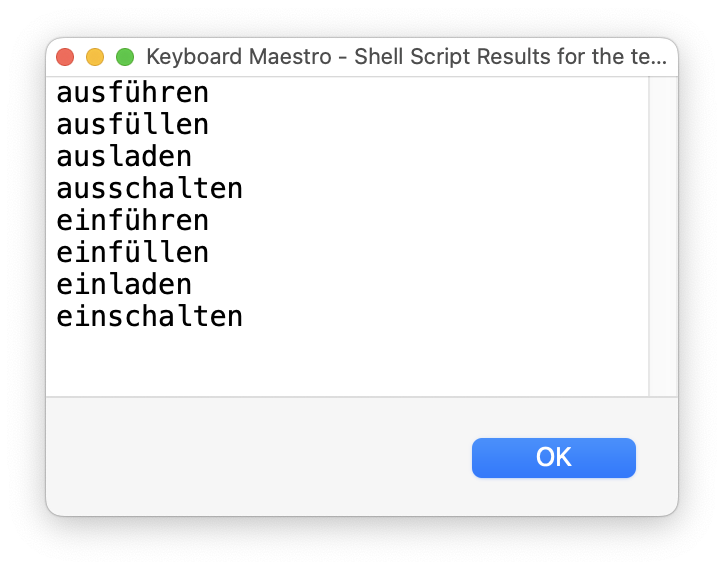
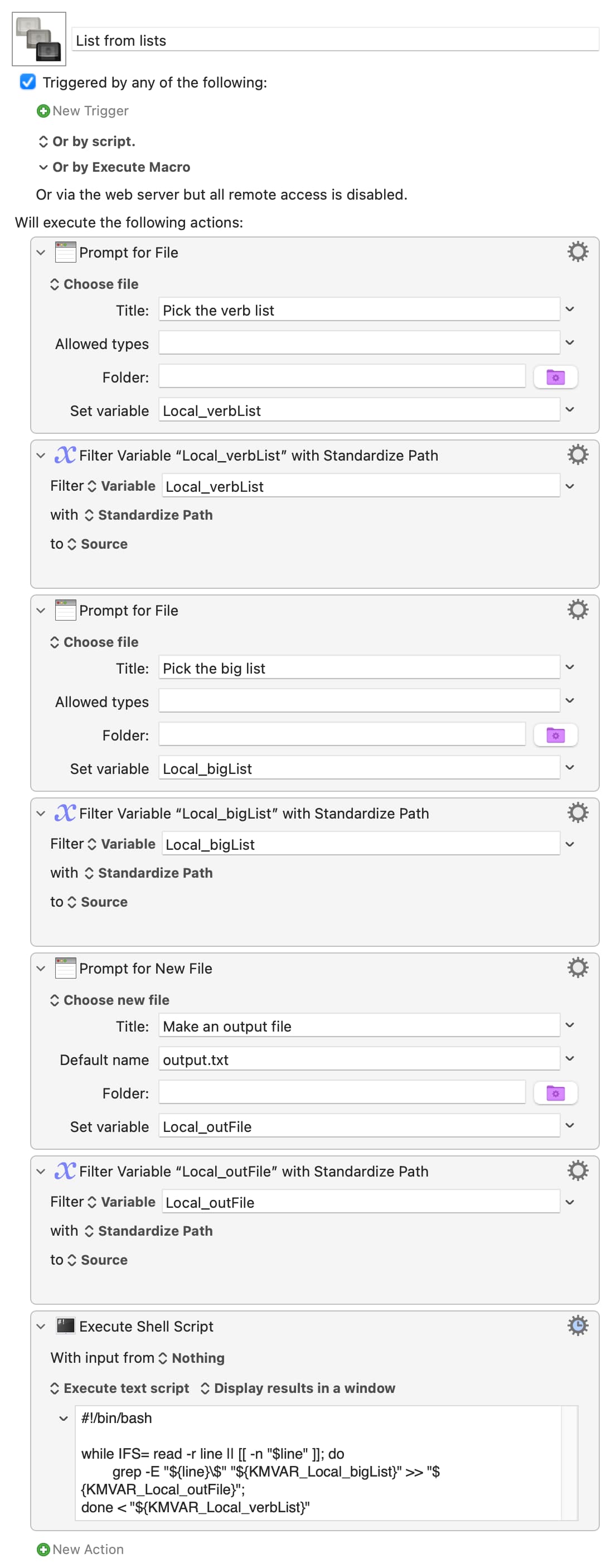
This is one of those spots where KM's ability to use the shell makes this rather simple—I only know this because I had this exact same issue years ago, with an early version of my Quick Web Search macro. I fought regex and KM's Search command before someone (pre ChatGPT days, so not sure who :)) pointed out grep as a solution.
