Need help to create a macro to split large blocks of text into individual sentences.
Then I need to check each one of those sentences for the presence of groups of specific keywords.
Please help me.
I don't even know how to start
Need help to create a macro to split large blocks of text into individual sentences.
Then I need to check each one of those sentences for the presence of groups of specific keywords.
Please help me.
I don't even know how to start
Google on segmentation and SRX rules.
https://okapiframework.org/wiki/index.php/SRX
A sentence starts with an uppercase letter and ends with a full stop, question or exclamation mark. You’ll have to use a list of abbreviations to prevent segmentation errors.
Sentence boundaries vary (between languages and typesetting subcultures), and are a little tricky. [.!?] characters are easy enough to look for, but you have to check that they are at the end of a word, rather than, for example, in the middle of a number.
And where is the end of a word ? Do closing parentheses include or precede the sentence end punctuation ?
In any case, one approach is to:
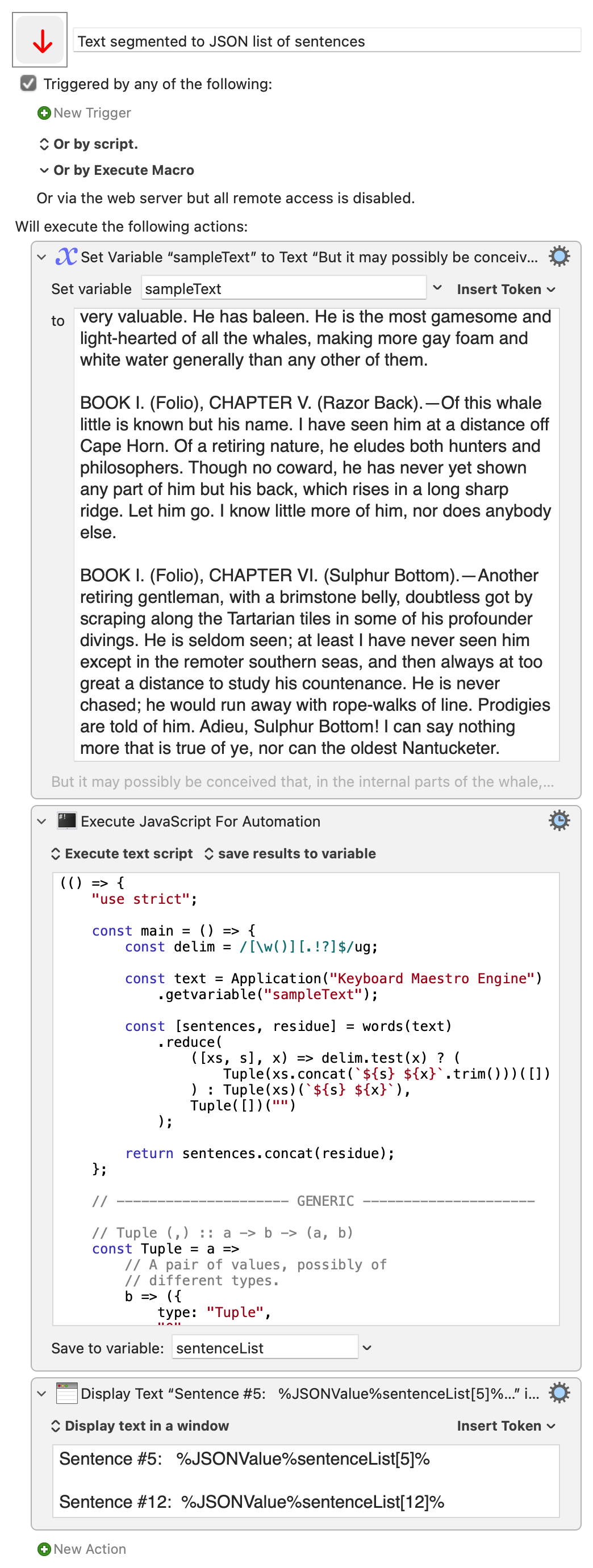
token:JSONValue [Keyboard Maestro Wiki]
For example:
Text segmented to JSON list of sentences.kmmacros (6.7 KB)
(() => {
"use strict";
const main = () => {
const delim = /[\w()][.!?]$/ug;
const text = Application("Keyboard Maestro Engine")
.getvariable("sampleText");
const [sentences, residue] = words(text)
.reduce(
([xs, s], x) => delim.test(x) ? (
Tuple(xs.concat(`${s} ${x}`.trim()))([])
) : Tuple(xs)(`${s} ${x}`),
Tuple([])("")
);
return sentences.concat(residue);
};
// --------------------- GENERIC ---------------------
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
// A pair of values, possibly of
// different types.
