Like so many here, I am a bit challenged using REGEX expressions.
I have a paragraph of text that looks like this:
20:02 Hahn: Portraits of painters (Laure Favre-Kahn, piano). 20:14 Tchaikovsky: Piano Concerto No. 3 in E flat major (Gary Graffman and the Philadelphia Orch./Eugene Ormandy). 20:29 Lehár: Hot kisses is an opera without lips. Giuditta. (Margareta Haverinen, soprano, University of Helsinki Teacher Training Institute choir and RSO/Seppo Hovi). 20:35 Beach: String quartet (Ambache chamber ensemble). 20:49 Vieuxtemps: Violin Concerto No. 5 in A minor (Grétry) (Pinchas Zukerman and London SO/Charles Mackerras). 21:09 Casella: Italy (BBC FO/Gianandrea Noseda).
I want to add a a bullet (•) and a carriage return so that it looks like this:
• 20:02 Hahn: Portraits of painters (Laure Favre-Kahn, piano).
• 20:14 Tchaikovsky: Piano Concerto No. 3 in E flat major (Gary Graffman and the Philadelphia Orch./Eugene Ormandy).
• 20:29 Lehár: Hot kisses is an opera without lips. Giuditta. (Margareta Haverinen, soprano, University of Helsinki Teacher Training Institute choir and RSO/Seppo Hovi).
• 20:35 Beach: String quartet (Ambache chamber ensemble).
• 20:49 Vieuxtemps: Violin Concerto No. 5 in A minor (Grétry) (Pinchas Zukerman and London SO/Charles Mackerras).
• 21:09 Casella: Italy (BBC FO/Gianandrea Noseda).
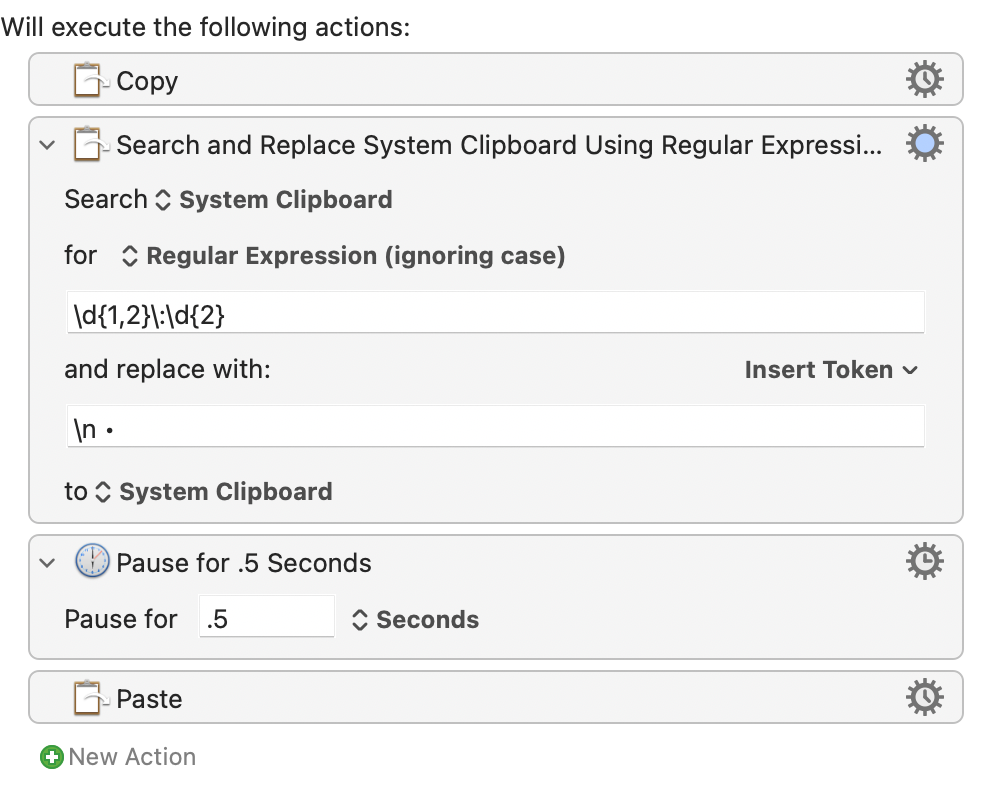
I've come up with this simplistic solution, but it gets rid of the time stamp:
I've gathered from previous postings that I somehow need to store the time value for each line in a variable and use the "for each in collection" and then reassemble the line. But I'm stuck.
Would greatly appreciate if I someone could steer me towards the solution.
