Following this idea here, I'm trying to find the fastest way to check for multiple occurrences of a word in the clipboard. In fact, you can reduce this task to finding a second occurrence of any word. This will already make a careful checking of the clipboard content (e..g. a translated sentence) necessary.
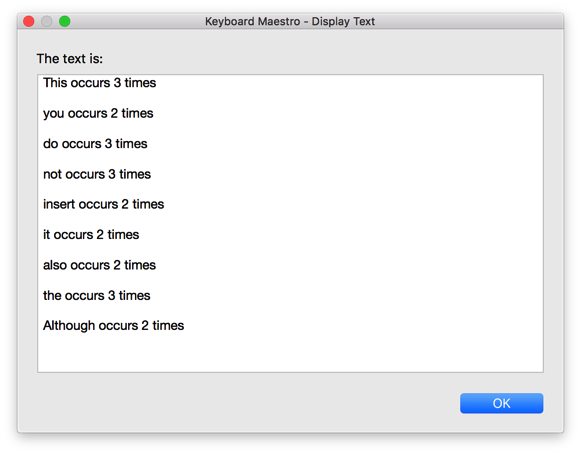
Clipboard contains one of these three example lines:
Macro gives either a warning when a word is found several times in (a sentence on) the clipboard or even displays a message/sticky note indicating the word in bold.
How about this approach?
Save the clipboard content in oldClip.
Determine the first word, via a regular expression looking for word boundaries or white spaces. (Or is there a concept of a word in Keyboard Maestro that I can use?) Assign the word to variable findWord
Calculate the length of variable findWord as lengthWord.