b => ({
type: "Tuple",
"0": a,
"1": b,
length: 2,
*[Symbol.iterator]() {
for (const k in this) {
if (!isNaN(k)) {
yield this[k];
}
}
}
});
// words :: String -> [String]
const words = s =>
// List of space-delimited sub-strings.
s.split(/\s+/u);
return JSON.stringify(main(), null, 2);
})();
Very nice and useful!
Segmentation algorithms do absolutely need a way to handle abbreviations. The mechanism needs to be case sensitive and treat the left side of an abbreviation as word boundary. Abbreviations can be of mixed case and contain spaces. They can contain numbers and 'special' characters, e.g. Greek letters. After the abbreviation, a normal space can follow:
They were looking at examples etc. to study.
A part of my list containing German abbreviations:
(s.
4kt.
6kt.
a. A.
a. a. O.
a. a. S.
a. d.
A. d. Hrsg.
A. d. Ü.
a. E.
a. F.
a. G.
a. gl. O.
a. n. g.
a. S.
a.A.
a.a.O.
a.a.S.
a.d.
A.d.Hrsg.
A.d.Ü.
a.E.
a.F.
a.G.
a.gl.O.
a.n.g.
a.S.
Abb.
Abbr.
Abf.
abg.
abgebr.
Abgel.
Abh.
abk.
Abl.
Abr.
Abs.
Abschl.
Abschn.
absol.
Abt.
Abw.
abwinkl.
Abz.
Abzg.
acc.
Achs-D.
Adir.
adj.
Adr.
adv.
Afr.
afrik.
Ag.
agg.
Aggr.
Ahg.
The best way is to store the abbreviations in an external file. Super de luxe would be a mechanism to add abbreviations on the fly, once they are spotted by the user in a checking window.
LT_segment.srx.zip (26.0 KB)
oT_defaultRules.srx.zip (13.4 KB)
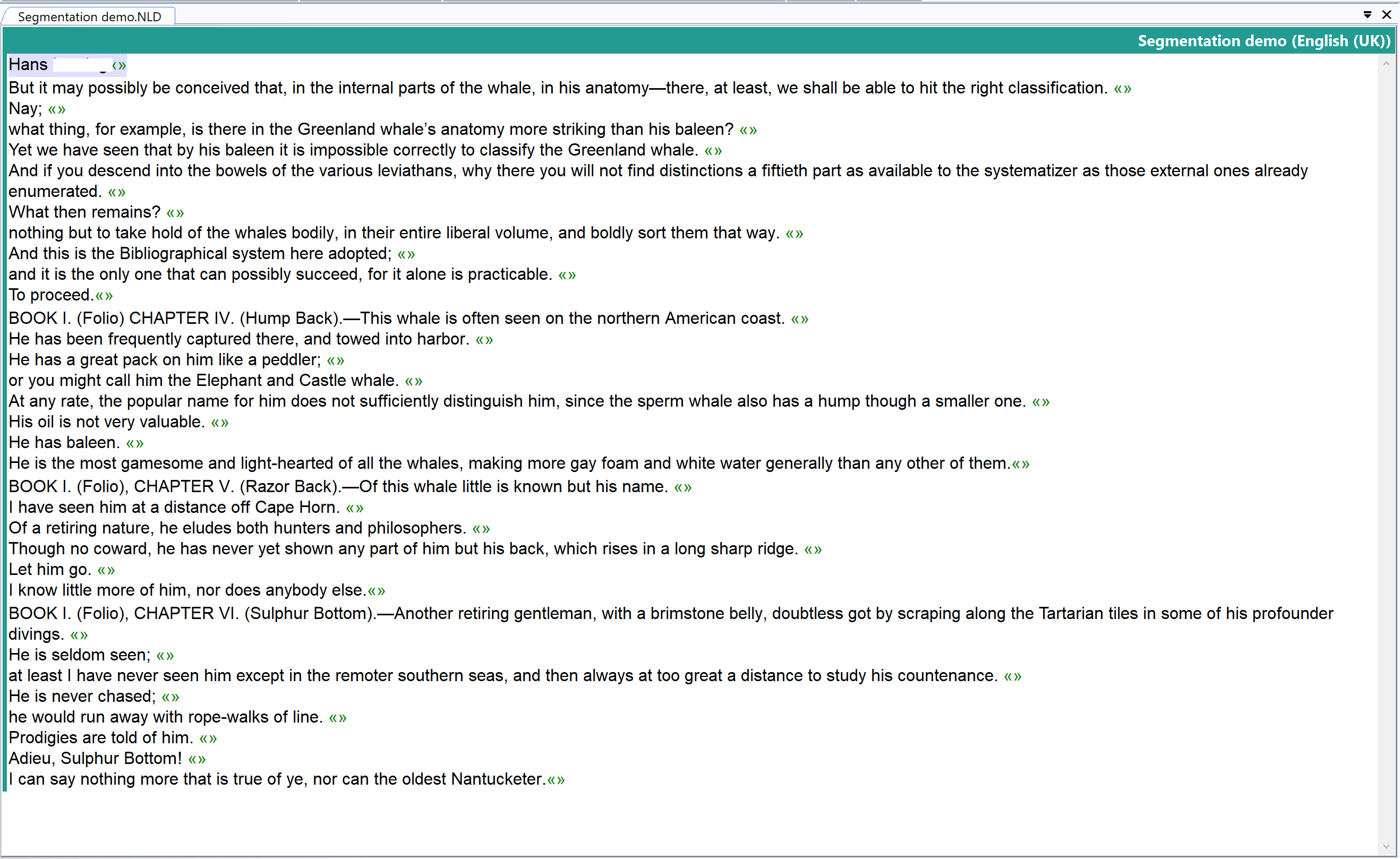
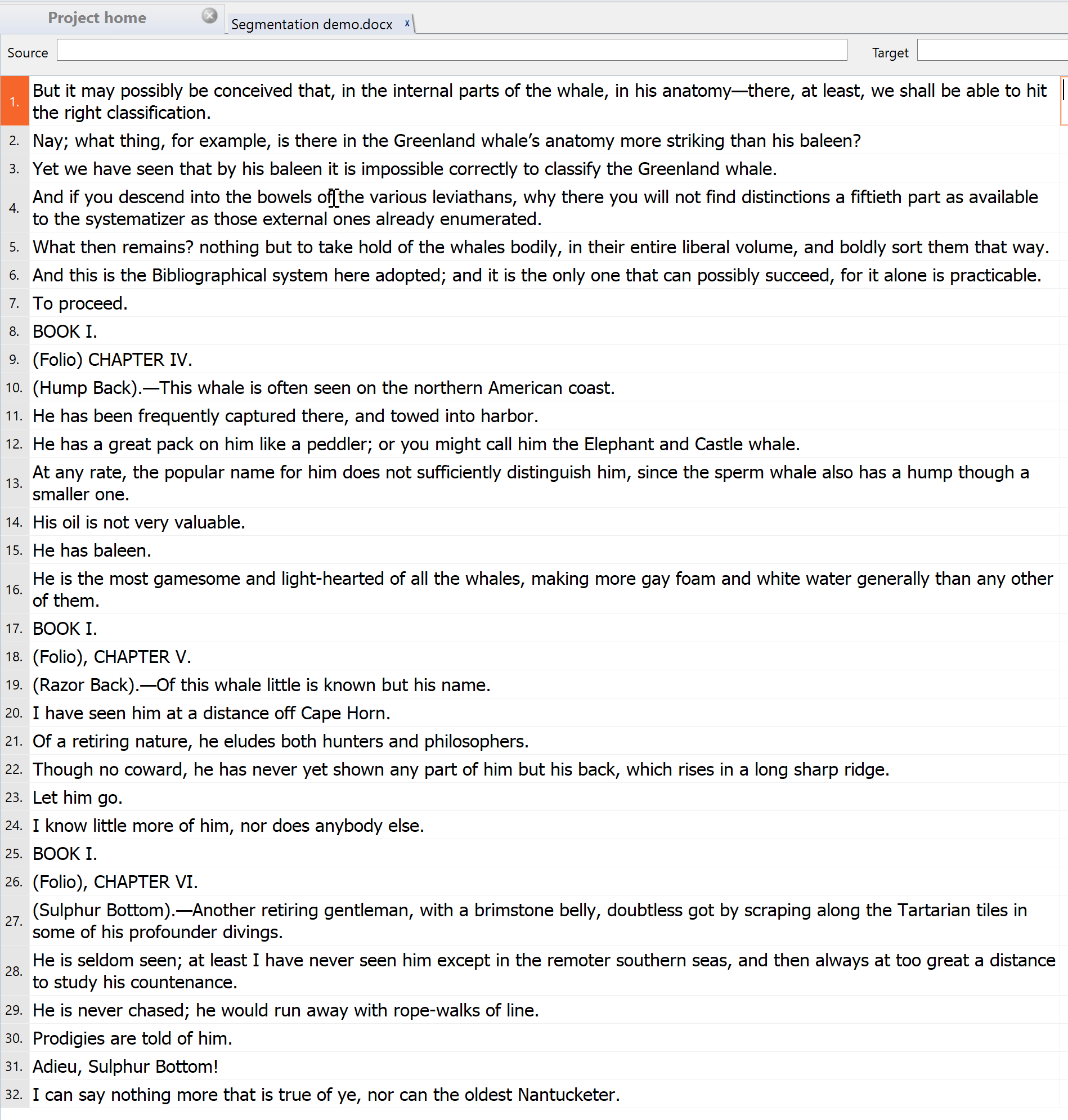
BTW: IMO, Sentence #12 should read '(Hump Back).'.
