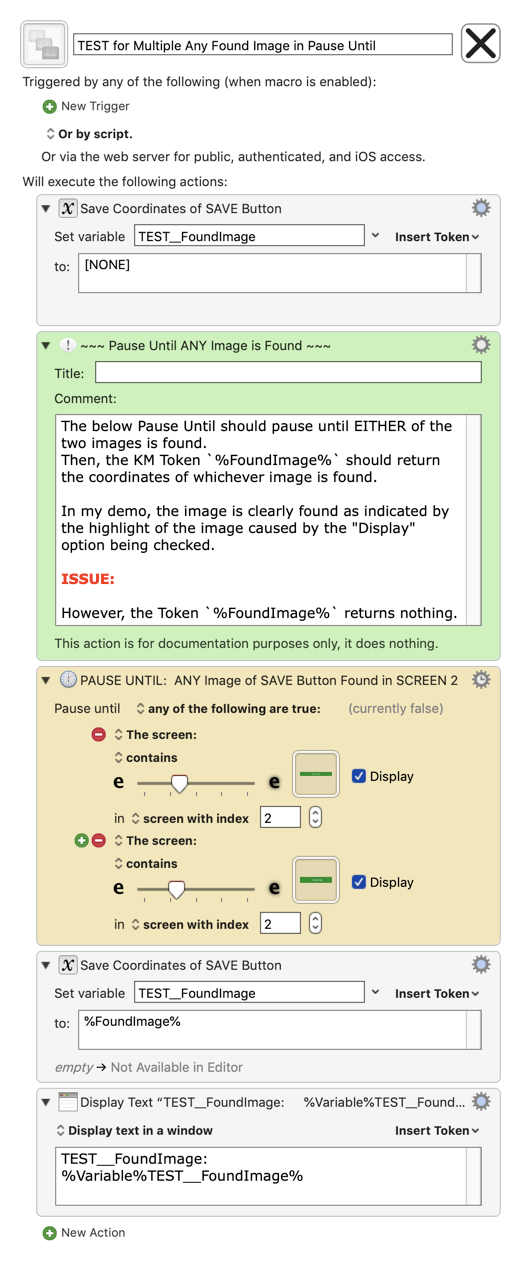
MACRO: TEST for Multiple Any Found Image in Pause Until
~~~ VER: 1.0 2019-07-16 ~~~
Changes You May Need to Make
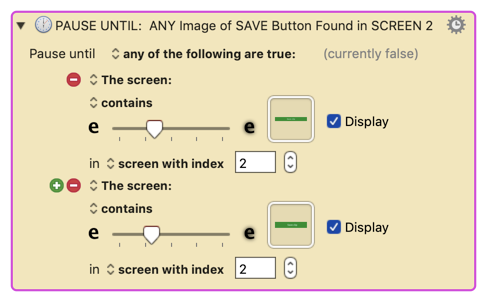
In the Pause Until Action, change the Screen Index to #1, or whatever screen you will be using.
(@peternlewis, is there a way on this Action to indicate the FRONT screen?)
Replace the image in the Pause Until with screenshots from your screen.
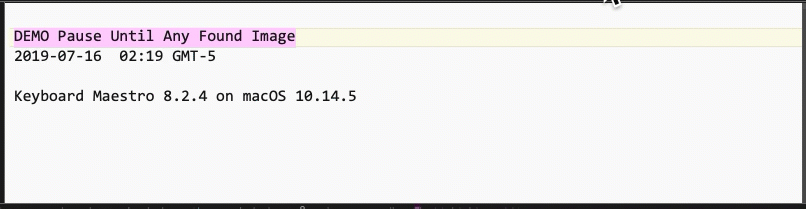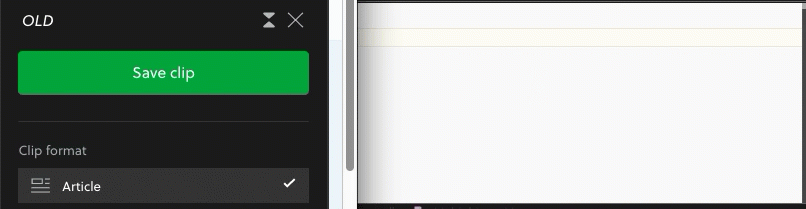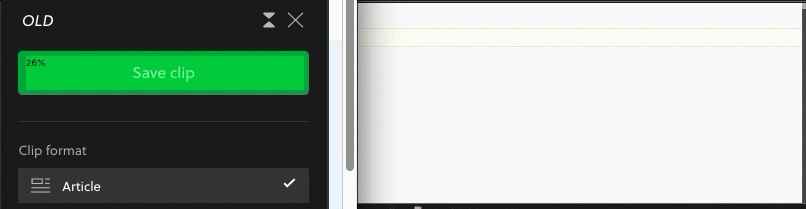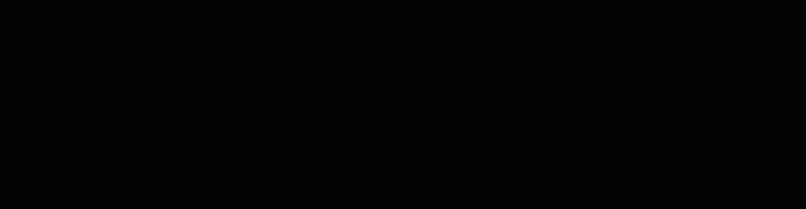
Mine are from the Evernote Chrome Web Clipper "Save" button.
