One of the problems that I deal with that causes me to write hundreds of lines of code is to correct imported typed (or OCR'd) data that KM has to fix to interpret correctly. This is a fact of my life and this week I created a fabulous new way to solve it. It's a single macro that uses an innovative new technique to compare strings for an approximate match and pick the string that most closely matches. Here's how I might call it: (1) set up a variable containing the possibly erroneous string, (2) pass the name of the variable and the permissible values as the parameter; (3) use the variable for any purpose which has been updated to match one of the permissible values.
The macro is attached in a link below. (I finally got a grip on how to upload macros. Yay me.) The next screenshot is just an example of how to call the macro.
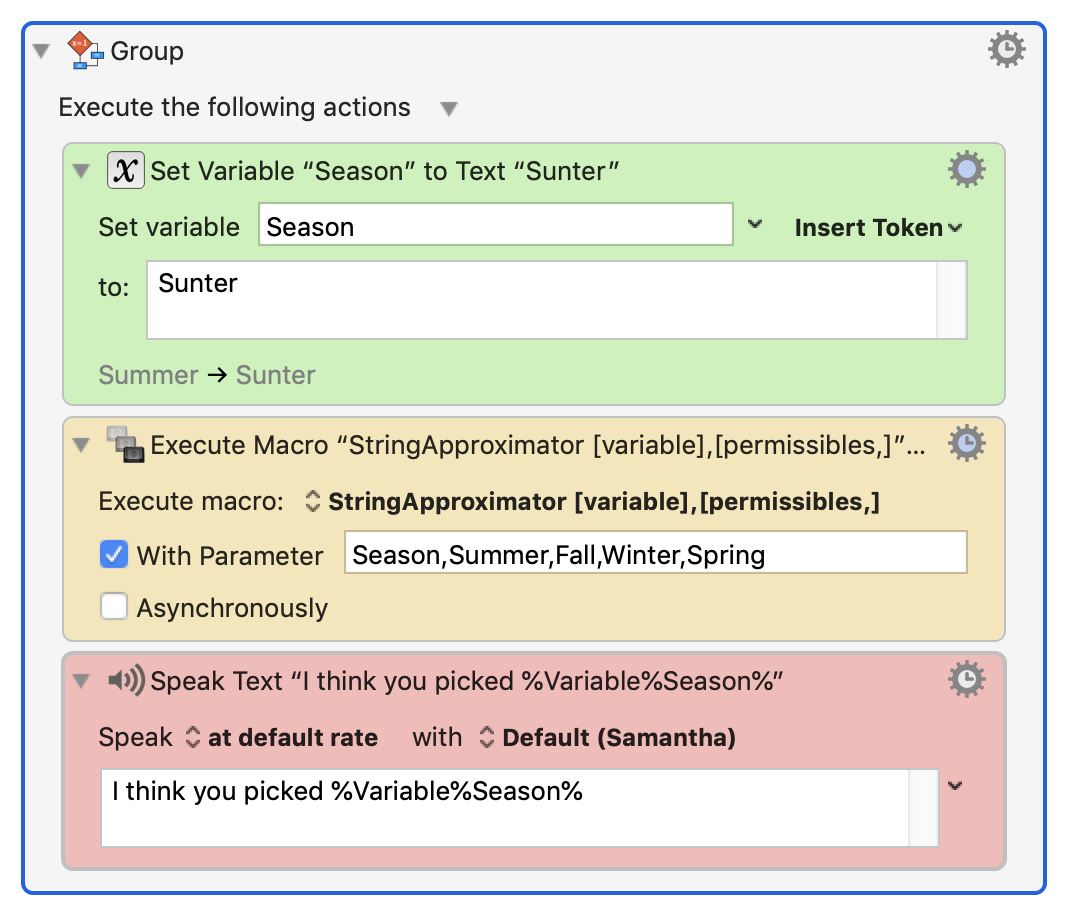
The implementation is basically to sort the letters of each string parameter, find the intersection of the letters between the candidate string and the permissible strings using a simple UNIX tool, then choosing the candidate with the lowest mismatch value. Quite short and elegant. Seems to work perfectly. Last year I submitted an algorithm that was far more complicated. This algorithm feels simpler and quite optimal.
Keyboard Maestro 8.2.4 Actions
Keyboard Maestro Actions.kmactions (8.7 KB)
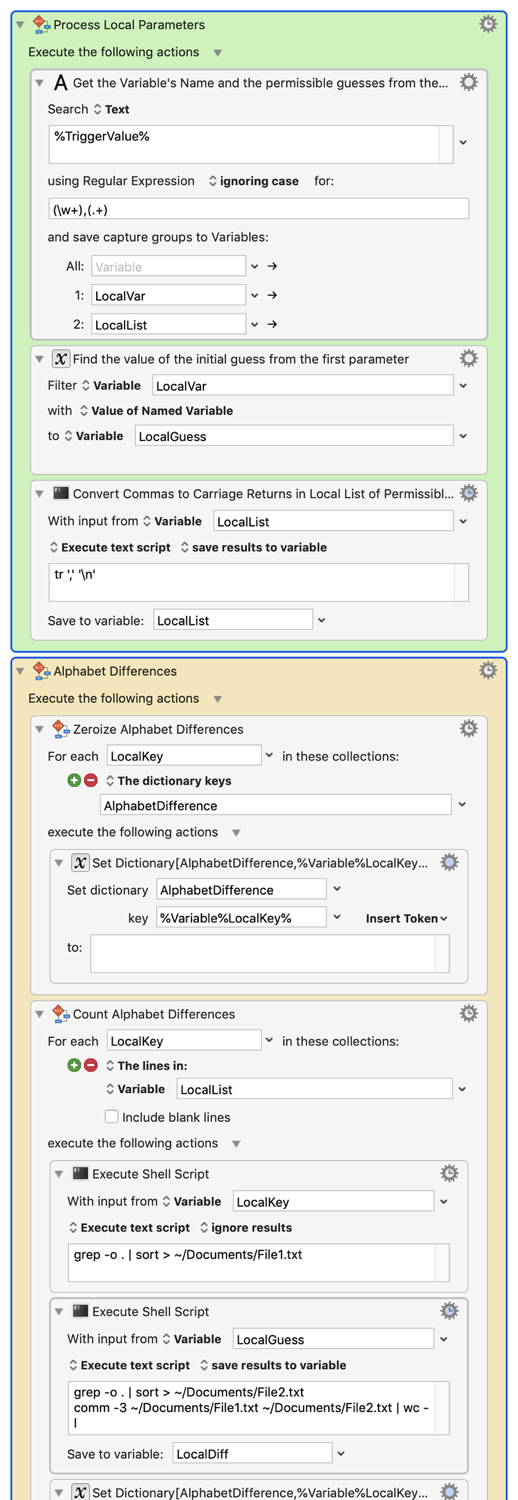
For those of you who are eagle-eyed, you may notice that I use ^2 at one point in my algorithm. That's harmless but superfluous. It used to be useful because I had multiple measurements and the ^2 was needed to scale the measurements to the same metric, but I've stripped out that code so you can strip out the ^2 if you wish.
I suppose I could have used a list of text lines instead of a dictionary to take the measurements, but I'm finally getting a grip on Dictionaries and I try to use them whenever I can. If you feel you want to replace it with a simpler data structure, go ahead.