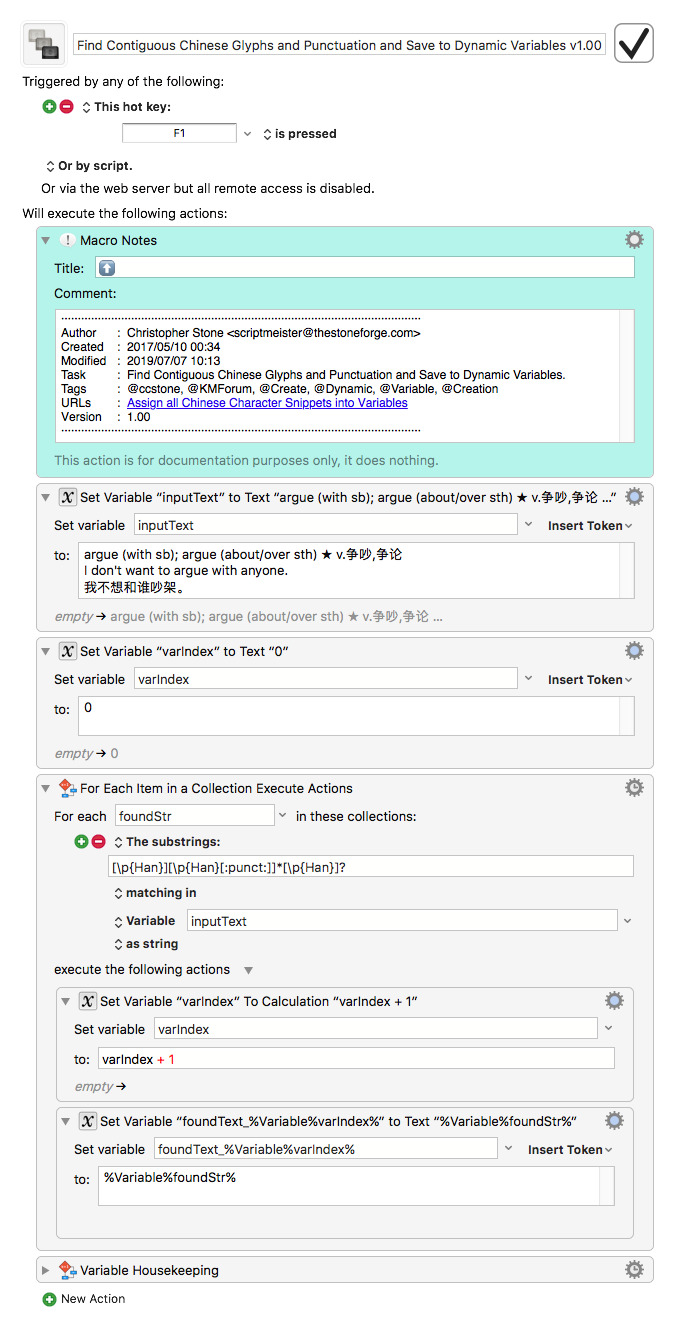
@ccstone Works great! For loop here is the best solution I guess.
But it seems like there's a little problem about nested variables.
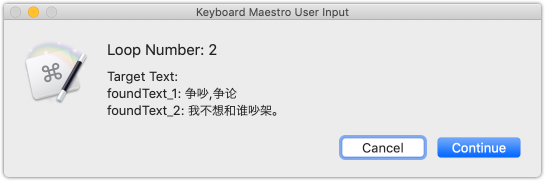
After I display the variable ***foundText_%Variable%varIndex%***.
