Hello,
Would there be a way to create a macro which would chop up a text into approx 400 word segments, separated by something like this: ----------------------------------
thanks very much
Hello Chris !
Thank you for taking the time to read and comment on my post.
I apologize for not having included a sample text and most importantly a rationale.
Rationale: translation web sites (google translate) will translate texts for free, but only for a limited number of characters. Above that limit, an expensive subscription (USD 250+/year) is required.
My objective is chop up texts into for example 4,000 character sections. If that is possible, it is only a question of writing a macro to process (ie translate) each section in turn. Please note that the translation site counts characters, not words.
This is for personal, not professional use.
This is the text before and after running the chop macro:
in this example,I chose to chop up the text in 500 character sections separated by **
1----------------------------------
** please note that the the number at the beginning of the line is incremental.
I am obviously not doing this to translate only one text (which I can do manually). It is something that I would use everyday.
thanks very much for your time and thoughts.
Before running the KBM chop macro, the text looks like this:
The Indian city of Gurugram, which in Hindi means “village of the guru,” is a technology-and-business hub twenty miles south of New Delhi, reached by highways filled with auto-rickshaws, exhaust-spewing buses, and the occasional immovable cow. The city’s glass high-rises contain dozens of multinational corporations, including Pepsi, Google, and Microsoft. On a recent morning, a white S.U.V. pulled up in front of the building housing the largest Indian office of the ride-hailing company Uber, and out climbed Dara Khosrowshahi, the company’s new C.E.O.
In Uber’s minimalist lobby, Khosrowshahi was greeted by two local staff members, who led him through a traditional Hindu lamplighting ceremony called an aarti. The ceremony, which banishes negativity and invites in light and optimism, is intended to mark an auspicious beginning. Khosrowshahi smiled as he lit ghee-soaked wicks on a bronze lamp surrounded by rose and dahlia petals. A female Uber employee dabbed a red tilak dot on his forehead and handed him a bouquet of flowers. In a black blazer, white dress shirt, and slim-fitting jeans, he looked like a corporate executive who had just escaped from a New Age retreat.
A few minutes later, Khosrowshahi was ushered into the cafeteria to meet with a group of Uber’s India-based employees. He seemed weary. He had been in India a little more than twenty-four hours, and had flown in directly from a two-day trip to Japan, where he visited Toyota plants and lobbied government officials to let Uber expand in the country. Although Uber is losing money in India, it is growing rapidly, and Khosrowshahi’s frenetic schedule involved numerous meetings with Indian politicians and regulators, including one that evening with the Prime Minister, Narendra Modi. Local policy experts had been briefing Khosrowshahi on his talking points. He was advised to refer to Uber’s drivers as “micro-entrepreneurs”—a term that, as Uber India’s chief business officer put it, “warms a politician’s heart.”
After running the KBM macro which would chop up the text in 500 character increments
The Indian city of Gurugram, which in Hindi means “village of the guru,” is a technology-and-business hub twenty miles south of New Delhi, reached by highways filled with auto-rickshaws, exhaust-spewing buses, and the occasional immovable cow. The city’s glass high-rises contain dozens of multinational corporations, including Pepsi, Google, and Microsoft. On a recent morning, a white S.U.V. pulled up in front of the building housing the largest Indian office of the ride-hailing company Uber, and
1----------------------------------
out climbed Dara Khosrowshahi, the company’s new C.E.O.
In Uber’s minimalist lobby, Khosrowshahi was greeted by two local staff members, who led him through a traditional Hindu lamplighting ceremony called an aarti. The ceremony, which banishes negativity and invites in light and optimism, is intended to mark an auspicious beginning. Khosrowshahi smiled as he lit ghee-soaked wicks on a bronze lamp surrounded by rose and dahlia petals. A female Uber employee dabbed
2----------------------------------
a red tilak dot on his forehead and handed him a bouquet of flowers. In a black blazer, white dress shirt, and slim-fitting jeans, he looked like a corporate executive who had just escaped from a New Age retreat.