Assuming your 850,000 words are in a file named The Words.txt in the /tmp folder, this should work as a shell script action, saving results to a variable:
Putting aside the issue of files, and assuming, for the moment, the use of
a regular expression (not the only option, at that scale),
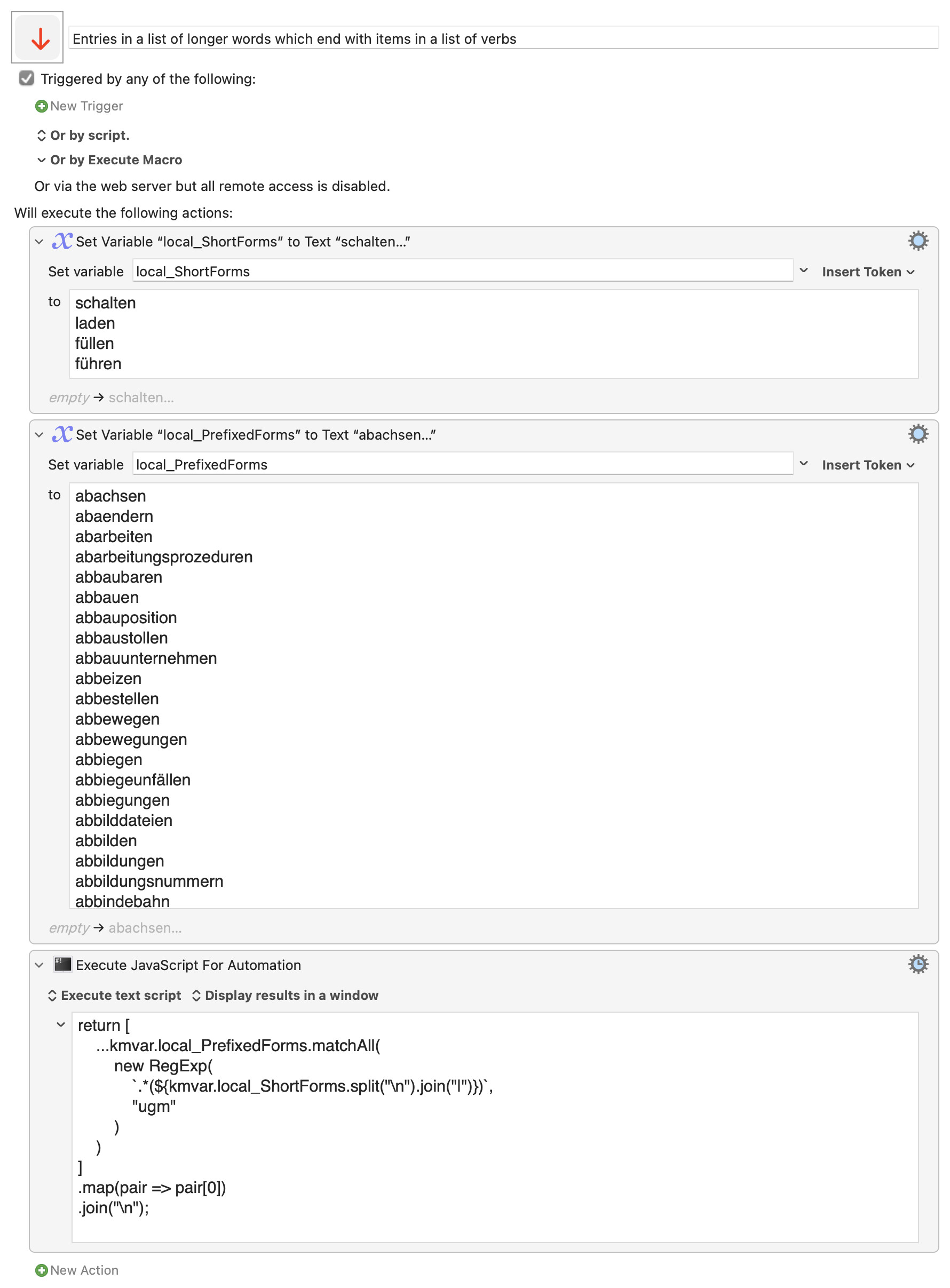
I think you will probably need to automate the creation of any regular expression. (850 alternatives is a lot to assemble by hand, with a bit too much room for accident on the way).
Automating the assembly of a regular expression is easier with a scripting language like Python or JavaScript.
Here's one JS approach, (and there may also be an argument for an approach which puts aside regular expressions altogether):