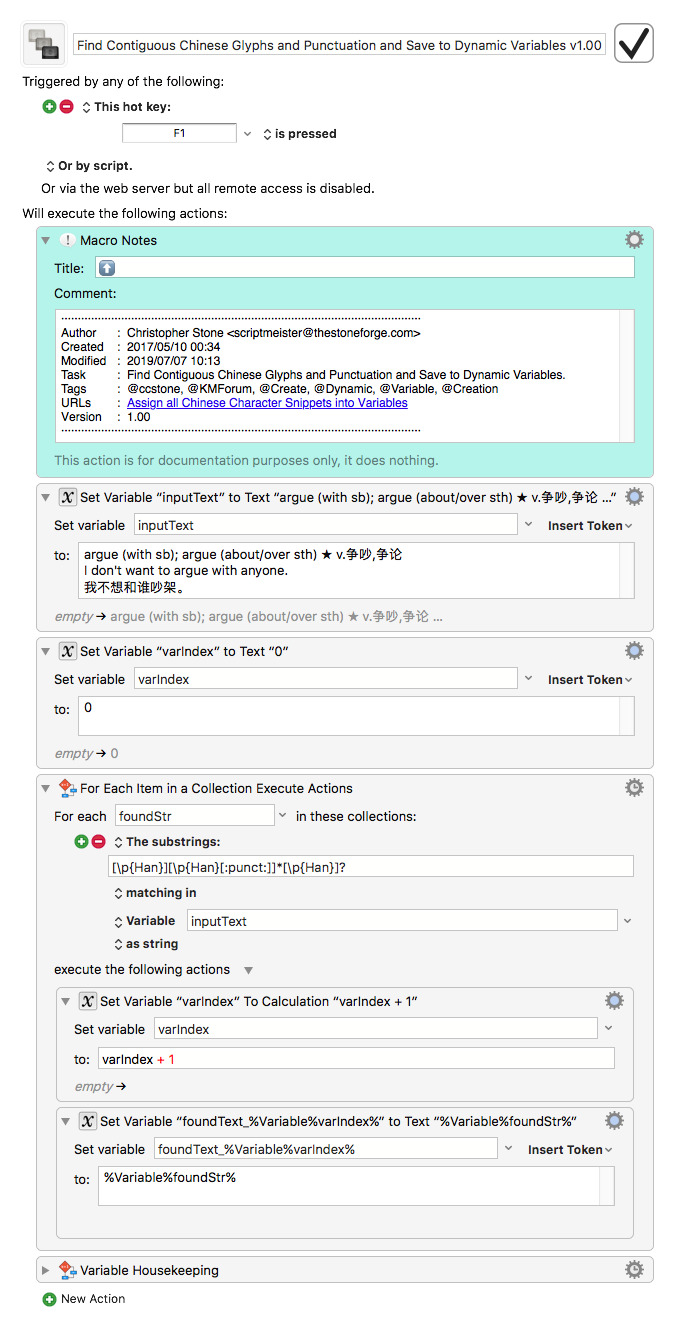
Hey Alx,
Can it be done? Sure – but it's not exactly straightforward.
Run the macro. See the “foundText_” items in the variable inspector panel of the Keyboard Maestro Editor preferences.
-Chris
Find Contiguous Chinese Glyphs and Punctuation and Save to Dynamic Variables v1.00.kmmacros (8.5 KB)