A few minutes later, Khosrowshahi was ushered into the cafeteria to meet with a group of Uber’s India-based employees. He seemed weary. He had been in India a little more than twenty-four hours, and had flown in directly from a two-day trip to Japan, where he visited
3----------------------------------
Toyota plants and lobbied government officials to let Uber expand in the country. Although Uber is losing money in India, it is growing rapidly, and Khosrowshahi’s frenetic schedule involved numerous meetings with Indian politicians and regulators, including one that evening with the Prime Minister, Narendra Modi.
4----------------------------------
Local policy experts had been briefing Khosrowshahi on his talking points. He was advised to refer to Uber’s drivers as “micro-entrepreneurs”—a term that, as Uber India’s chief business officer put it, “warms a politician’s heart.”
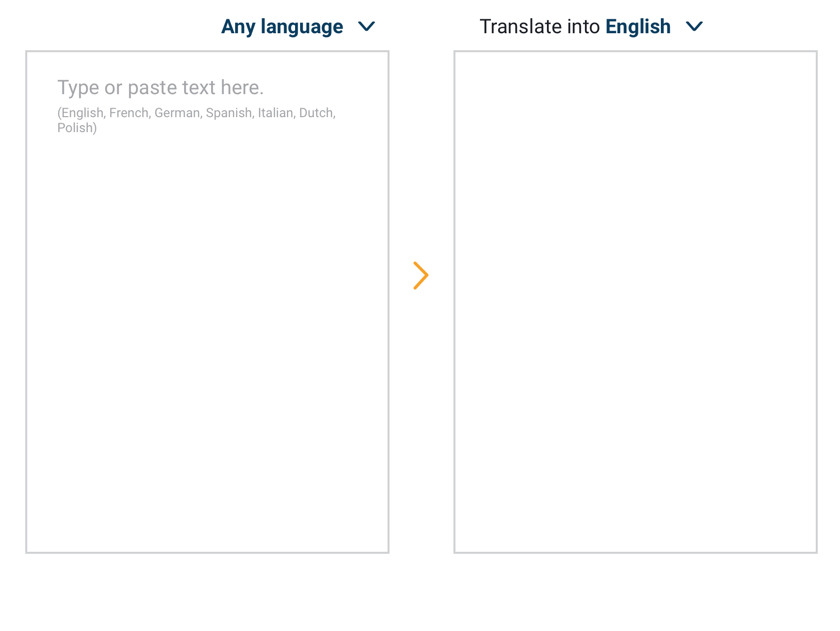
This is what the translation web site looks like:
One issue with that spec is that if you cut across sentence boundaries, the translation software will inevitably produce junk for each semi-sentence at the start and/or end of a chunk.
Unless translation quality is not a goal, you probably need to adjust your spec so that segmentation occurs at the last sentence boundary before the word count reaches a given ceiling.
2 Likes
yes, you are right. If fact, I had observed that when I tested.
It’s somewhat of a pain. Just creates manual translation work for borderzone sentences.
I assumed that looking for the end of a sentence would be too complex and that’s why I did not address the issue. I was perhaps wrong to assume that.
Perhaps simpler to use end of paragraph mark?
You need, of course, to be confident that your units of segmentation will always be shorter than your character-count ceiling.
Paragraph segmentation could be better for translation quality (depending on the statistical approach being used by the translation software) but will clearly be more risky in terms of exceeding chunk length.
In practice you might need to have preferred and fall-back segmentations (e.g. paragraph, falling back to sentence where necessary).
