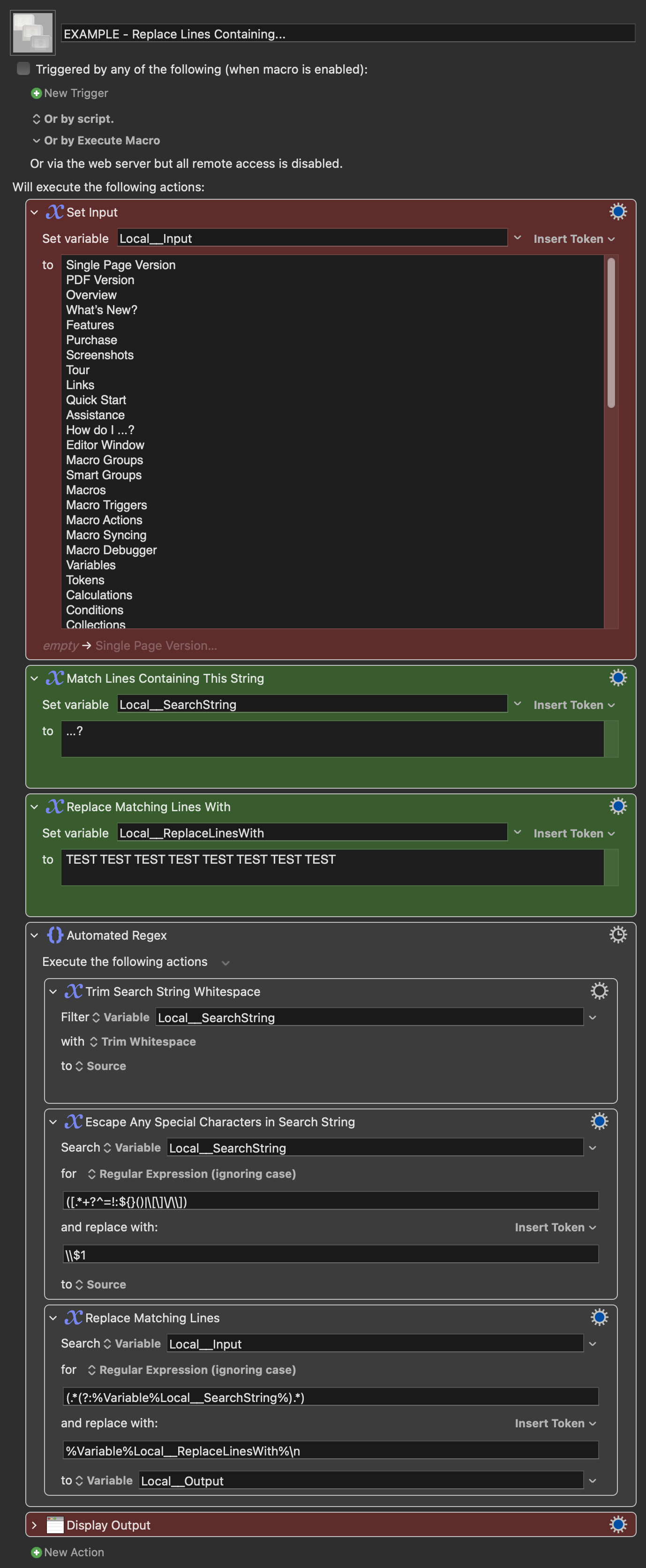
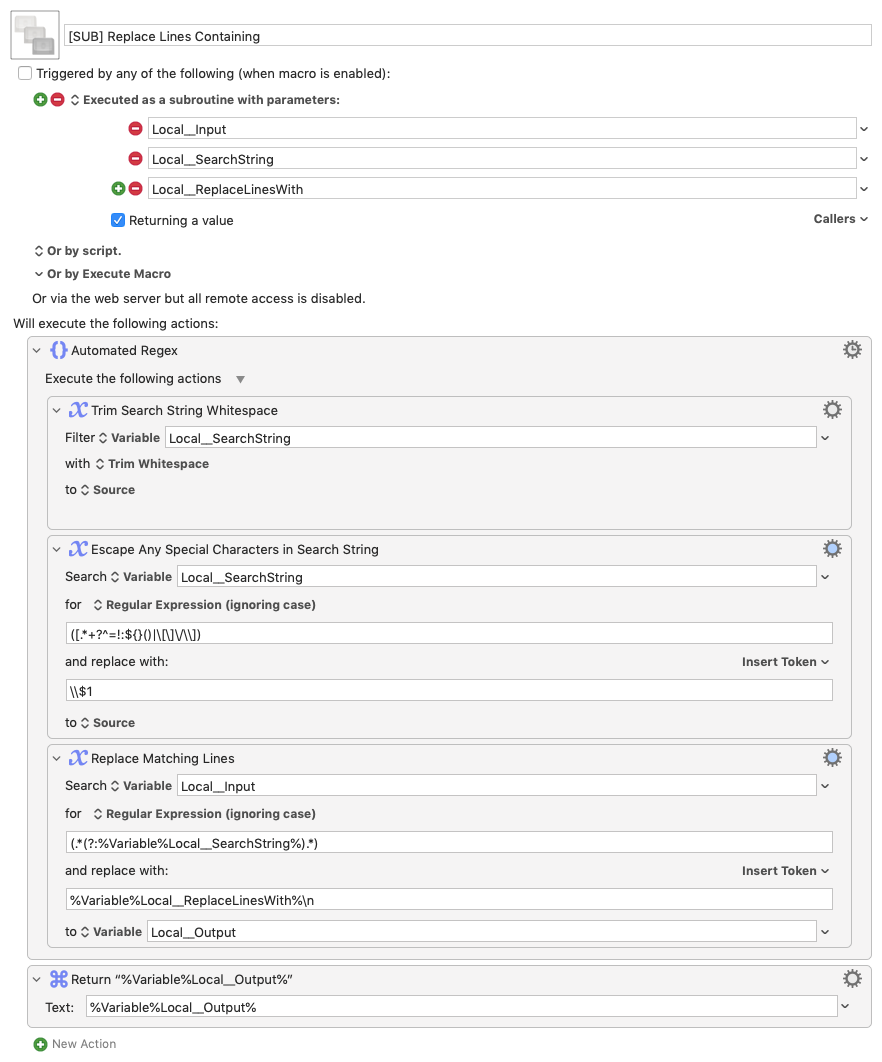
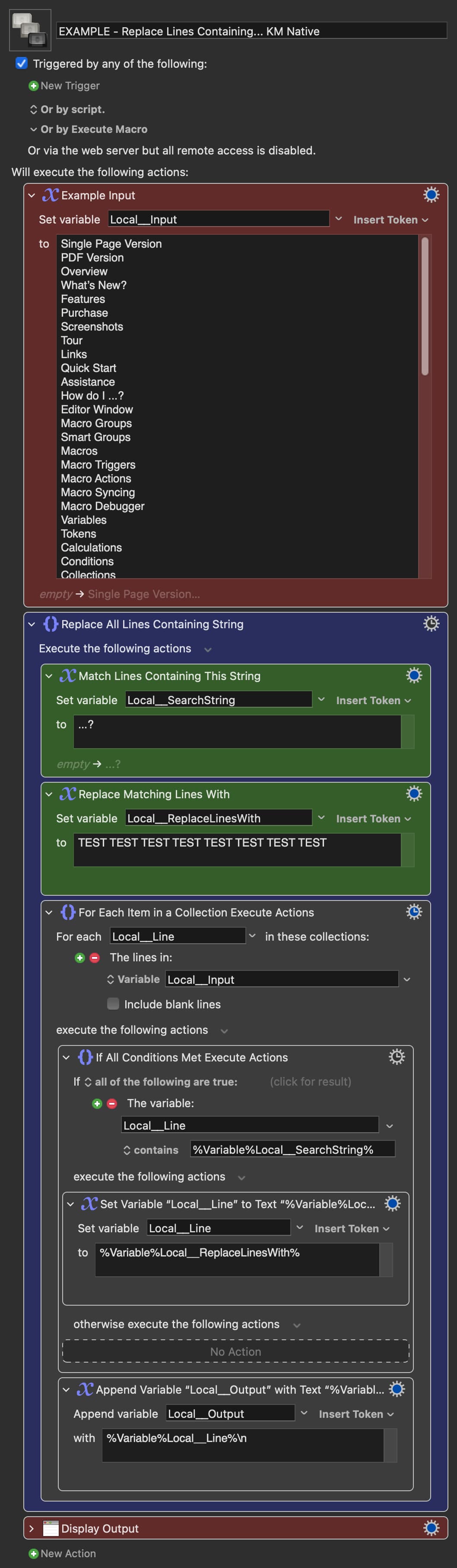
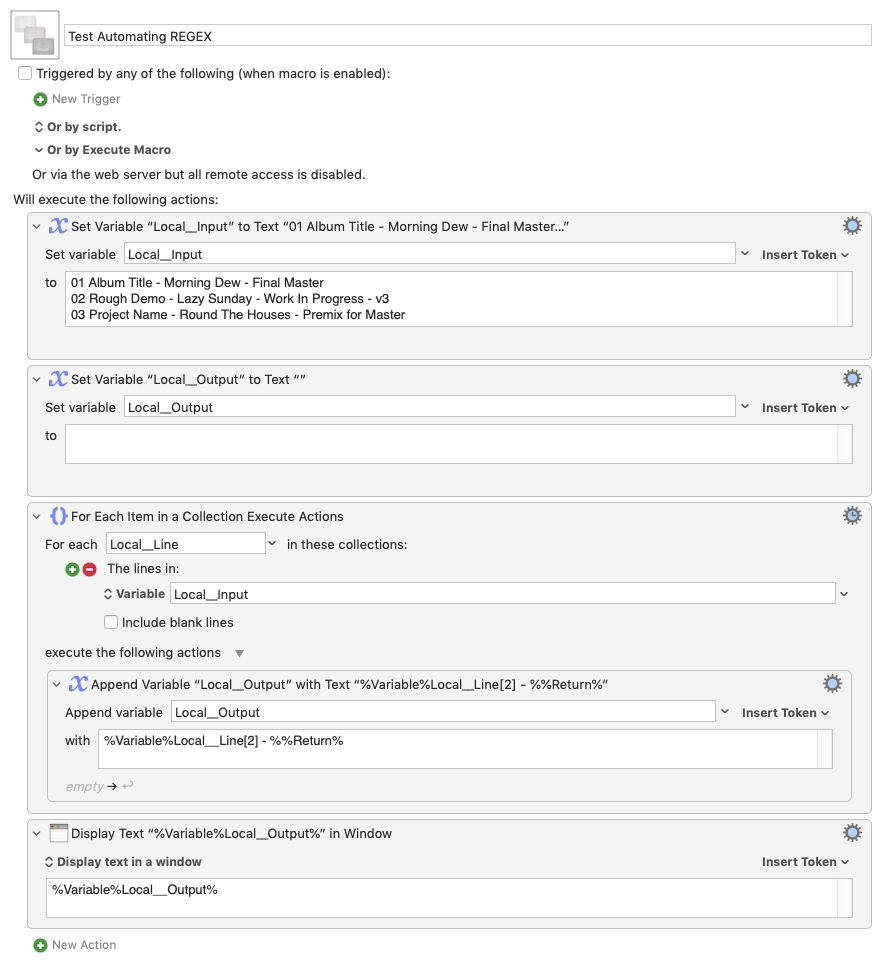
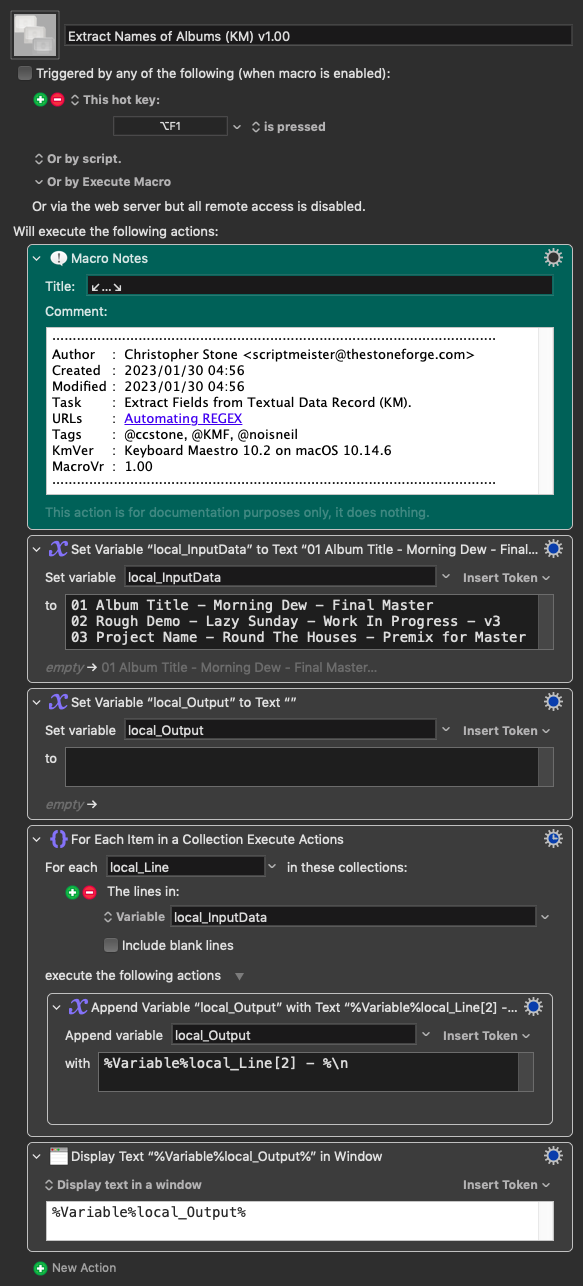
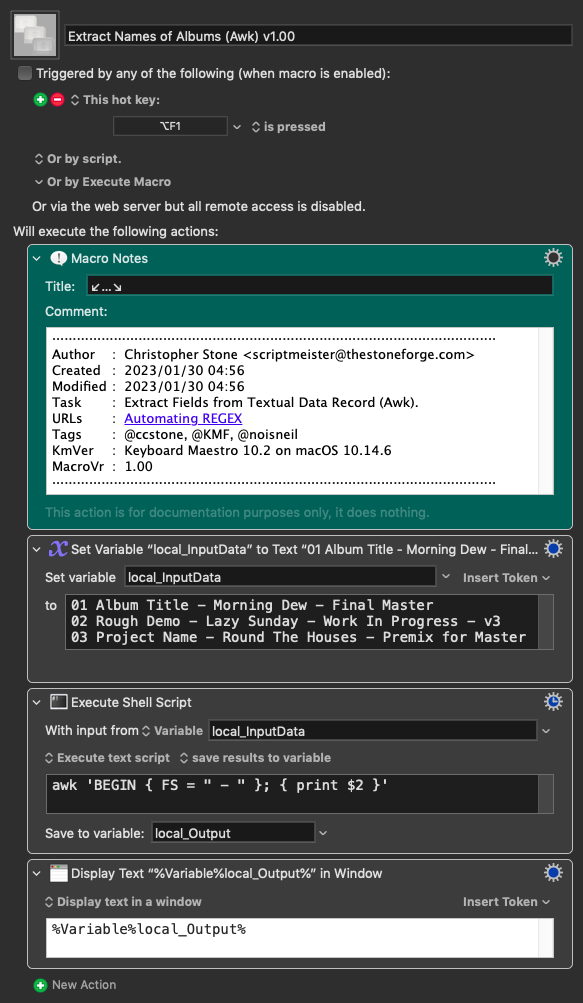
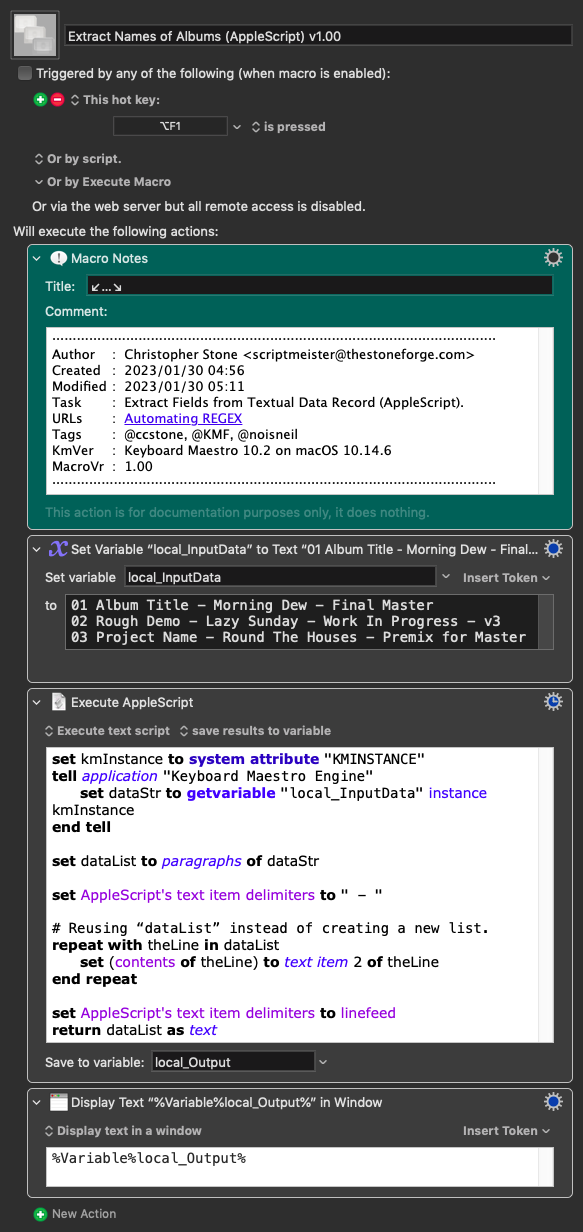