Replace all occurrences of findWord in the clipboard with nothing.
Calculate the length of the clipboard: if the length of the clipboard is shorter than oldClip minus lengthWord, then several occurrences were found.
Display a warning.
Determine the second word and check for multiple occurrence.
I'm not sure how it handles case, and it bases words just around \w+ which is pretty basic (for example isn’t is two words). But it's perhaps a way to get started.
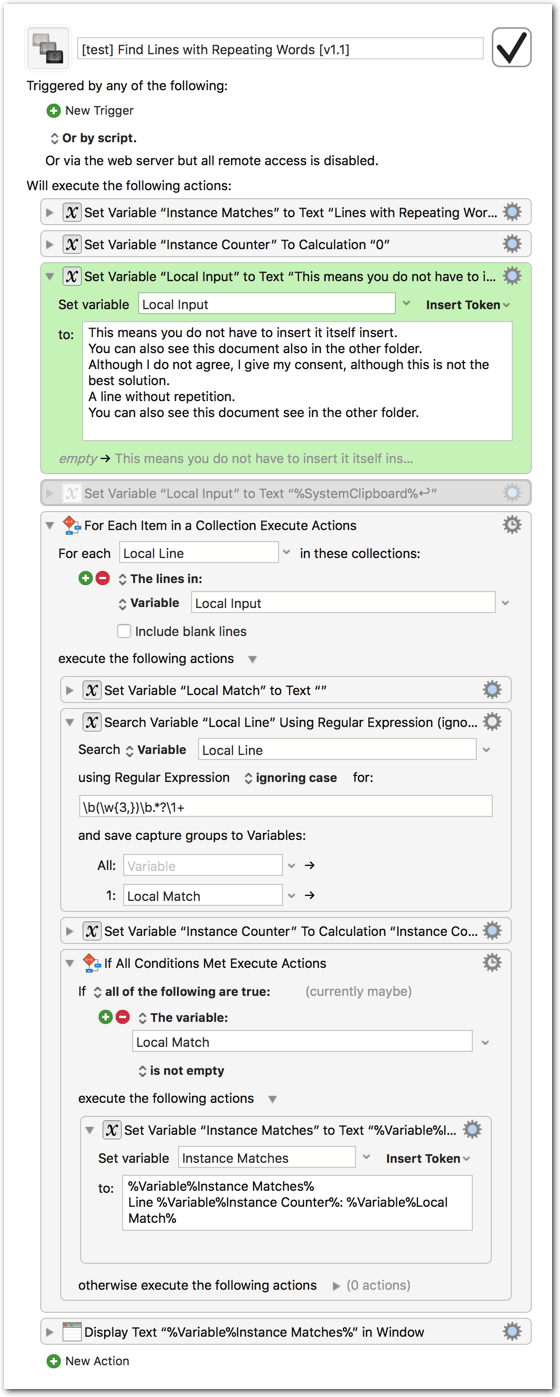
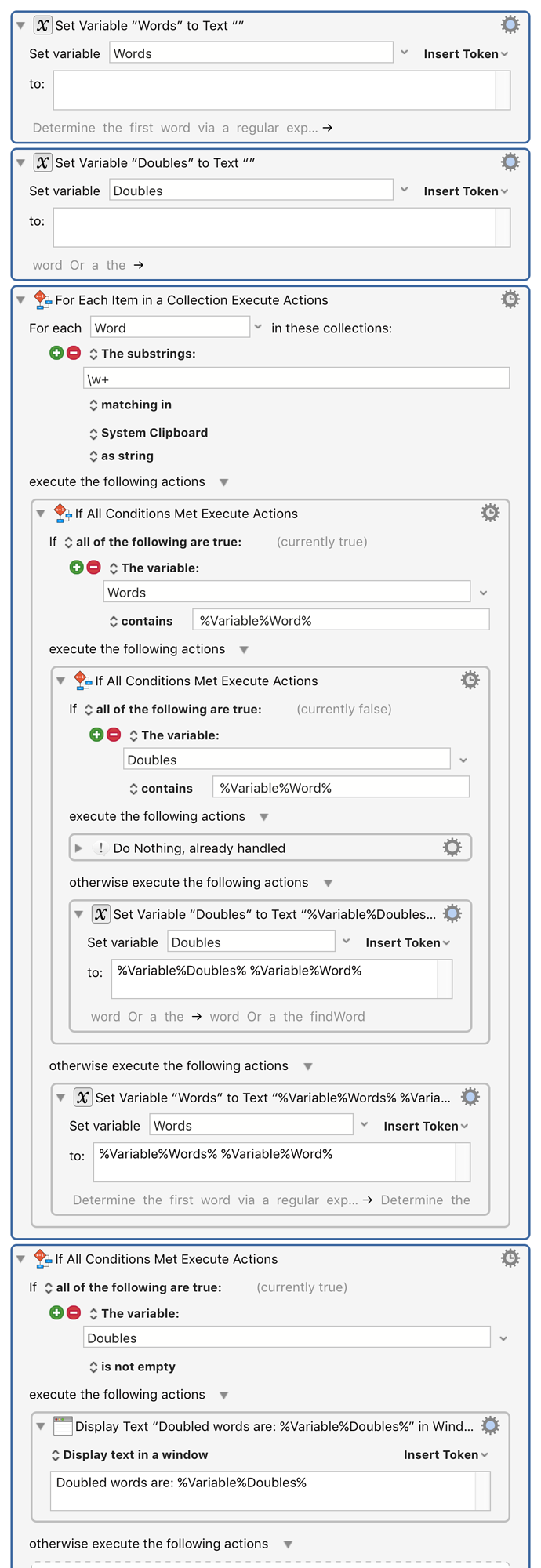
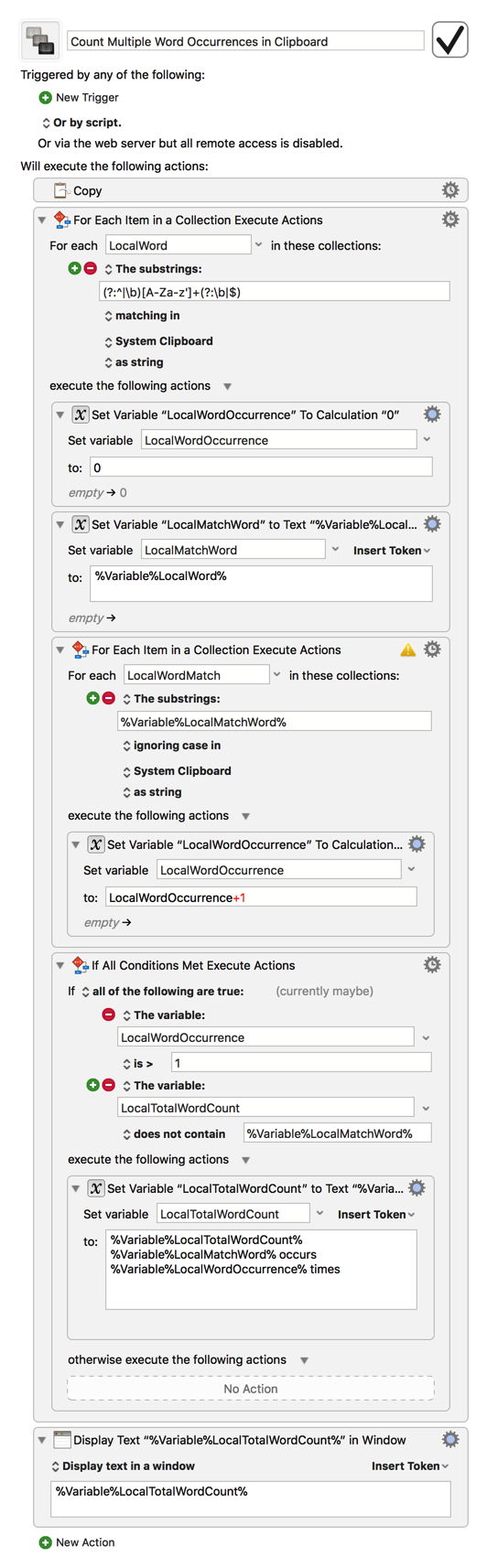
Here's another possible method I happened to come up with independently of @peternlewis's macro (though I'm glad to see there are some close similarities; perhaps a sign that great minds really do think alike? ):
(my regex is a tad more complex, perhaps unnecessarily so, but it does handle words with apostrophes like "isn't" "can't" and so on, so at least it has that going for it )
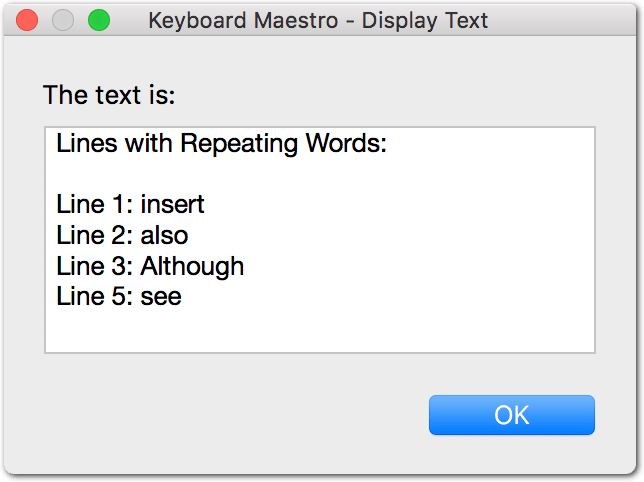
The route I decided to go with is to list all words that occur twice or more and exactly how many times they occur. When run on the example text given, it produces this:
The obvious downside with this approach is that it also shows words that must necessarily be repeated often within a given text (like "the" "it" "this" and so on) but at least it should suffice for finding multiply occurring words for now. If displaying common words like the examples just given too often becomes a problem, it can be modified fairly easily to include a blacklist of sorts so it doesn't include specified common words.
Please download the macro again (-> v1.1). I fixed a bug (variable was not reset) and set the minimum word length to 3 chars. (You can adjust this in the regex.)
