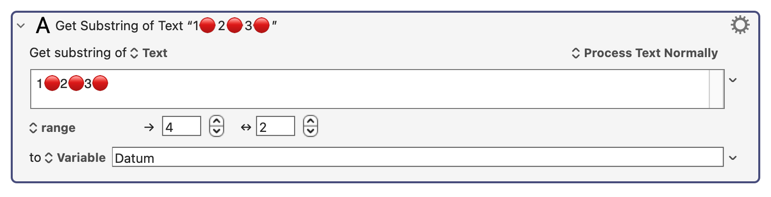
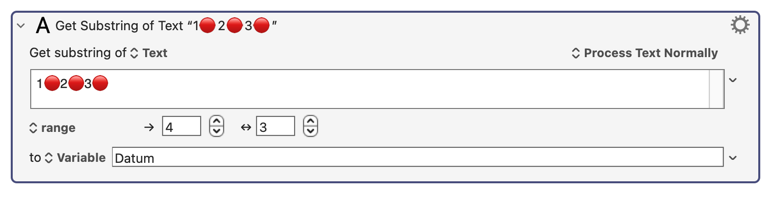
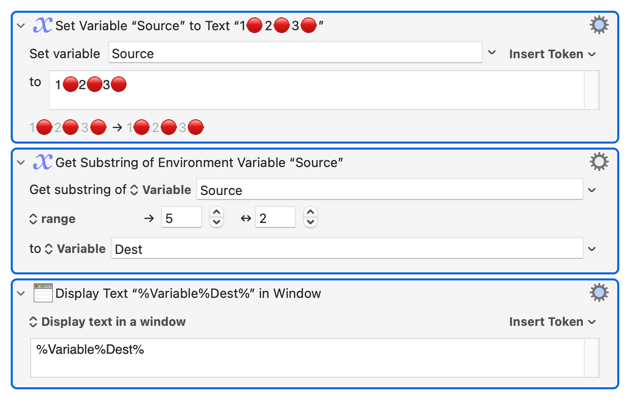
It's very nice that KM supports emojis in variables, which I presume means that KM supports different character sets like UTF-8 and UTF-16 (which require multiple bytes per emoji.) But I wish KM could handle some string manipulation better. For example, this:
... produces a two character string, a two and a red circle. I have a general idea why this is happening, so I'm not soliciting an explanation here, but regardless of the underlying explanation, I think that the first action above should produce an error, or even better, it should produce two visible characters. In other words, KM should do something useful (or at least cause an error) when I try to index a Unicode string incorrectly.
In some KM actions, taking a substring of a text variable containing emojis seems to split the emoji's encoding resulting in actual erroneous characters, which is even worse than producing an empty string. I don't ever want to decode a Unicode character into its components.
I don't know very much about Unicode character sets, and I'm not sure I really want to. However I would point out that there is very little information about character set supports on the KM wiki, at least nothing useful if I type "character sets" or "UTF-8" into the search box. Perhaps there should be more information, at least related to how Unicode impacts variables and actions in KM.
Hmm, at the very least, there should be a way for me to determine if a variable contains a non-ASCII character set, so I can prevent errors from occurring.
This doesn't make sense, UTF-8 and UTF-16 are encodings, not character sets.
Underlying strings in Keyboard Maestro are either UTF-8 or NSString.
When operating on strings, they are generally NSString which considers UTF-16 characters. So indexes are based on those ranges, not ranges of combined characters and you'll need to take that in to account when using anything in Keyboard Maestro that relates to position or length of substrings. To do otherwise (to treat indexes as based on composed characters) would be prohibitively expensive for such simple operations.
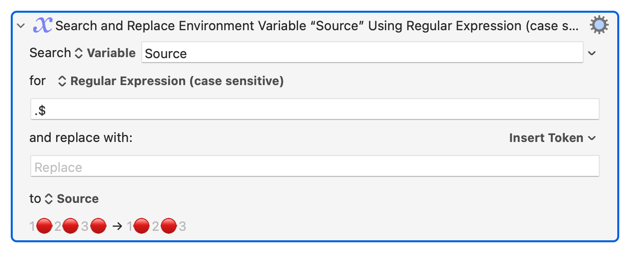
Displays the second .
