Or, in an 'Execute JavaScript for Automation' action:
(using regexes here, since you expressed curiosity about that, though I would probably reach more quickly for split functions myself)
Note: The higher-order mappendComparing function supports n-ary sorts by deriving a comparator function from a list of property-getting functions.
Sorted filenames.kmmacros (19.9 KB)
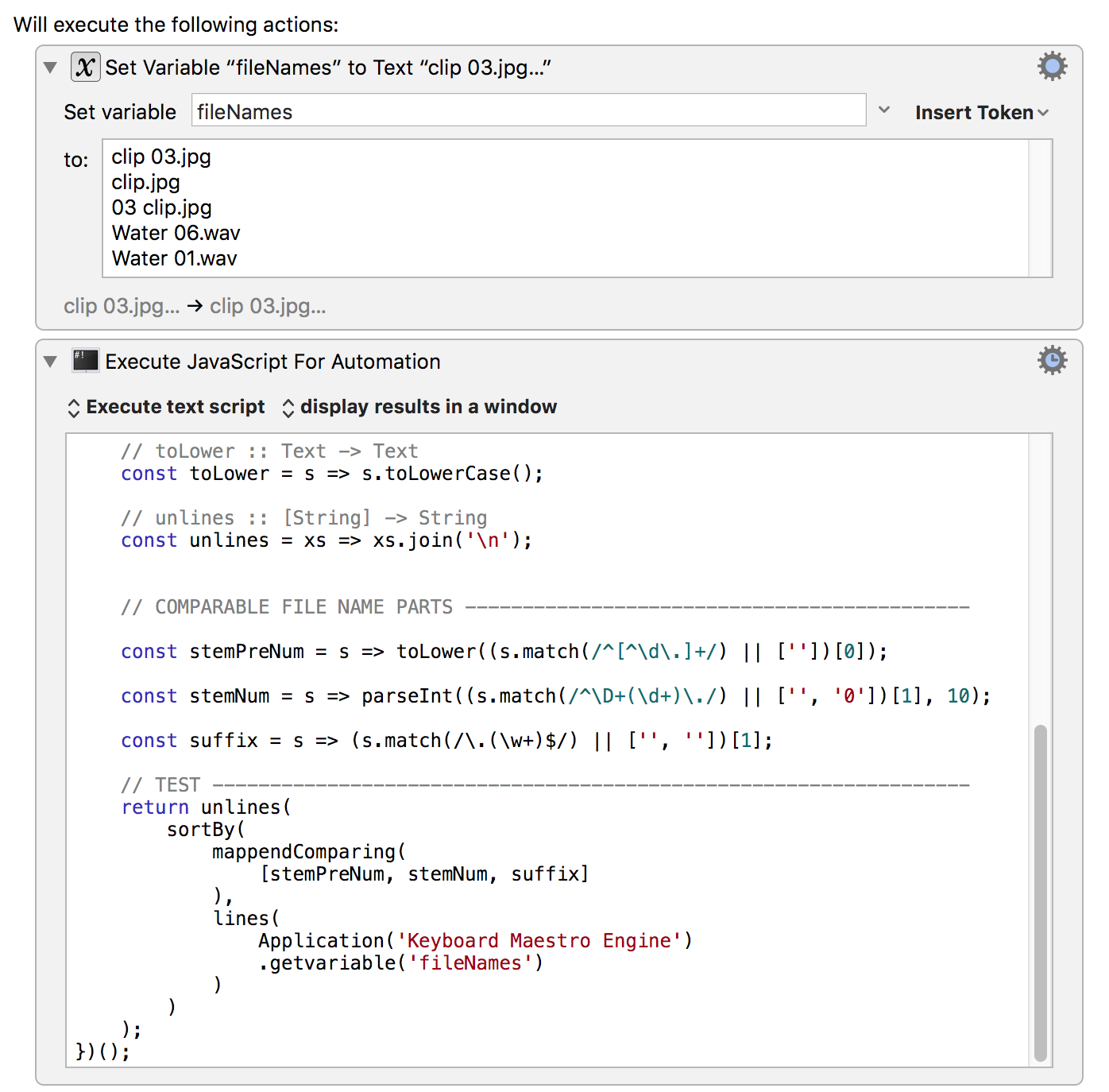
Full source of the Execute JS4A action
(ES6 JavaScript, so Sierra onwards – for [Yosemite onwards] ES5 JS, past into the Babel JS repl at https://babeljs.io/repl/)
(() => {
'use strict';
// GENERIC FUNCTIONS -----------------------------------------------------
// lines :: String -> [String]
const lines = s => s.split(/[\r\n]/);
// mappendComparing :: [(a -> b)] -> (a -> a -> Ordering)
const mappendComparing = fs => (x, y) =>
fs.reduce((ord, f) => (ord !== 0) ? (
ord
) : (() => {
const
a = f(x),
b = f(y);
return a < b ? -1 : a > b ? 1 : 0
})(), 0);
// sortBy :: (a -> a -> Ordering) -> [a] -> [a]
const sortBy = (f, xs) =>
xs.slice()
.sort(f);
// toLower :: Text -> Text
const toLower = s => s.toLowerCase();
// unlines :: [String] -> String
const unlines = xs => xs.join('\n');
// COMPARABLE FILE NAME PARTS --------------------------------------------
const stemPreNum = s => toLower((s.match(/^[^\d\.]+/) || [''])[0]);
const stemNum = s => parseInt((s.match(/^\D+(\d+)\./) || ['', '0'])[1], 10);
const suffix = s => (s.match(/\.(\w+)$/) || ['', ''])[1];
// TEST ------------------------------------------------------------------
return unlines(
sortBy(
mappendComparing(
[stemPreNum, stemNum, suffix]
),
lines(
Application('Keyboard Maestro Engine')
.getvariable('fileNames')
)
)
);
})();