Thank you all for your kind answers! I've decided to work with Peter's solution.
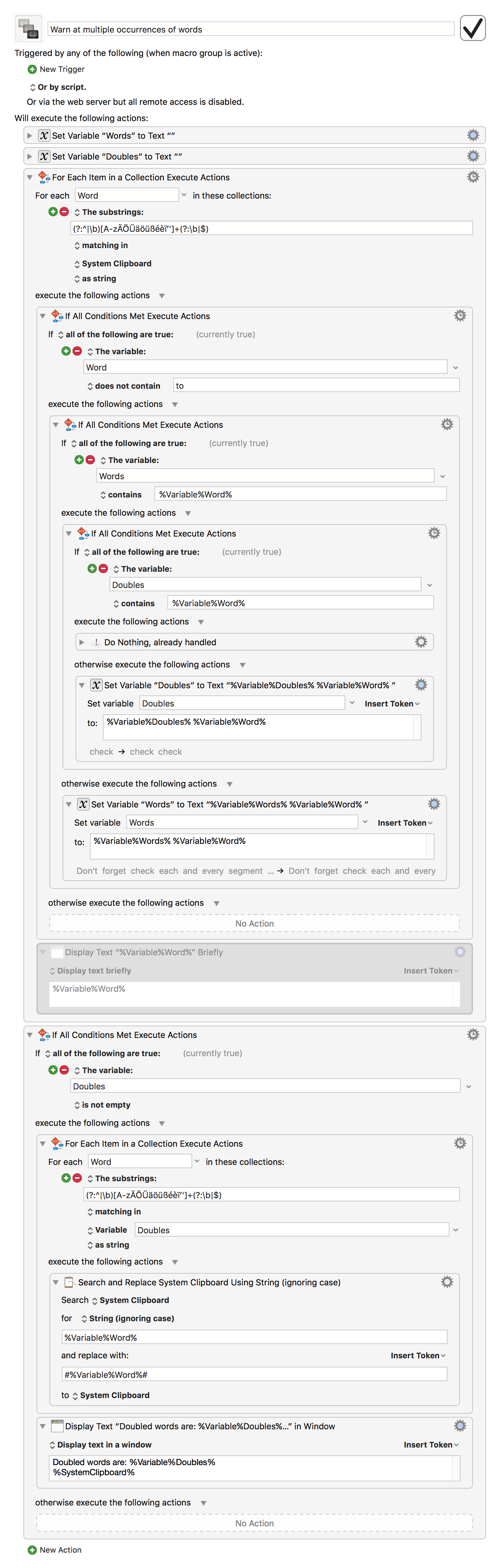
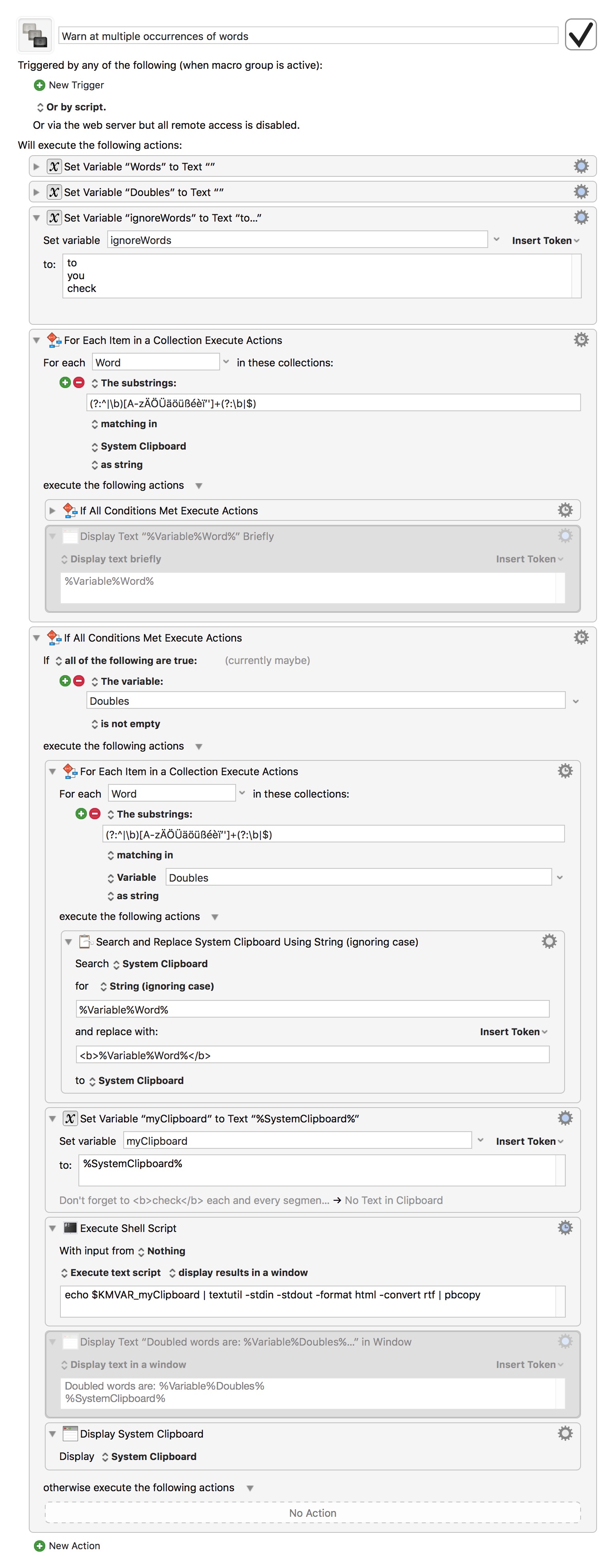
I'm trying to expand the macro with two features:
Ignore words on a list with words to ignore
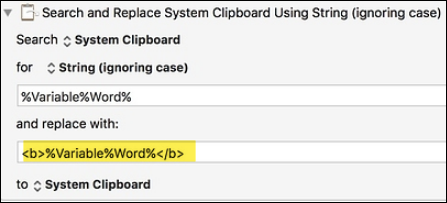
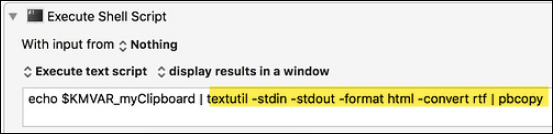
Surround all duplicates on the clipboard with a string to mark them (or even better: make them bold on the clipboard) and then display the original sentence with the duplicates marked.
I've now defined one word ('to') to ignore, but I'd like to list these words in a file (each word on a line). I've tried and tried but cannot get it working. I'd really appreciate a pointer here, where and how to insert the command(s) to check for words in a file like words_to_ignore.txt.

 ):
):
 )
)