Agreed, Perl is more powerful. Unix sort needs help when the number of fields vary.
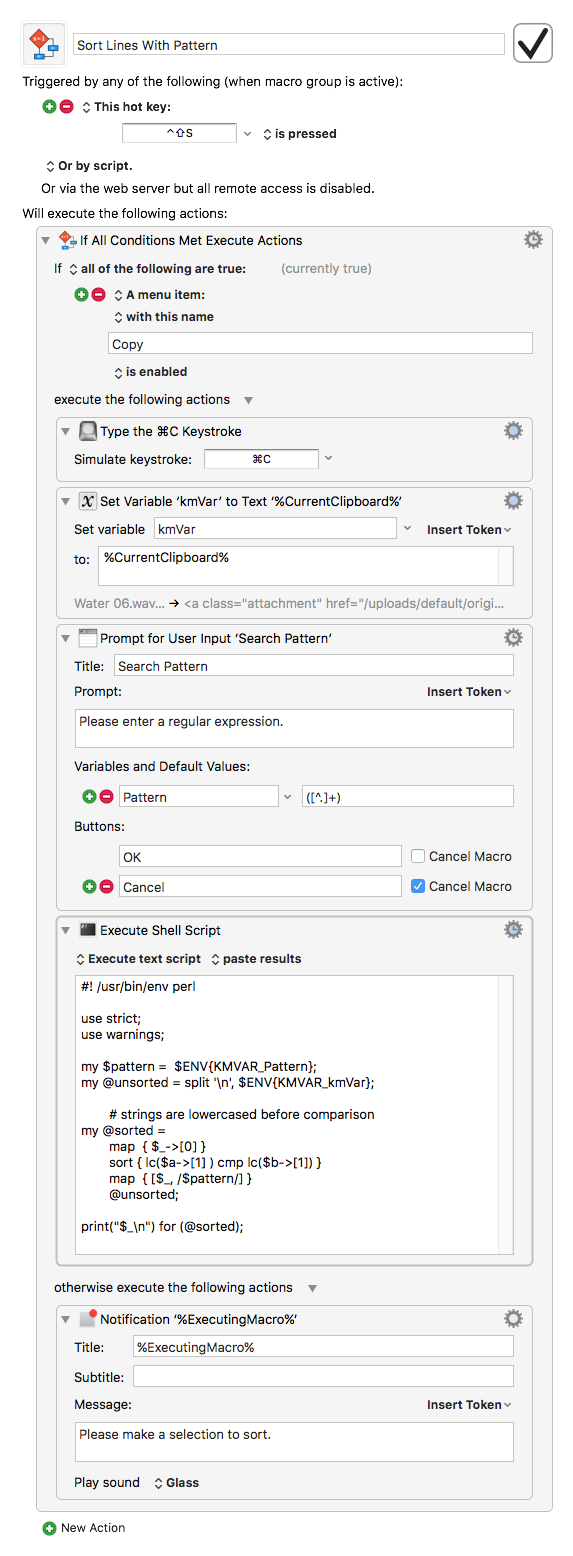
I thought it would be nice to have a sort macro that lets you experiment with the regexp pattern in the Schwartzian Transform. So here it is.
The default pattern is your original ([^.]+) just to have a guide to what's expected. No error checking on the regexp, though.
Sort Lines With Pattern.kmmacros (6.7 KB)