Good example – we would then have the problem of a next sentence which starts (probably eccentrically) with a long dash rather than a letter –This whale.
No shortcut alternatives, alas, to concrete analysis of the patterns in a particular set of texts.
Or to put it another way, probably more a job for probability-based machine learning over a massive corpus than for a handful of black and white deductive rules.
I don’t think so. The number of rules is limited and widely used in the translation industry.
Sure, you can do quite well with a finite number of rules if the corpus itself is finite and well-defined (contemporary commercial material in particular languages, for example).
But as we saw with the Herman Melville example above, there is no universal pattern of simple rules that will yield consistently solid hits across everything found in the Library of Congress, the Deutsche Nationalbibliothek, etc
(The assumptions are always parochial – Roman unicode points for stop, exclamation and question will all fail with contemporary commercial CJK material, for example)
Adding delimiters on the fly would make things feasible. A kind of presegmentation in a preview window. That’s how it’s often done.
Because I was curious, I imported the example text in three major CAT tools. The first one offers on the fly abbreviation checking:
Based on my selections, it came up with this segmentation result:
The market leader came with:
This is without human interference and clearly suboptimal for the purpose of translation.
The Pepsi CAT tool (#2 challenger on the market) made some better segmentation assumptions:
But it had clearly problems to interpret the em dash too ...
BTW: It would be nice to have an all KM variant of a segmentation algorithm too, so that I could try myself to embed handling of abbreviations.
At Proz.com someone posted:
Objective-C
Core Foundation and Cocoa on MacOS. Not very portable, but it illustrates the general approach: An object that slices up a string based on delimiters (in this case built into CFStringTokenizer). This should work across many languages and writing systems. If locale was irrelevant we wouldn't need the tokenizer and could reduce the code to one line or a couple of lines.
NSMutableArray<NSString*>* sentences = [NSMutableArray array];
CFLocaleRef locale = CFLocaleCopyCurrent ();
NSString* aStr = @"A string? With some sentences. In it!";
CFStringTokenizerRef tokenizer = CFStringTokenizerCreate(kCFAllocatorDefault, (__bridge CFStringRef) aStr, CFRangeMake(0, aStr.length), kCFStringTokenizerUnitSentence, locale);
for(;;)
{
CFStringTokenizerTokenType tokenType = CFStringTokenizerAdvanceToNextToken (tokenizer);
if(tokenType != kCFStringTokenizerTokenNone)
{
CFRange cfr = CFStringTokenizerGetCurrentTokenRange (tokenizer);
[sentences addObject:[aStr substringWithRange:NSMakeRange(cfr.location, cfr.length)]];
}
else
{
break;
}
}
CFRelease(tokenizer);
CFRelease(locale);
Personally, I cannot read this.