Hey JM, you are more than ten times smarter than me, and I'm not sure I fully understand your issue because I don't have multiple screens, but I work with Find Image a lot every day so I have a possible explanation for this bug. I always avoided putting two Find Image conditions in an action and then using the %FoundImage% token knowing that it wasn't clear which of the two image searches was the "last" one. In your scenario you are setting up just such a situation. From the looks of it the two images you are searching for are different. I presume one was found, and the other wasn't. If you change the order of the search conditions, you might get the result you want.
P.S. I will be on vacation soon so when you respond or refute me I may not be here to confirm.
@Sleepy is spot on (and should get back to his vacation!)
It is not a bug per se. The FoundImage token returns the result of the last found image, which in this case is the result of either of the two found image conditions. One has succeeded (and has a value) and one has failed (and as such has an empty value). Which is last is non-deterministic, and unaffected by the intuitive understanding that you might like the one that actually matched to be the one that is returned.
This logic is contrary to every programming language I have ever used, and to every computer class I have taken.
Whenever there is a boolean OR logic (such as with the KM "any condition") then the expression is evaluated from left to right (top to bottom). As soon as a true condition is met, then the processing stops since you ONLY need ONE condition for the complete expression to be evaluated as true.
So, when KM matches a "found image" (and it does based on the "Display" option), then it should stop processing other "any" conditions, and return the %ImageFound% coordinates for the image that has been found.
I see NO value in continuing to look for other FoundImages, or evaluate the other "any" conditions once a true has been found. In fact, this causes KM to be slower, and to not confirm to standard programming expectations.
On the contrary, changing it would make the KM "FoundImage" condition be much more powerful and have wider applications.
If you don't want to change this behavior, can you please provide a rational technical reason?
This is true for some languages and not for others. For mathematics, any positive in any condition is sufficient, so not all conditions need to be evaluated. For some languages, this is used to short circuit some calculations (such as “true or FunctionCall()” as well as “FunctionCall() or true” will, may, or will not call FunctionCall() depending on the language.
Some languages short circuit, some evaluate every condition always, some evaluate left to right, some evaluate in any order.
In Keyboard Maestro’s case, all conditions are evaluated asynchronously, simultaneously. Any condition that returns true for an “any” or false for an “all” condition will result in the condition completing with a result.
As it does. But it is also evaluating all the other conditions. And they still complete (in the sense of finishing, not in the sense of returning a boolean result).
Keyboard Maestro does not continue to look - it stops looking. But it already was looking, and the result is still returned.
All conditions are running simultaneously. All FoundImage conditions set a result when they finish.
In this case, the two conditions are finishing at the same time, functionally the same time (unsurprising since they are doing similar amounts of work), and one is finishing with a positive answer and one is finishing with a negative answer, and then the condition is completing with a result, and then the Pause Until action is completing.
Which found image condition result ends up in the FoundImage token is unknown in that case. It is likely to be the one that succeeds, since the conditions are not evaluated further after one that succeeds, but if the one that succeeds is the first one, and if the other one has failed by that point (but not failed earlier), then you can get the second one.
In any event, as I said, both are running simultaneously, both will stop running after the condition is satisfied, and which result you get in the token is non-deterministic, and this is not likely to change.
I would have to have specific code in to change the processing to ensure this behaved in a specific way, and I don't want to guarantee that behaviour - the only behaviour I define is that the result will be correct based on the results of one or more conditions, any of which may or may not be evaluated in any order or not at all if unnecessary to determine the result.
I don't know of any languates that do this. Please provide some contemporary examples.
IMO that is a design flaw. Why evaluate all when you don't need to?
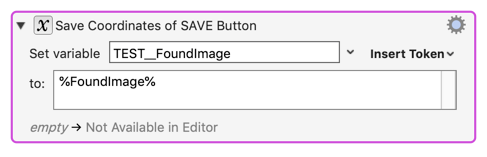
Since ONLY the Condition with the Found Image can exit the Pause Until, why not always set the `%FoundImage% token to the FIRST Found Image that succeeds?
IAC, if the Pause Until exits, I see no logic that would return an empty string for `%FoundImage% token. To do so is either a bug or design flaw.
Finally, if you insist on retaining the current behavior, please provide a common use case that would require that behavior. I don't see any.
To find the image and then have to find it again to get its properties is painfully redundant.
Could you add another token for the Pause-Until action to work around this?
(I.e. one that returns the properties of the found image that releases the pause action.)
For that matter it looks to me that there's no means to detect which condition released the pause, and that too reduces the functionality of the action.
The Find Image feature of KM is spectacular. No debate. I will disown anyone who says otherwise. Of all the features of KM, I'd call this one a core feature. I would even propose renaming KM as "Image Maestro." I use Find Image every day, and I consider its current implementation to be good enough to meet all my needs (if you include the upcoming image storage in v9.) I'm still gobsmacked and flabbergasted how good (i.e., fast and accurate) this feature is. If I wanted to complain about it, I'd complain that it can't accurately find certain images like solid blocks of colour. But when there's a near infinite number of possible images that match the condition, I'm not really sure what it should return.
Some people will call KM's ambiguity here (i.e., what does %FoundImage% contains when it follows multiple Found Image expressions) a "design flaw." I call it a "design decision." In my opinion the distinction between these two phrases is whether the design was intentional or unintentional. So I couldn't argue, for example, that KM's lack of a compiler is a "design flaw" because that's an intentional decision. It's really up to Peter to indicate whether this feature was intentional or unintentional. That's important. And we have to take him at his word. Curiously, he didn't actually say if it was intentional or unintentional, all he said was that "it's unlikely to change." If it was actually unintentional, he would be allowed to call it a design flaw.
If users want another solution, feel free to suggest one. I'm not sure what you mean, Chris, by "add another token to work around this." I can't see what you want this token to do. A different approach would be to have the %FoundImage% token accumulate text results of multiple images but even that's ambiguous because there's no way to correlate which lines comes from which image search since the expressions evaluate asynchronously. (And when you access the token %FoundImage% it could reset the token to an empty string.) There's a plausible idea, but not all plausible ideas are agreeable or helpful to people.
Anyone could easily work around this behavior by using different Find Image actions instead of multiple Find Image conditions. I think I've done that in the past myself. My suggestion to Peter is that he document this recommendation in the documentation. Since this issue causes consternation ("a feeling of anxiety or dismay, typically at something unexpected") to people on this forum, it's probably a good idea to document it.
In some programming languages (Lisp, Perl, Haskell because of lazy evaluation), the usual Boolean operators are short-circuit. In others (Ada, Java, Delphi), both short-circuit and standard Boolean operators are available.
In languages designed for high concurrency, operators may be evaluated in any order simultaneously.
Because they are all evaluated simultaneously.
For example, if you have two conditions, and Variable condition and an Image condition, both are evaluated simultaneously. The Variable condition will finish immediately, and if that is sufficient, the image condition will be abandoned.
Conditions in Keyboard Maestro are like triggers - they have no order. They are a set of conditions.
I have adjusted the code to short circuit the evaluation of the condition testing condition code (the code that checks the progress of each condition) to stop its loop after it finds a condition that will make all others redundant, which should make this case work. The resulting code is less maintainable, duplicates code, and has more places where bugs could hide, so I don't like it, but it's easier than arguing this topic any further.
 I use Find Image every day, and I consider its current implementation to be good enough to meet all my needs (if you include the upcoming image storage in v9.) I'm still gobsmacked and flabbergasted how good (i.e., fast and accurate) this feature is. If I wanted to complain about it, I'd complain that it can't accurately find certain images like solid blocks of colour. But when there's a near infinite number of possible images that match the condition, I'm not really sure what it should return.
I use Find Image every day, and I consider its current implementation to be good enough to meet all my needs (if you include the upcoming image storage in v9.) I'm still gobsmacked and flabbergasted how good (i.e., fast and accurate) this feature is. If I wanted to complain about it, I'd complain that it can't accurately find certain images like solid blocks of colour. But when there's a near infinite number of possible images that match the condition, I'm not really sure what it should return.