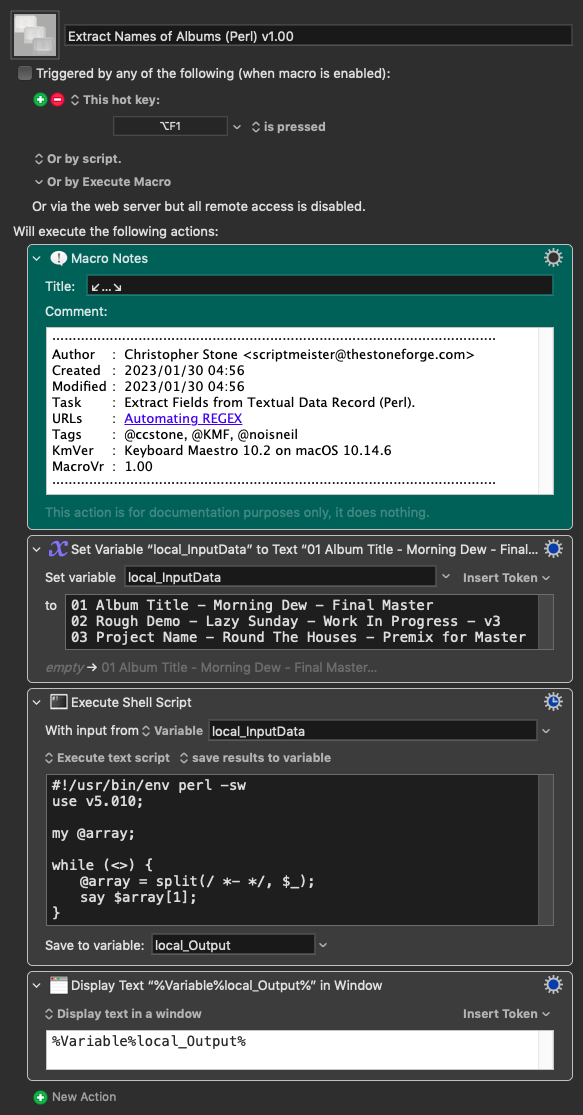
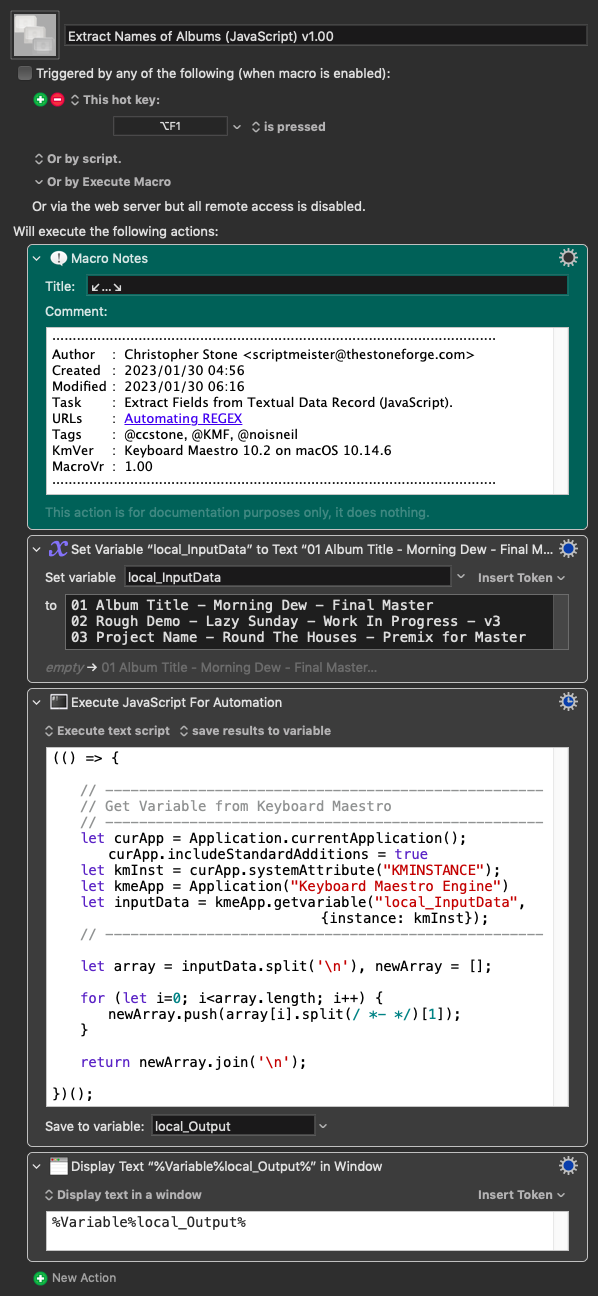
I'll give you this full JS example for you to play, but I think I would use a parser combinator for this task.
Instead of using regex, you could see it as a sequence of steps; each one those takes the input of the previous one.
So, we defiine a function that operates on an arbitrary line (let's call it x):
const artistName = x => compose(
strip,
head,
tail,
splitOn("-")
)(x)
and then we obtain:
- a list, using "-" as the separator (
splitOn("-")),
- the second element of that list, and
- we
strip leading and trailing whitespace from that line.
Finally, we map artistName over the lines of the input string, and join (unlines) the resulting list using a newline character.
unlines(
map(artistName)(
lines(s)
)
)
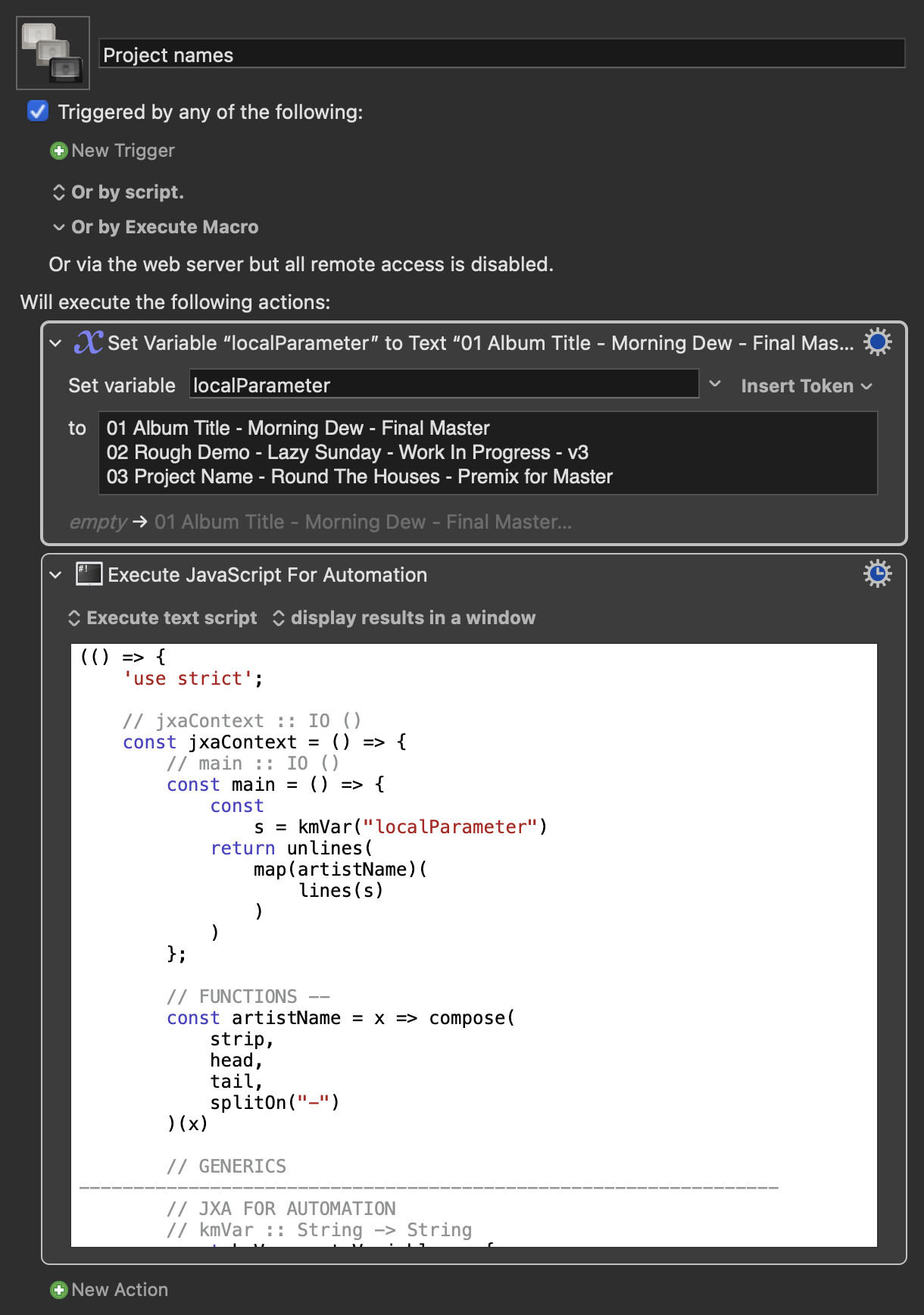
Project names.kmmacros (6.6 KB)
Expand disclosure triangle to see "Javascript" source
(() => {
'use strict';
// jxaContext :: IO ()
const jxaContext = () => {
// main :: IO ()
const main = () => {
const
s = kmVar("localParameter")
return unlines(
map(artistName)(
lines(s)
)
)
};
// FUNCTIONS --
const artistName = x => compose(
strip,
head,
tail,
splitOn("-")
)(x)
// GENERICS ----------------------------------------------------------------
// JXA FOR AUTOMATION
// kmVar :: String -> String
const kmVar = strVariable => {
const
kmInst = standardAdditions().systemAttribute("KMINSTANCE"),
kmeApp = Application("Keyboard Maestro Engine");
return kmeApp.getvariable(strVariable, {
instance: kmInst
});
};
// standardAdditions :: () -> Application
const standardAdditions = () =>
Object.assign(Application.currentApplication(), {
includeStandardAdditions: true
});
// https://github.com/RobTrew/prelude-jxa
// JS Prelude --------------------------------------------------
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
// A pair of values, possibly of
// different types.
b => ({
type: "Tuple",
"0": a,
"1": b,
length: 2,
*[Symbol.iterator]() {
for (const k in this) {
if (!isNaN(k)) {
yield this[k];
}
}
}
});
// compose (<<<) :: (b -> c) -> (a -> b) -> a -> c
const compose = (...fs) =>
// A function defined by the right-to-left
// composition of all the functions in fs.
fs.reduce(
(f, g) => x => f(g(x)),
x => x
);
// findIndices :: (a -> Bool) -> [a] -> [Int]
// findIndices :: (String -> Bool) -> String -> [Int]
const findIndices = p =>
xs => {
const ys = [...xs];
return ys.flatMap(
(y, i) => p(y, i, ys) ? (
[i]
) : []
);
};
// head :: [a] -> a
const head = xs =>
// The first item (if any) in a list.
xs.length ? (
xs[0]
) : null;
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single
// string delimited by newline and or CR.
0 < s.length ? (
s.split(/[\r\n]+/u)
) : [];
// map :: (a -> b) -> [a] -> [b]
const map = f =>
// The list obtained by applying f
// to each element of xs.
// (The image of xs under f).
xs => [...xs].map(f);
// splitOn :: [a] -> [a] -> [[a]]
// splitOn :: String -> String -> [String]
const splitOn = pat => src =>
// A list of the strings delimited by
// instances of a given pattern in s.
("string" === typeof src) ? (
src.split(pat)
) : (() => {
const
lng = pat.length,
[a, b] = findIndices(matching(pat))(src).reduce(
([x, y], i) => Tuple(
x.concat([src.slice(y, i)])
)(lng + i),
Tuple([])(0)
);
return a.concat([src.slice(b)]);
})();
// strip :: String -> String
const strip = s =>
s.trim();
// tail :: [a] -> [a]
const tail = xs =>
// A new list consisting of all
// items of xs except the first.
"GeneratorFunction" !== xs.constructor
.constructor.name ? (
0 < xs.length ? (
xs.slice(1)
) : undefined
) : (take(1)(xs), xs);
// unlines :: [String] -> String
const unlines = xs =>
// A single string formed by the intercalation
// of a list of strings with the newline character.
xs.join("\n");
// MAIN --
return main();
};
return jxaContext();
})();