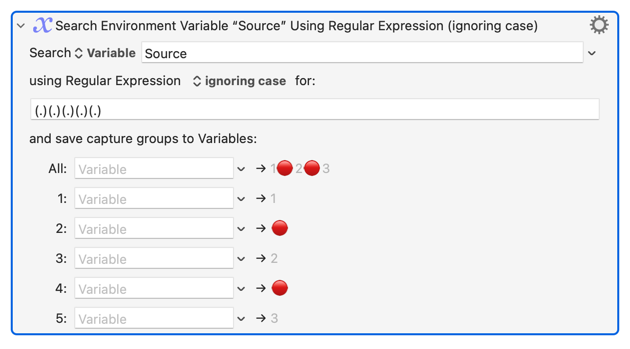
Note that regular expressions work on composed characters, so you can use this for example:
I want my macros to be able to detect if a sting contains Unicode characters so that I can provide an appropriate error message. Or perhaps it would also suffice if there was a way to know if a specific character of a string (at least the first one) was a Unicode character, and how long it was in terms of bytes, so that I could properly index individual characters.
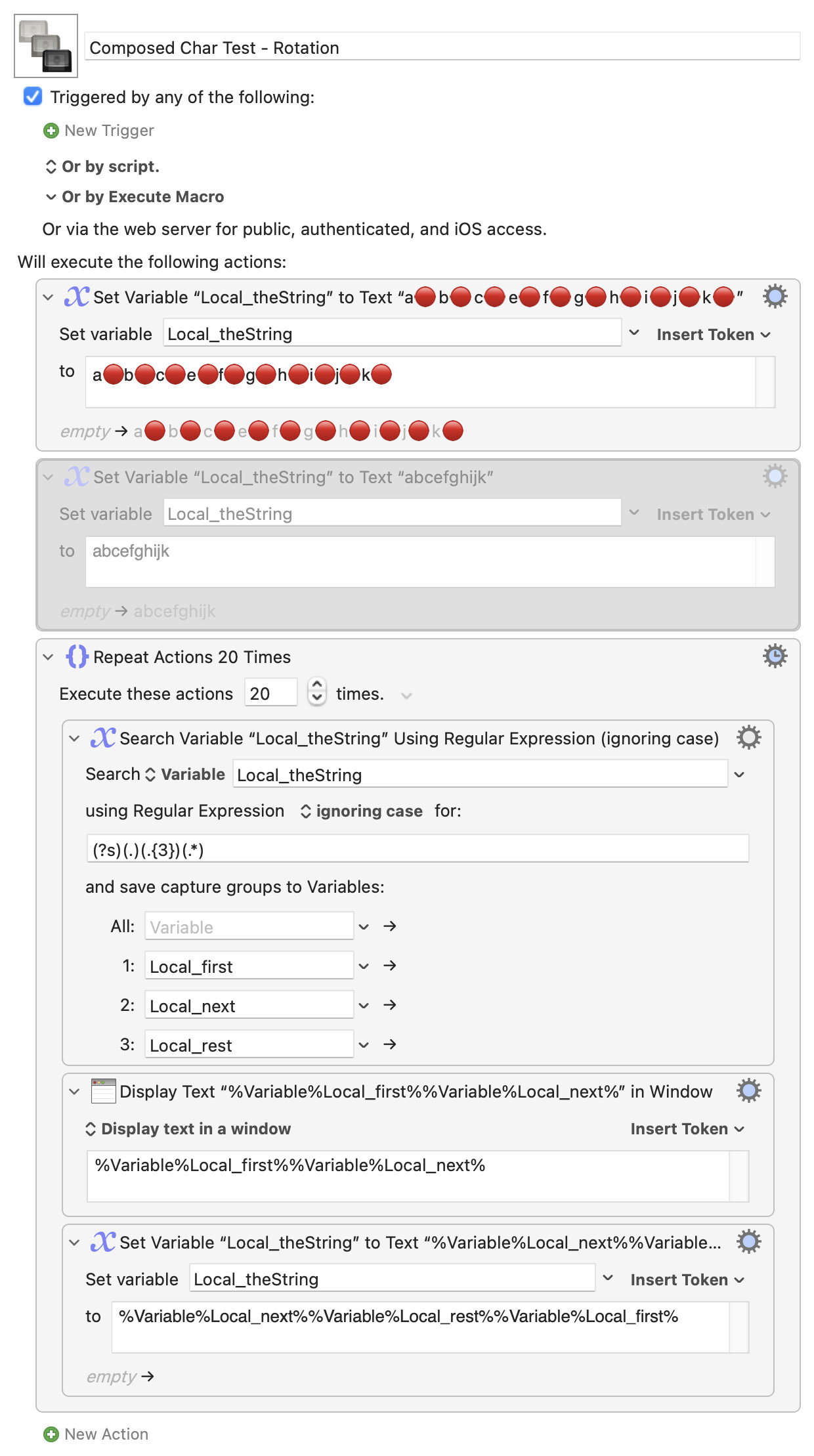
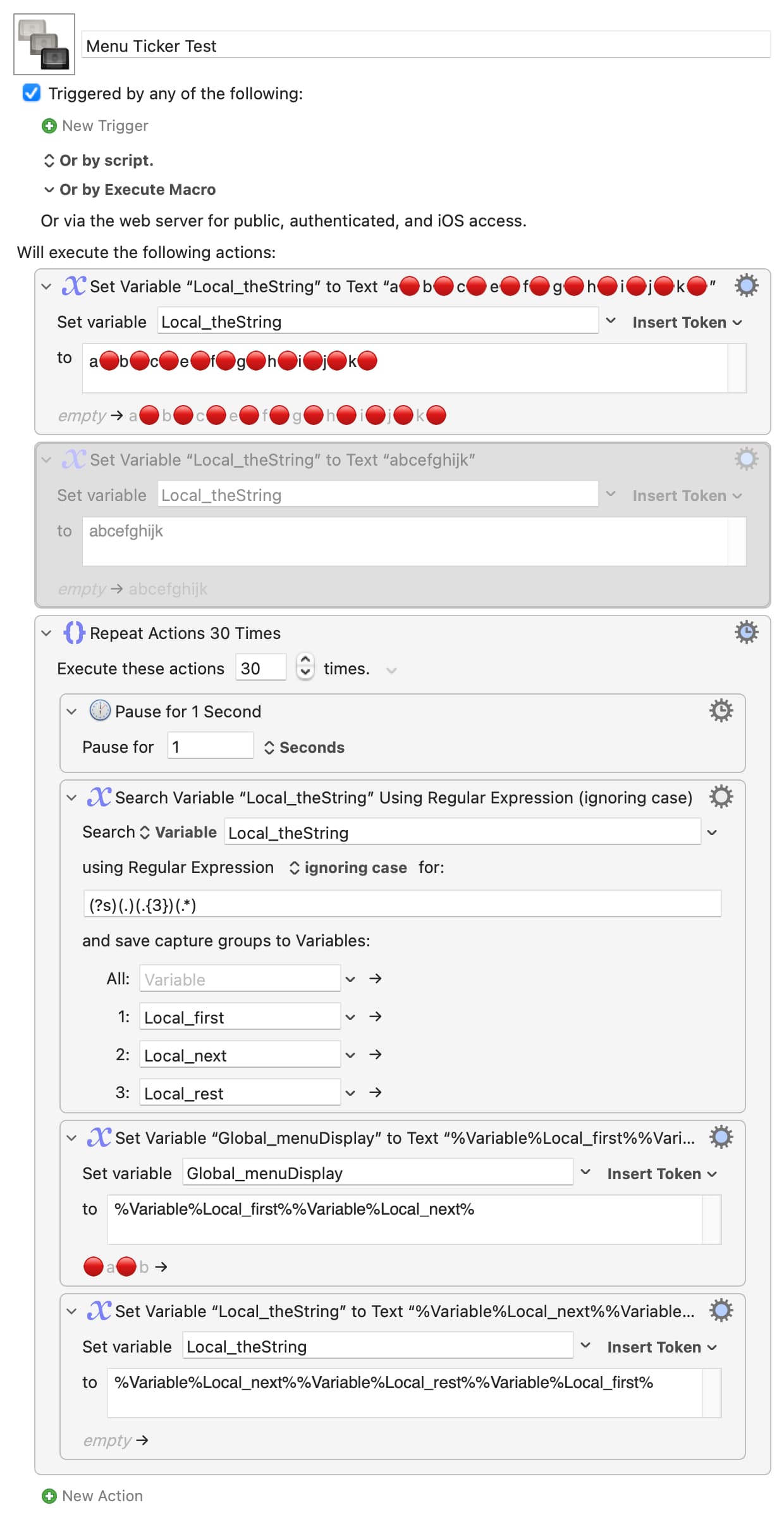
The specific reason that I need this is that I wrote a very nice macro that allows me to display strings that are too long in the Display Progress action by rotating the long string in the limited window. But when I do this, emoji characters are coming through "broken" at certain points because my code is breaking the emoji up into its constituent parts.