(Searching for a period followed by white-space should allow for adequate division into sentences)
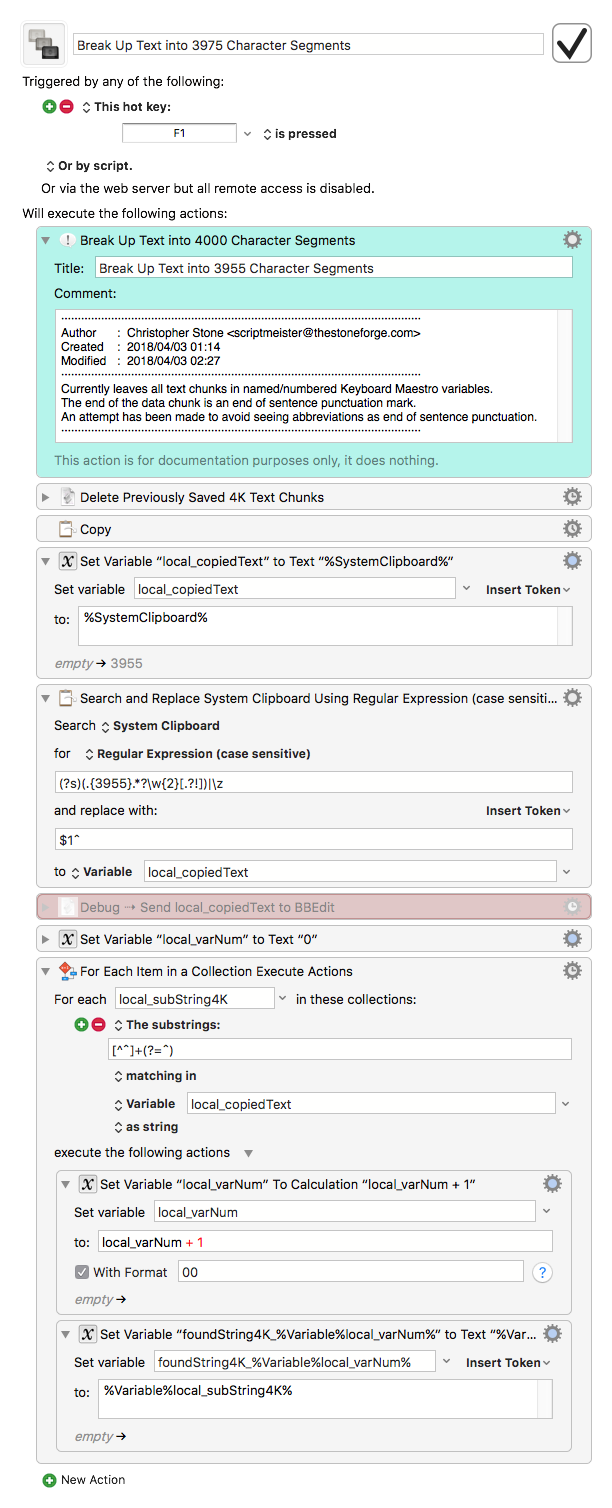
Hey @ronald,
This macro will break up your data into approximately 3975 character data chunks – approximate because the chunk must end with a sentence punctuation mark to cater to your translator site's needs.
- Make a selection in the front application.
- Run the macro
- Text is copied.
- Text is parsed into chunks and placed in named/numbered Keyboard Maestro variables.
Break Up Text into 3975 Character Segments.kmmacros (9.6 KB)
You now have a working proof-of-concept parser. It's up to you to get the data into your translation site.
I've made some effort to prevent the parser from stopping within abbreviations.
I've done nothing to manage end-of-sentence quoting.
The job was much easier to do using AppleScript and the Satimage.osax AppleScript Extension.
NOTE – REQUIRES that the Satimage.osax be installed!
----------------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2018/04/03 03:00
# dMod: 2018/04/03 03:09
# Appl: Satimage.osax and Keyboard Maestro Engine
# Task: Break textual data in to ~ 4K chunks for use in a tranlation web page.
# Libs: None
# Osax: Satimage.osax -- http://tinyurl.com/satimage-osaxen
# Tags: @ccstone, @Applescript, @Script, @Satimage.osax, @Keyboard_Maestro_Engine, @Break, @Textual, @Chunks, @Tranlation, @Web, @Page
----------------------------------------------------------------
set dataStr to the clipboard
set foundDataList to change "(?m)(.{3955}.*?\\w{2}[.?!])" into "\\1ˆ" in dataStr with regexp
set foundDataList to splittext foundDataList using "ˆ"
set baseVarName to "dataChunk4K_"
tell application "Keyboard Maestro Engine"
repeat with i from 1 to length of foundDataList
setvariable (baseVarName & (format i into "00")) to item i of foundDataList
end repeat
end tell
----------------------------------------------------------------
Here's virtually the same script using only Keyboard Maestro functions and vanilla AppleScript (thanks to Peter adding to Keyboard Maestro's dictionary in v8).
----------------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2018/04/03 03:00
# dMod: 2018/04/03 03:09
# Appl: Keyboard Maestro Engine
# Task: Break textual data in to ~ 4K chunks for use in a tranlation web page.
# Libs: None
# Osax: None
# Tags: @ccstone, @Applescript, @Script, @Keyboard_Maestro_Engine, @Break, @Textual, @Chunks, @Tranlation, @Web, @Page
----------------------------------------------------------------
set dataStr to the clipboard
set baseVarName to "dataChunk4K_"
set AppleScript's text item delimiters to {"ˆ"}
tell application "Keyboard Maestro Engine"
set foundDataList to search dataStr for "(?s)(.{3955}.*?\\w{2}[.?!])" replace "$1ˆ" with regex
set foundDataList to text items of foundDataList
repeat with i from 1 to length of foundDataList
setvariable (baseVarName & (format i into "00")) to item i of foundDataList
end repeat
end tell
----------------------------------------------------------------
I suspect this task will be quite easy to do with JavaScript as well and look forward to seeing @ComplexPoint's take.
-Chris
5 Likes
If we strip it down to the most naive model, in which a text is just a sequence of sentences (forgetting paragraphs for the moment), then one approach might look like:
// textChunks :: Int -> String -> [String]
const textChunks = (intMax, strText) => {
const dct = sentences(strText).reduce(
(a, x) => {
const intChars = a.size + x.length + 1;
return intChars > intMax ? {
size: x.length,
acc: [x],
chunks: a.chunks.concat([a.acc])
} : {
size: intChars,
acc: a.acc.concat(x),
chunks: a.chunks
}
}, {
size: 0,
acc: [],
chunks: []
}
);
return dct.chunks.concat([dct.acc])
.map(xs => xs.join(' '));
};
So, for example:
yielding:
1-------------
The Indian city of Gurugram, which in Hindi means “village of the guru,” is a technology-and-business hub twenty miles south of New Delhi, reached by highways filled with auto-rickshaws, exhaust-spewing buses, and the occasional immovable cow. The city’s glass high-rises contain dozens of multinational corporations, including Pepsi, Google, and Microsoft.
2-------------
On a recent morning, a white S.U.V. pulled up in front of the building housing the largest Indian office of the ride-hailing company Uber, and out climbed Dara Khosrowshahi, the company’s new C.E.O. In Uber’s minimalist lobby, Khosrowshahi was greeted by two local staff members, who led him through a traditional Hindu lamplighting ceremony called an aarti.
3-------------
The ceremony, which banishes negativity and invites in light and optimism, is intended to mark an auspicious beginning. Khosrowshahi smiled as he lit ghee-soaked wicks on a bronze lamp surrounded by rose and dahlia petals. A female Uber employee dabbed a red tilak dot on his forehead and handed him a bouquet of flowers.
4-------------
In a black blazer, white dress shirt, and slim-fitting jeans, he looked like a corporate executive who had just escaped from a New Age retreat. A few minutes later, Khosrowshahi was ushered into the cafeteria to meet with a group of Uber’s India-based employees. He seemed weary.
5-------------
He had been in India a little more than twenty-four hours, and had flown in directly from a two-day trip to Japan, where he visited Toyota plants and lobbied government officials to let Uber expand in the country.
6-------------
Although Uber is losing money in India, it is growing rapidly, and Khosrowshahi’s frenetic schedule involved numerous meetings with Indian politicians and regulators, including one that evening with the Prime Minister, Narendra Modi. Local policy experts had been briefing Khosrowshahi on his talking points.
7-------------
He was advised to refer to Uber’s drivers as “micro-entrepreneurs”—a term that, as Uber India’s chief business officer put it, “warms a politician’s heart.”.
