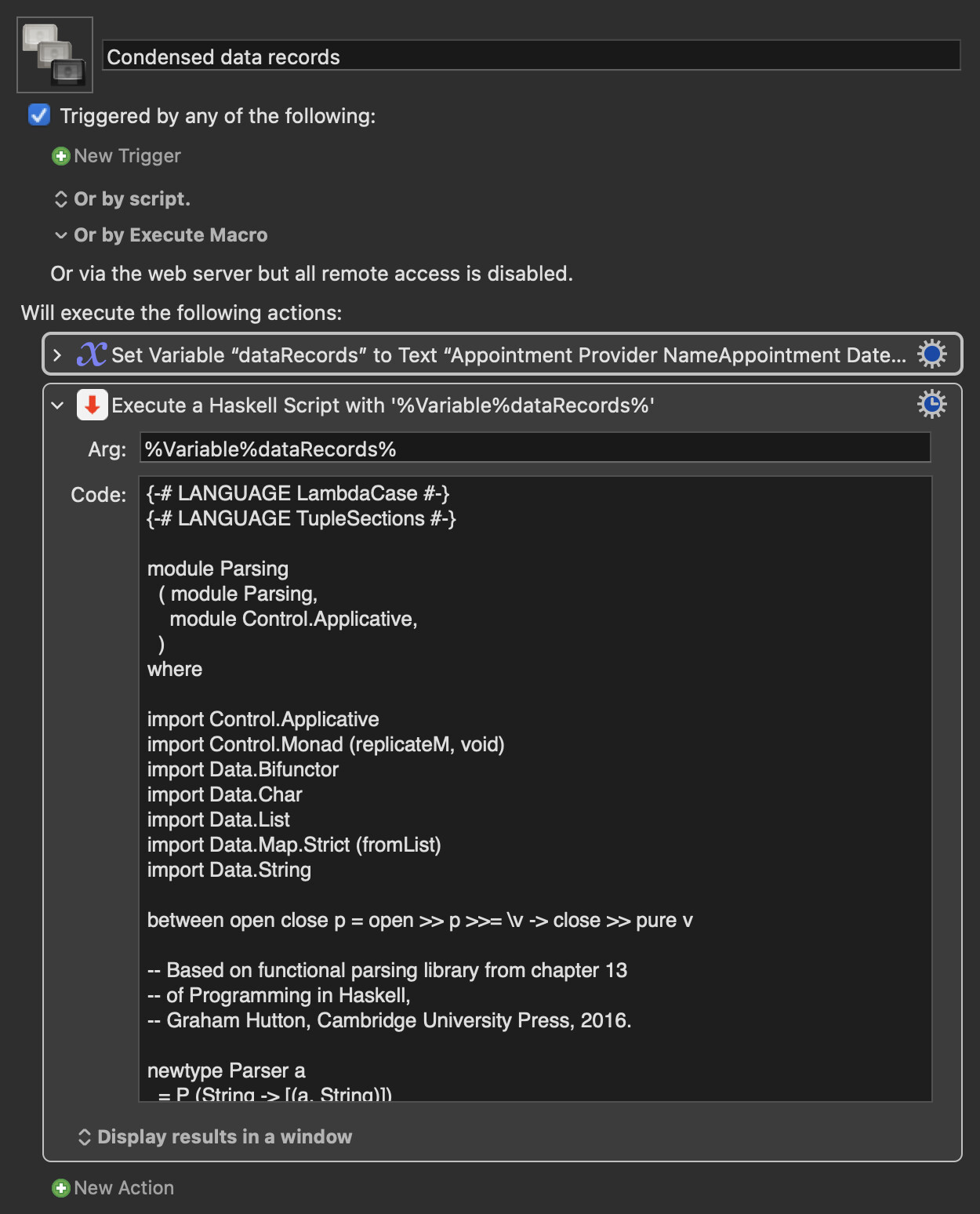
I am looking to ignore the first line and then add the first and last name only, (not middle initial of those that have it (for example "B" is a middle initial of "Stie, Urry B")) of each of the people to a variable. I need to know who is in the list, not how many times they appear in the list
So the new variable using the data below would contain this;
Account, Paug
Ggus, Idy
Fere, Psdsdsd
Garn, Psdsdsd
Kee, Jee
Merian, Psdsdsd
Potr, Mjmy
Pes, Ger
Stie, Urry
Tin, En
lls, eve
I have been trying to do this with RegEx using other posts but am not quite able to figure it out or maybe a better / different way to get the information.
This is where I am so far, so close but yet so far...
(?sm)^([^\t]+?) \t.+?(?:\n(?!\1)|\Z)
Your help is always appreciated!
Sample Data
Appointment Provider Name Appointment Date Patient Acct No Chart Lock Status
Account, Paug 2022-02-14 E2324942 Unlocked
Ggus, Idy L 2022-02-07 E2633609 Unlocked
Fere, Psdsdsd 2022-02-01 E1434073 Unlocked
Garn, Psdsdsd 2022-01-15 E2427959 Unlocked
Garn, Psdsdsd 2021-12-29 E2530721 Unlocked
Garn, Psdsdsd 2021-12-29 E2565698 Unlocked
Garn, Psdsdsd 2021-12-29 E2565727 Unlocked
Garn, Psdsdsd 2021-12-29 E2566921 Unlocked
Kee, Jee A 2022-02-02 E2394662 Unlocked
Kee, Jee A 2022-02-02 E2517265 Unlocked
Kee, Jee A 2022-02-02 E2529267 Unlocked
Kee, Jee A 2022-02-02 E2548321 Unlocked
Kee, Jee A 2022-02-02 E2628612 Unlocked
Kee, Jee A 2022-02-02 E2628640 Unlocked
Kee, Jee A 2022-02-02 E2628646 Unlocked
Kee, Jee A 2022-02-02 E2629113 Unlocked
Kee, Jee A 2022-02-02 E901997 Unlocked
Merian, Psdsdsd 2022-02-10 E2635549 Unlocked
Meriian, Psdsdsd 2022-02-10 E2635559 Unlocked
Potr, Mjmy 2021-04-08 E2183611 Unlocked
Pes, Ger 2022-02-14 E2638587 Unlocked
Stie, Urry B 2020-07-06 E975501 Unlocked
Stie, Urry B 2020-09-28 E1329262 Unlocked
Stie, Urry B 2022-02-14 E2639022 Unlocked
Stie, Urry B 2022-02-14 E2639025 Unlocked
Stie, Urry B 2022-02-14 E2639041 Unlocked
Stie, Urry B 2022-02-14 E883741 Unlocked
Tin, En L 2022-01-19 E1051821 Unlocked
Tin, En L 2022-01-19 E1319091 Unlocked
Tin, En L 2022-01-19 E1319095 Unlocked
Tin, En L 2022-02-02 E2629037 Unlocked
Tin, Enn L 2022-02-02 E2629098 Unlocked
lls, eve 2022-02-03 E1323245 Unlocked
lls, eve 2022-02-03 E2232045 Unlocked