What I got after running the macro are
'foundText_1', ''foundText_2'' instead of
'争吵,争论', '我不想和谁吵架。'
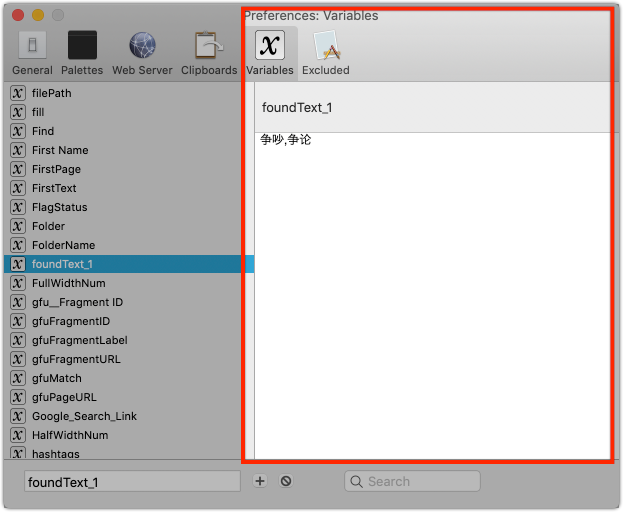
Did you check the foundText variables in the KM preferences' Variables pane after running the macro? You should be able to find the variables with the Chinese text there:
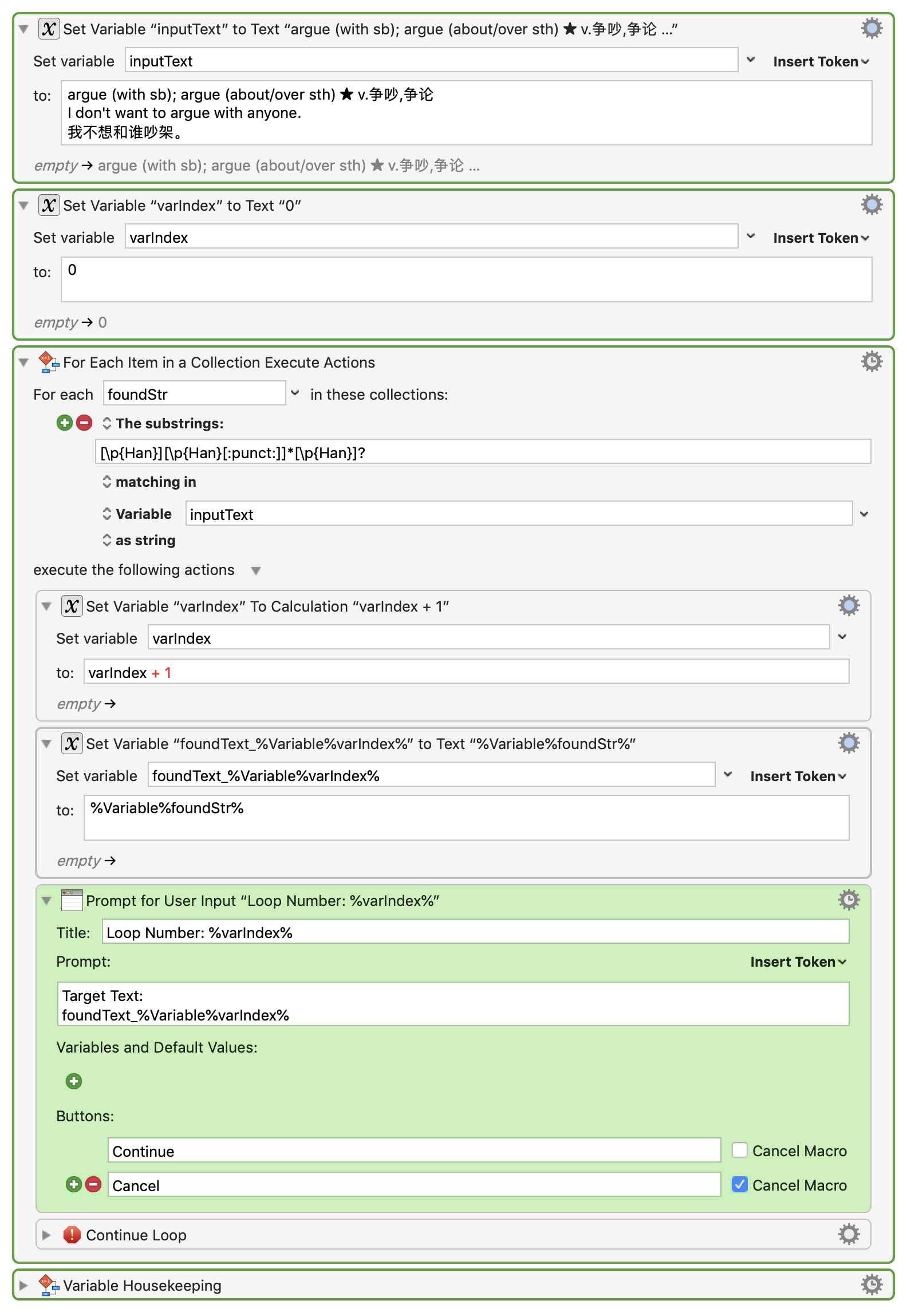
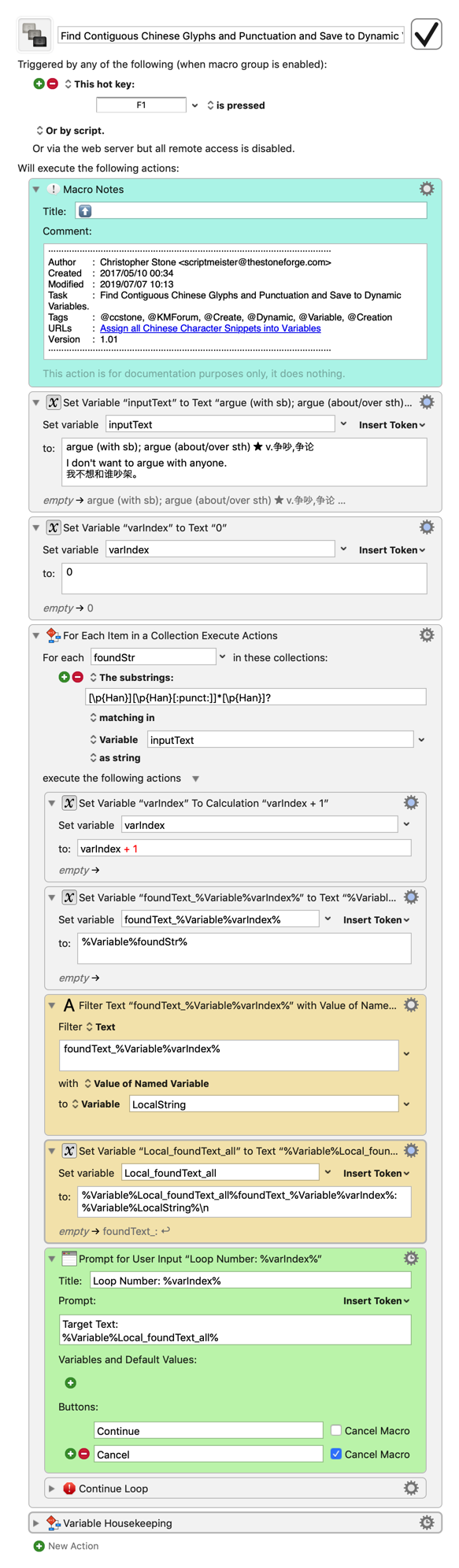
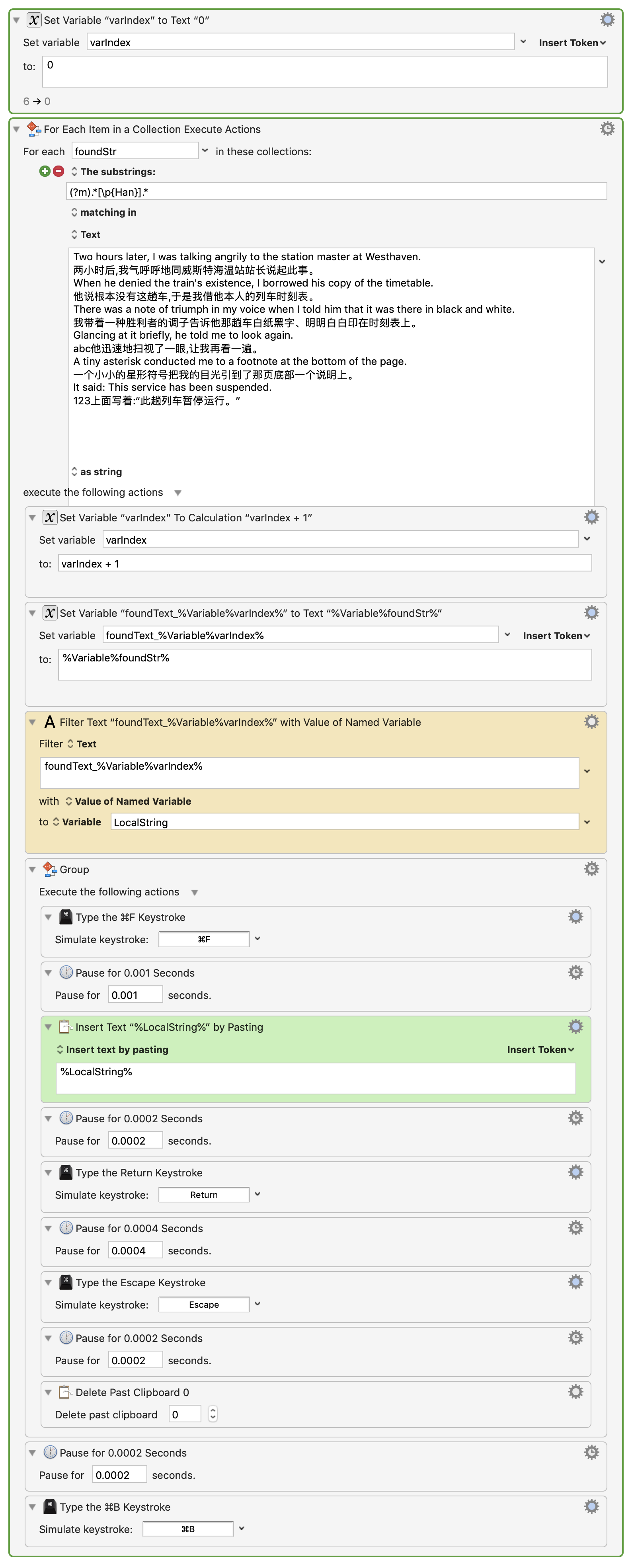
If you'd like to include a prompt that displays the found text in every loop, this modification to the version you uploaded should do the trick (new actions marked with yellow):
Looks like Chris @ccstone has provided a solution to your request.
I have a couple of thoughts that you might find helpful.
Storing Results of Matches
May I ask why you want to store the results into separate KM Variables? How do you plan to use these variables?
IME, it is usually better to store the results of multiple matches into a single variable, usually with each match being on a separate line. This makes it much easier to process the results further and/or to save the results to a file.
The exception to this is when you want to store each match into a known entity, like "Name", "Address", "Phone", etc.
Chinese Punctuation
I know next to nothing about Chinese, but in a bit of research I did it would appear that Chinese punctuation is different from punctuation of Indo-European languages. So, if you expect there may be Chinese punctuation in your source text, the RegEx metacharacter [:punct:] that Chris uses may need to be adjusted/expanded.
After a bit more study, it is not clear to me whether or not the RegEx character class \p{han} includes Chinese punctuation or not. Perhaps Chris will know. Here is one reference that I found most helpful, yet not conclusive: Use regular expression to match ANY Chinese character in utf-8 encoding .