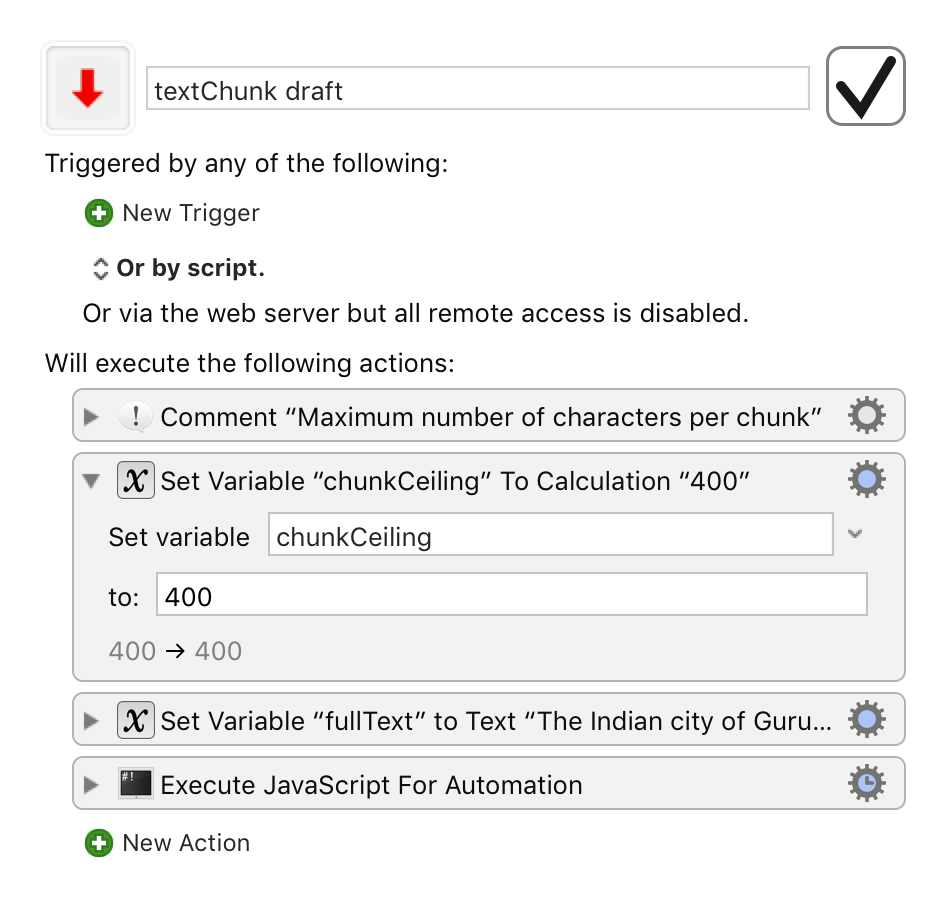
with chunkCeiling set at 400
(full source of draft JS):
(() => {
'use strict';
const main = () => textChunks(
parseInt(kmVar('chunkCeiling'), 10),
kmVar('fullText')
).map(
(x, i) => (i + 1).toString() +
'-------------' + '\n' + x
).join('\n');
// TEXT CHUNKS -------------------------------------------------------------
// textChunks :: Int -> String -> [String]
const textChunks = (intMax, strText) => {
const dct = sentences(strText).reduce(
(a, x) => {
const intChars = a.size + x.length + 1;
return intChars > intMax ? {
size: x.length,
acc: [x],
chunks: a.chunks.concat([a.acc])
} : {
size: intChars,
acc: a.acc.concat(x),
chunks: a.chunks
}
}, {
size: 0,
acc: [],
chunks: []
}
);
return dct.chunks.concat([dct.acc])
.map(xs => xs.join(' '));
};
// sentences :: String -> [String]
const sentences = s =>
// Split on period and space(s) before capital.
s.split(/\.\s+(?=[A-Z])/).map(x => x + '.');
// KM ----------------------------------------------------------------------
const kmVar = Application('Keyboard Maestro Engine')
.getvariable;
// MAIN --------------------------------------------------------------------
return main();
})();
I greatly appreciate your help. I am sorry but I am over my head.
If you have the patience:
1- where is the apple script in the macro itself ?
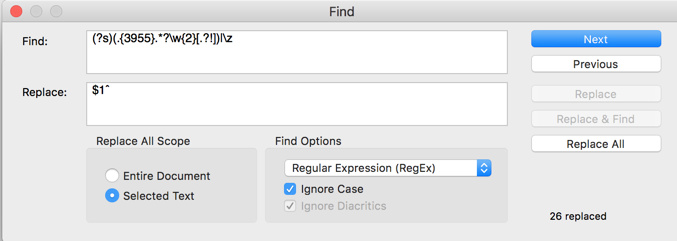
2- if I ran the following regular expression search / replace, what happens (I tried and don't notice any change):
Hey @ronald,
There is no functional AppleScript in the Keyboard Maestro macro. I used only KM-native actions, although there is an AppleScript in the debug action to send the text from the previous action to BBEdit. It's disabled, and won't work if you don't have BBEdit.
Find:
(?s)(.{3955}.*?\w{2}[.?!])|\z
Replace:
$1ˆ
This will be hard to see with the naked eye.
I've emplaced a ˆ after every 3955 characters plus the end of a sentence.
The character is the circumflex accent character. It's a Unicode character unlikely to be in any given text, so I use it for parsing.
Once I've emplaced the character I'm able to use it to easily split the text.
Look in the Keyboard Maestro variables panel of its preferences to see the variables created with the macro.
By the way – what app are you using for your find/replace (that you show with the image)?
It may or may not support the dollar sign character for captures. It may require a backslash instead.
\1ˆ
-Chris
1 Like
Thank you Chris.
I am using Scrivener 3.
If I do only a search and replace, it now works with the backslash.
I am unable to make the macro work.
It is too difficult for me to understand: I will read up on KBM variables as you suggested.
thanks very much for writing the macro and your suggestions.
Hey @ronald,
All you have to do is select a quantity of text in the front application and run the Break Up Text into 3955 Character Segments macro.
That's all you have to do.
Then look in the variables pane of the Keyboard Maestro preferences.
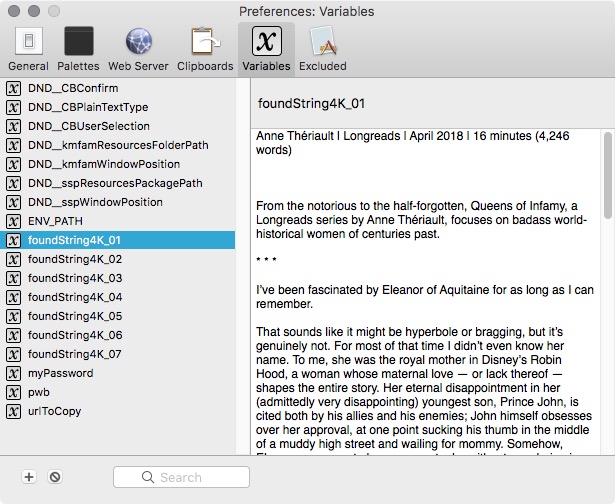
As you can see there are sequential variables with the name foundString4K_##.
Once you've got this working we'll do something about getting the chunks of text into your translator webpage.
-Chris
1 Like
Fantastic. Now I understand and it works. Thank you Chris.
It works when I copy a web article into a word processor (Scrivener 3), but not if I highlight in the web page directly. Not a problem.
Now I see each chunk of text in each variable.
I now want to process each variable through the translator web page.
The processing part I can I think figure out.
Where is get difficult is both to process each chunk and at the same time compile the final document.
Let’s assume there are 3 chunks in 3 variables Var1,2 and 3 and let’s assume that the final document which can be anywhere but BBEdit is perhaps a practical choice.
I would somehow call up var 1 ➜ send to the clipboard ➜ copy it into the final document AND ➜ paste and process through the translator ➜ copy the translation to the clipboard ➜ open the final document ➜ create something like ➜ 1---------------------------------- (where 1 is incremental) ➜ paste/append the translation ➜ repeat with variable 2, etc
thanks again
Hey @Ronald,
It should work when copying text from your web browser. I composed the macro by working with Safari.
What browser are you using?
Give me an example of a page that doesn’t work.
I'll look at the rest of your post here in a bit.
-Chris
1 Like
my apologies: it does work from Chrome. The problem was limited to one newspaper site for strange but irrelevant reasons.
thanks again