Thanks for everyone's contributions. Very useful to have all these methods in one place. As my main concern is quick workflow, here's another idea I had:
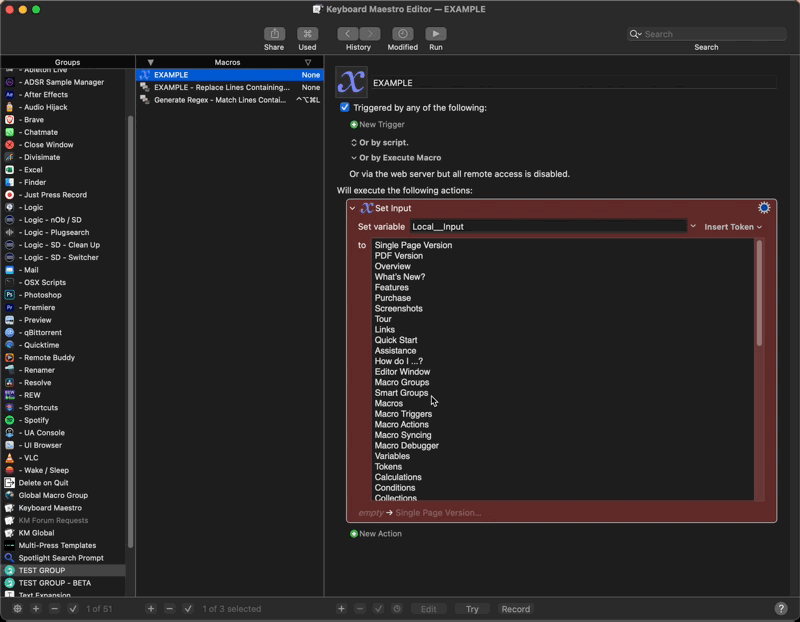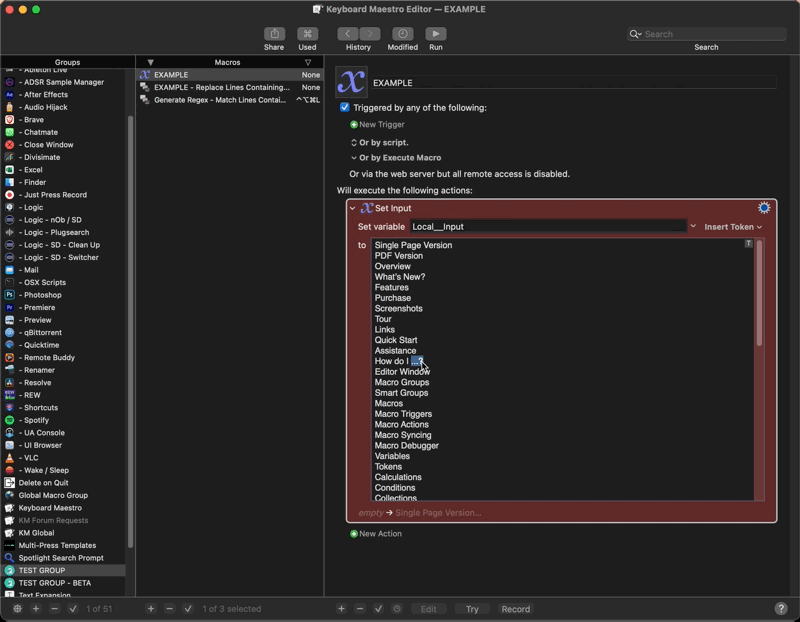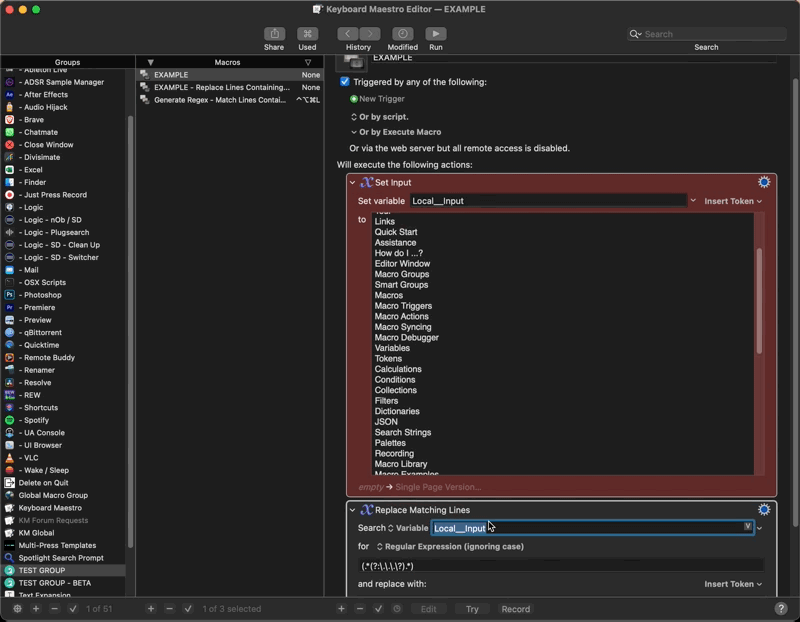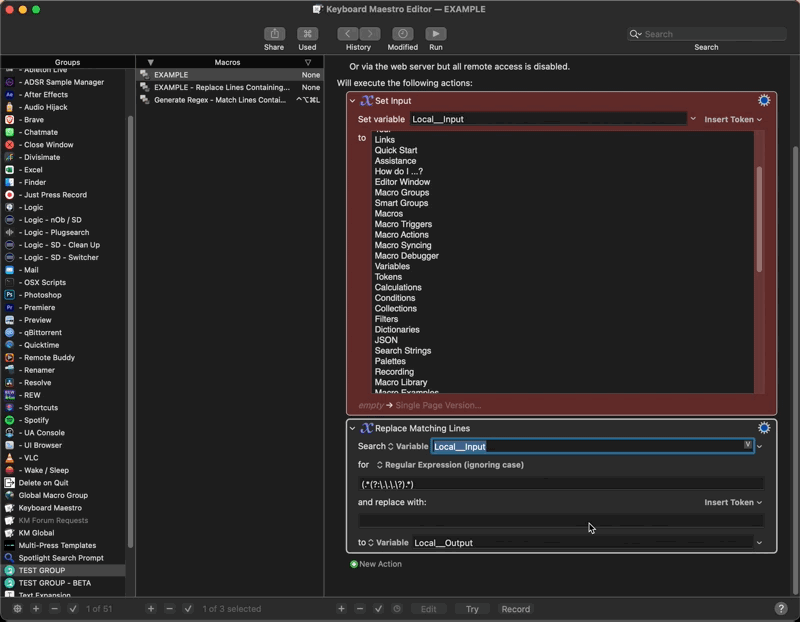
Can't get much quicker than that. Yes, I know there's a limit to how complex it can be, but for simple find-and-replace stuff, I think it might be quite handy.