And it works close enough for me to be very happy. Thank you very very much! (I can't begin to tell you how many hours I've stared at this and tried unsuccessful convoluted solutions)
Well, that’s just represents the contents of the capture group that you’re searching for in your search expression. (FYI it can also be written \1)
BTW - it’s been said a few times in this forum that it’s never worth spending hours on trying to solve something as it’s a lot easier to just ask here! (Mind you, I’m as guilty as anyone…)
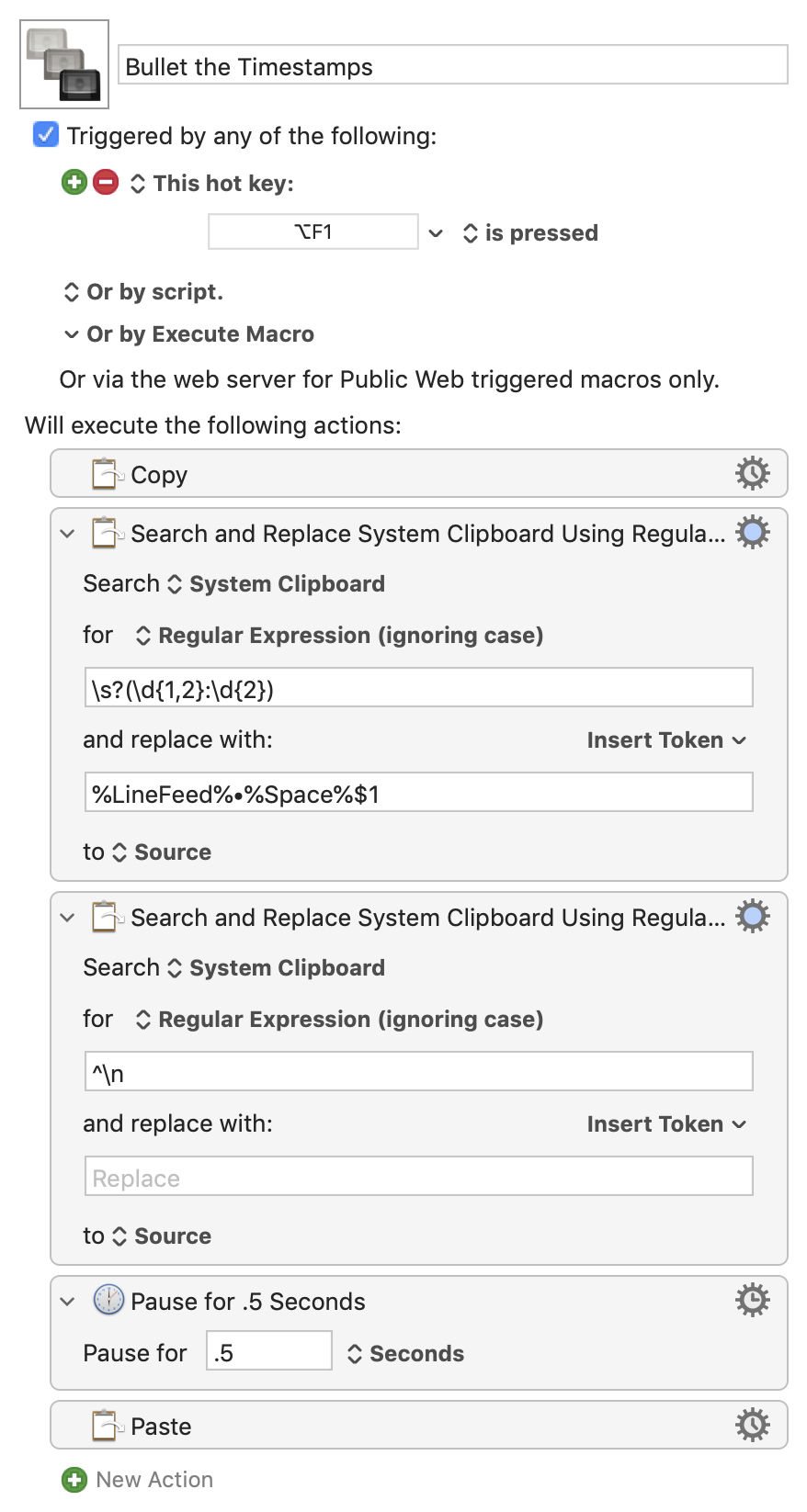
You'll find that it leaves a trailing space at the end of each line and adds an extra blank line at the beginning. If I'm reading it right you are also adding a space before every bullet, which you may or may not want.
You can tweak the regular expression slightly to take account of those spaces:
\s?(\d{1,2}:\d{2})
...where \s is "any white space" and the ? makes it optional -- that way you'll match both the timestamps in the middle of your string and the very first one.
You can clear the leading blank line with a "Search and Replace" and a regex of ^\n, replacing with nothing -- the ^ "anchors" the expression to the beginning of the text, so the only match is when "first character is a linefeed".
Putting that together (and using some tokens to make "invisible" characters more obvious in the replace) gets you: