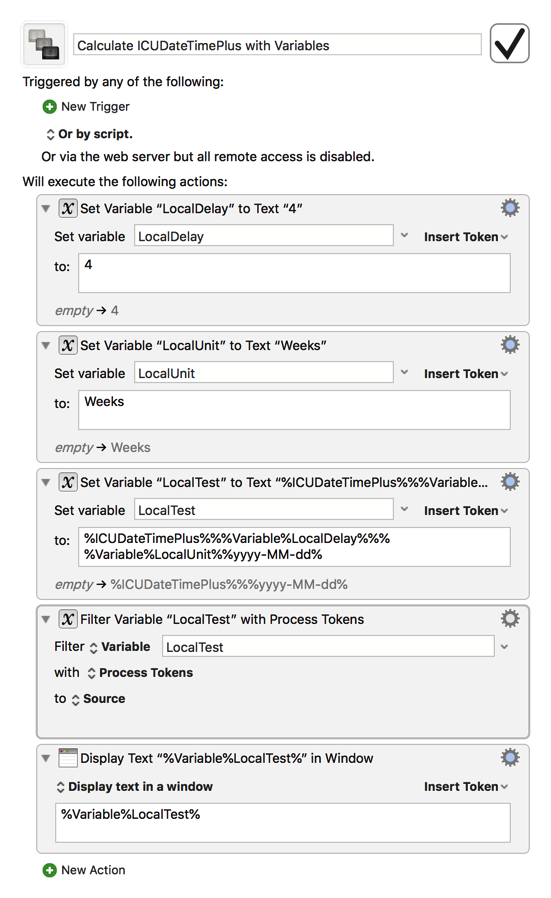
Also, it seems like you might be leaving out a crucial operand between the Delay and Unit variables; as-is, you’ll only end up with their respective numbers side by side, which would lead to their being interpreted as a new and different number (i.e. if Delay is 2 and Units is 18, including them as just %Variable%Delay%%Variable%Unit% will result in 218), which I’m guessing isn’t what you want, so you’ll probably want to include a * or / between them as appropriate for what you’re trying to accomplish.
Expands to %ICUDateTimePlus%4%Weeks%yyyy-MM-dd% during the "Set Variable" step, so from there, we just need to process its now properly-formatted tokens with the filter action, giving us 2018-05-17.
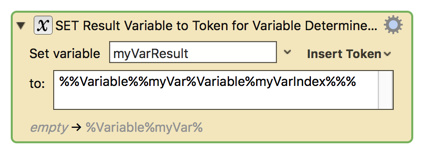
It is working, but only because you are confusing the parser just the right amount. You should double all the percent characters you do not want expanded, so something like:
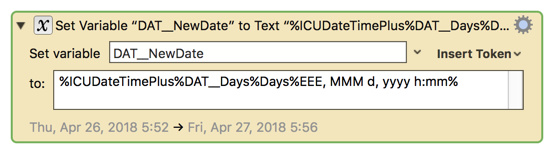
where "DAT_Days" is a KM Variable, used for the amount parameter.
but this fails:
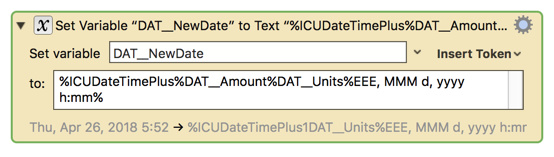
where the only real difference is I used a KM Variable, "DAT__Units", instead of the "Days" hard-coded unit. Why?
If we can use a KM Variable for the amount parameter, then logic dictates that we should be able to use one for the units parameter. Should this be changed?
IAC, we need to update the KM Wiki to make it clear and correct.
That is fine because the section between the second and third percent (DAT__Days ) is a calculation field, so there is no problem using a variable there. And indeed @gglick’s version could be simplified to:
The section between the third and fourth percent (Days) is plain text, there is no processing done on it. This is the part of the OP’s issue ("Accepting input for … units in ICUDateTimePlus") that requires jumping through hoops.
Because tokens can contain calculations (which generally do not include % characters), but tokens cannot contain tokens (which do contain percent characters and therefore make the parser impossible).
Logic only dictates that if you consider numeric fields and text fields interchangeable, which they are not.
The wiki is clear and correct I believe. If you want to add this extra case of being able to specify the units, that might be worthwhile, although it seems an extreme case - generally you can just use the smallest unit (eg Seconds) and adjust your variable as necessary.
And what makes one be a "calculation" field and the other a "text" field?
How would anyone know? I don't see any indications of this.
<rant>
Isn't this just a design choice you have made for using the ICU date/times?
In spite of knowing the formula (double % to get one), it makes things very complex and very hard to read. Plus we then have to add another "Filter" action, which doesn't make sense calling it a "filter", when it is really doing a conversion.
On top of all this is that the KM requires for us to reverse the normal programming convention where all text is a variable, command, or keyword, etc, unless it is in some form of quotes. And I don't understand the need for this. Once we have gone through all the hoops to get the number of %'s correct, why can't you just evaluate it as normal?
It is the combination of all of this not-so-clear-logic that makes this very hard to use, and very frustrating. </rant>
Presumably by reading the documentation on the token.
The third field of the token is the Time Units, and it has a set of possible values. It's not a calculation, it is essentially the same as the first part of the token (“ICUDateTimePlus”) - just a string which has some meaning.
You mean to not have any processing? No, its not just a design choice, you can't put text tokens inside text tokens, it would be impossible to parse. I could allow a variable name instead, as long as the variable name didn't match any of the possible token values, but that would be inconsistent with everything and prone to disaster.
That’s what a filter is - it takes some sort of input and converts it into some sort of output.
That is because this is text, not a programming language. This is text, and then it has a template engine which allows you to insert non-text elements into it. This is the same style used in many other places (such as Mail Merge form letters for example). So there needs to be some way to specify, within the text, that a part is not just plain text. That is where the percent encoded tokens come in (in other template engines, other characters might be used, like angle brackets for example).
So now you have a token, within text, like %LongDate%. And from that, extended, gives tokens like %ICUDateTimePlus%5%Days%yyyy-MM-dd%. Within that, there are four fields:
ICUDateTimePlus - plain text, one of a set of possible values , defines the token
5 - calculation (which cannot include % characters)
Days - plain text, one of a set of possible values, defines the time units
yyyy-MM-dd - this is actually another template engine with the ICU Date Time format. In this case, most of the characters are actually standins for substituted text, but all non-substituted text is passed through unchanged.
I understand that by the time you start taking this rather complex token, and wanting to do more than it was designed form, things have gotten pretty complicated, but that complexity comes from the nature of the problem, none of this is just "a design choice", or more, it is a consequence of higher level design choices.
I suppose Keyboard Maestro text fields count be more like some sort of programming language, where things are quoted, but do you really want to have to say things like:
There isn't any practical way for me to support tokens within the plain text section of other tokens because the parser would have no hope of figuring out what it meant - the fields within tokens have to not include percent characters in order for the parser to figure it out.
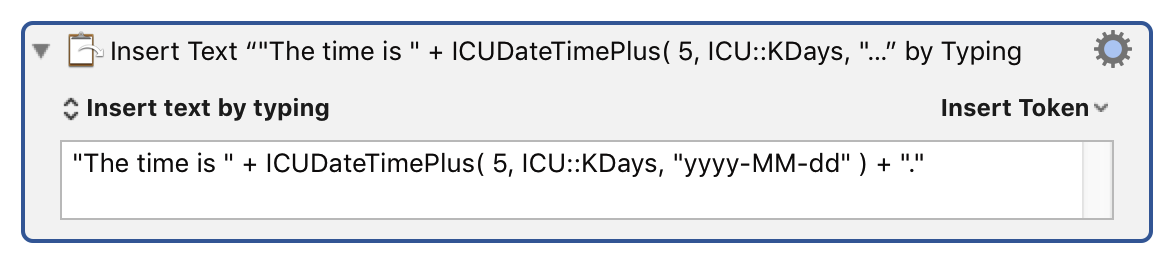
There is some exception to this in that calculations that include brackets must have the brackets balanced, and therefore text within them can have percent characters. So you can actually have percent characters within tokens, as long as they are within nested brackets (at least in some cases). This allows the Calculate token to contain text functions like this:
The Words variable contains %Calculate%CHARACTERS(%Variable%Words%)% characters.
So maybe I could introduce some sort of style like this:
But the square brackets would have to be recognised and removed, and then its not really text, since now the meaning of the square brackets are special, and so its only applicable to cases where the token can only have a set of know values that cannot include the square bracket (otherwise it would inexplicably change the meaning of text that just had square brackets at the start and end).
Hopefully this explains why it is like this. None of this is just some sort of capricious design choice on my part, it is a consequence of the whole setup and trying to do (and allow to be done) more than Keyboard Maestro is designed to do. In this case, if the solution of using the Process Tokens filter to get a second level of indirection is too onerous, then accept that ICUDateTimePlus cannot be used in this way. The Process Token filter is more or less specifically designed to allow this sort of excess.
Peter, thanks for taking the time to fully explain why the ICU token works like it does.
After having read and thought about this, I guess I'd find two things helpful if they could be done:
Provide a ICUDateTime popup builder that would build the complicated embedding of variables in the token, that would be located in the Insert Token > Dates popup.
Provide an Action Gear Option to process the computed token without requiring a follow-on Filter Action.
On a related topic, provide the same type popup builder for using dynamic variables. #2 would also work for this.
I suspect many other user would also find this helpful. It seems we have had many discussions on configuring the ICUDateTime token.
Well, I would call it something like "Process/Resolve All Tokens".
What's bizarre about it? Just asking KM to resolve the text until no tokens remain -- only the resulting data. IOW, perform the same function as a follow-on Filter Action.
When we create a dynamic KM Variable, it looks much like the ICUDateTime in terms of tokens and multiple %.
IAC, the result is: %Variable%VarNameAfterResolvingTokens%
So, #2 would simple resolve this final token like it would the ICUDateTime.
Those two are not the same thing. What happens if the resulting data contains something that looks like a token.
For example what happens with input of %%%%%%%%?
What happens if the resulting data is supposed to have a couple percent characters in it?
Sure, but as I said, it only removes the need for the Filter: Process Tokens action, it does not remove the complexity of getting the input correct in the first place, properly doubling the appropriate percent characters. So the reduction in complexity seems fairly low.
Yes, that is what I originally said, “Process Tokens Twice”. That would be the equivalent of Process Tokens followed by Filter: Process Tokens. Which is not equivalent to “Process/Resolve All Tokens”, which is more like "Process Tokens until it stops changing".
Well, I guess I'll beat this dead horse one more time, then quit wasting our time.
“Process Tokens until it stops changing” is really what I'd like, and it would be the equivalent to the user entering one or more Filter Actions. Both can lead to erroneous/unusable results if the user feeds them bad data.
But if you don't see the utility in that, then just ignore this. OTOH, perhaps it should be ignored in any case. If the user has something that complex he/she is trying to write in KM, it is likely esoteric and they should probably be using another language. I'm sure you have bigger fish to fry.