OK, I did one experiment using this for a Chinese comma: 逗号
If that is a comma, then the RegEx \p{han} DID match it. So maybe mystery is solved?
Well, I hope this will add more information than confusion. Any experts on Chinese Regex please jump in.
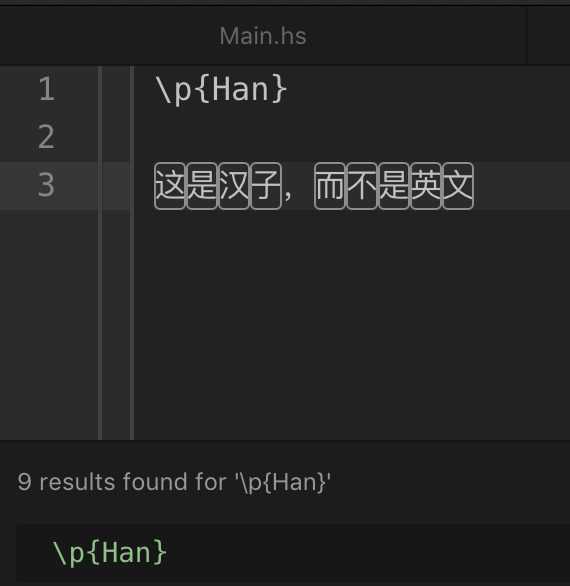
\p{Han} (not always recognized without the leading upper case character) matches 汉子 (Chinese characters) but not the double-width punctuation characters used in Chinese text.
逗号 is not itself a comma. (It's the Chinese name for a comma, and consists of two 汉子 - Han zi)
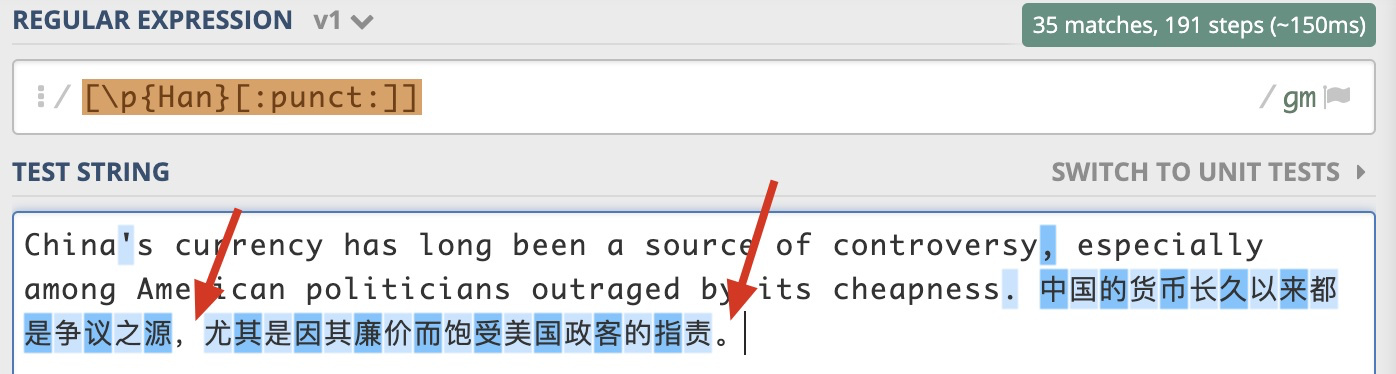
After some research, I've found that you can use [\p{Han}] to match any Chinese Character except punctuation(Chinese punctuation and European punctuation). But you can match any Chinese character including both Chinese punctuation and European punctuation by using [\p{Han}[:punct:]]
@ComplexPoint \p{Han} can't match any punctuation (Chinese or European, double-width or not)
That hasn't been my experience – [:punct:] doesn't match CJK (double-width) punctuation in Regex engines that I'm using. See here for example, the two single-width commas are matched, but not the Chinese punctuation: