I have two files (a.txt and b.txt) that have some words in common if you compare them case-insensitively:
Haus
Hund
bellen
Mist
schattig
Dusche
Wand
And:
huis
hond
bellen
mist
schattig
muur
wand
televisie
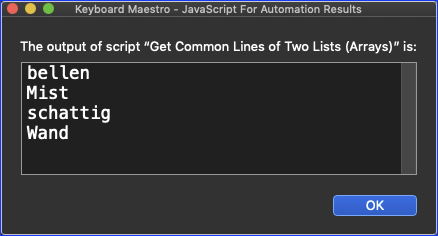
I'd like to create a third file (c.txt) that contains all words from file a.txt that appear (if case is ignored) in file b.txt:
Mist
schattig
bellen
Wand
Task: I'd like to create a list of all words from one language that also exist in another language (so-called homographs). The file a.txt will contain about 500,000 words.
Could somebody please help me with a script, or even a KM solution?