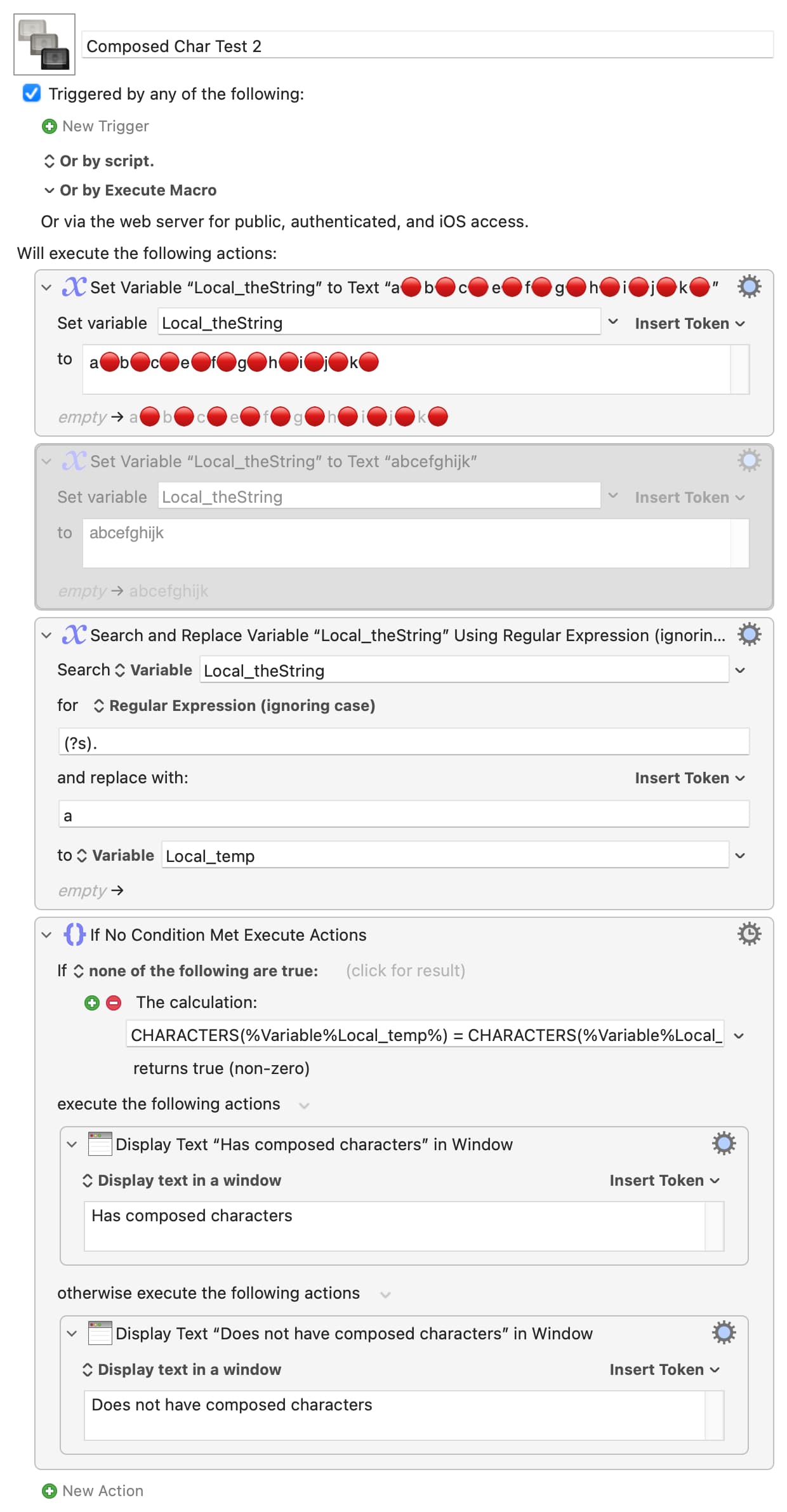
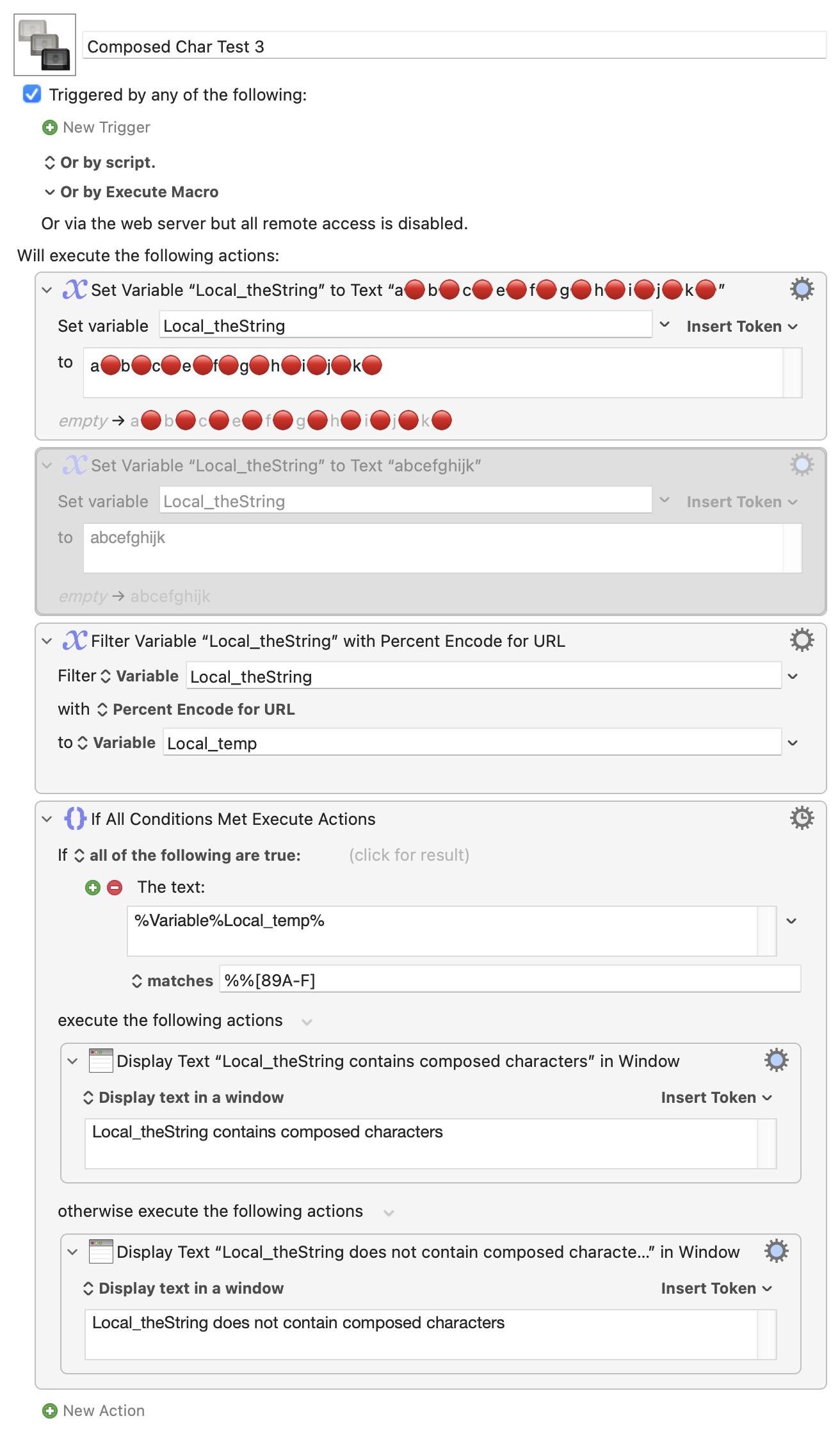
AppleScript does consider a composed character to be a single character. So you could test length of theString against KM's CHARACTERS(%Variable%Local_theString%):
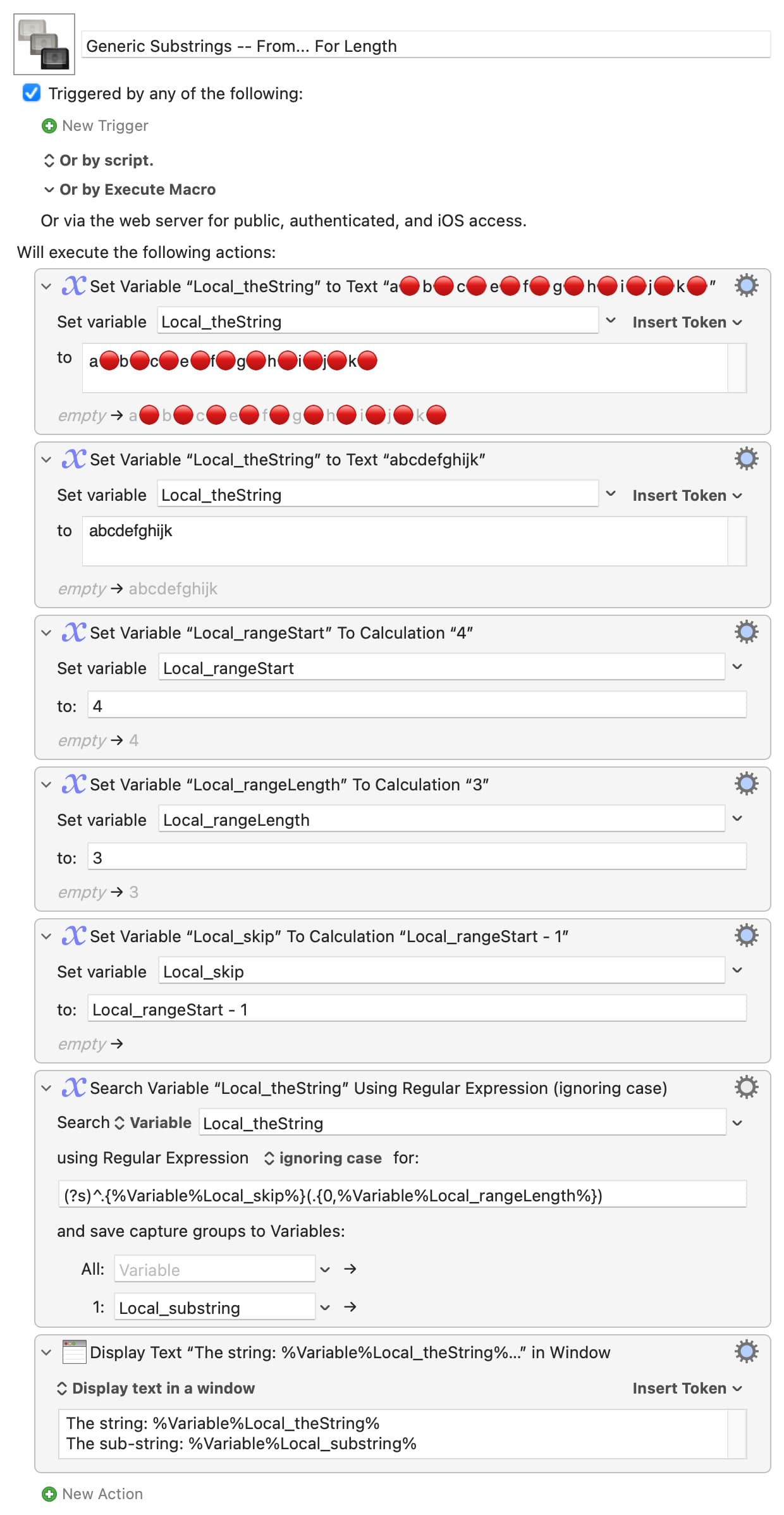
I tried to think of a way to do this with a "For Each..." across the string, more analogous to a sub-string operation, but 1) the decision-making bit made my head hurt, especially when it came to wrapping round, and 2) I think it'll be considerably slower than any of the above.
...and the other options will be a matter of maths -- remembering that you can only include one level of token inside the regex text field, which is why the -1 calculation in the first example had to be done in a separate action.
Also, how long it was in terms of bytes requires knowing the encoding. é could be one byte (in Latin character sets), or two bytes in UTF-16 or a different two bytes in UTF-8, or four bytes in UTF-32, or decomposed it could two characters, which would be four bytes in UTF-16 and I have no idea how many in UTF-8.
Yes, that is going to be difficult to do with unicode characters that take more than one code point in NSStrings.
How are you calculating the display width?
You can remove the last character with:
Keyboard Maestro, of course, has all thise code internally (determine the width of a string, truncate strings to fit a width (including adding the … to the middle or the end) and such), but I don't believe any of it is exposed.
I don't actually need to worry about the end of the string, since the Display Progress Bar action visually truncates the last characters. The only problem I have is at the start of the string. Even so, it's just a small display glitch that disappears in about 0.1 seconds, so it's not a big deal.
I think your suggestion of breaking up the string with the Search Using Regular Expression will solve the issue.
Potentially another method. Only basic tests done, so YMMV.
If only testing the string we just need to check for the presence of multi-byte characters and, if I was reading various sources correctly last night, all single-byte characters have a byte value < 128 while all multi-byte characters have all byte values >= 128...
URL encoding the string will result in any (and only) multi-bye characters being represented by %80 or higher. So: