Looks like @gglick has given you a very good solution.
Out of interest in showing/learning RegEx, here's another solution. You will find that there are as many RegEx solutions as there are programmers. There is almost always a trade-off between precision and comprehensiveness of the solution.
My solution is more comprehensive, but could make unwanted matches if the pattern is found in the text you want to keep.
Basically, it deletes all characters on a line prior to, and including:
]: (there's a space at the end)
So this will match any strings at the start of a line like "highlight [page 1]:" or "Underline[133]:",
or even stuff like "just some text and then ]:"
RegEx to Search for:
(?m)^[^\]\n]+\]:[ \t]+
This assumes that this pattern will NOT occur anywhere in the text you want to keep. This solution should be more flexible/comprehensive in that it allows any characters other than "]" and newline "\n" in the text to be deleted. It also allows multiple spaces and/or tabs after the "]:" .
For RegEx Details and Explanation, see:
Here's my test macro:
##example Results
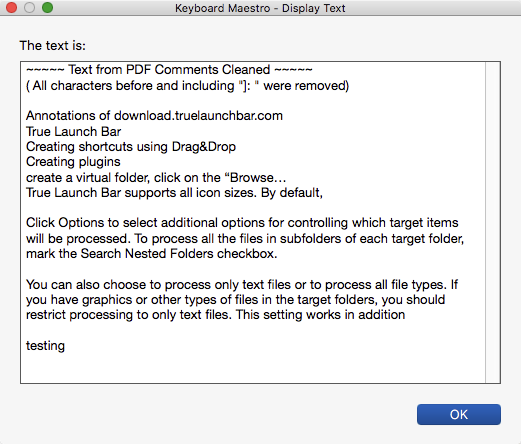
##Macro Library RegEx to Remove PDF Info at Beginning of LIne
####DOWNLOAD:
<a class="attachment" href="/uploads/default/original/2X/b/ba4e00b337dadd7f0e426d7639ecfc6d2910d9f5.kmmacros">RegEx to Remove PDF Info at Beginning of LIne.kmmacros</a> (3.6 KB)
**Note: This Macro was uploaded in a DISABLED state. You must enable before it can be triggered.**
---
<img src="/uploads/default/original/2X/4/450c1a89db6152efdcbc329788dd61aa4da07a98.png" width="459" height="1031">