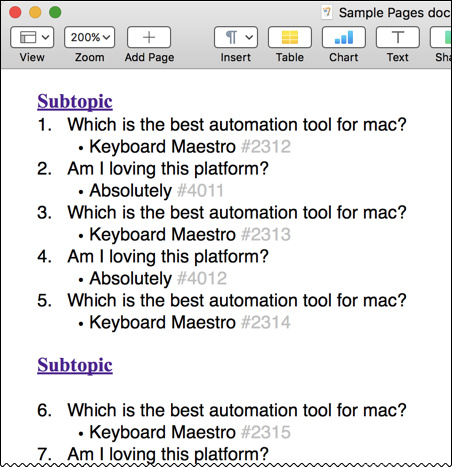
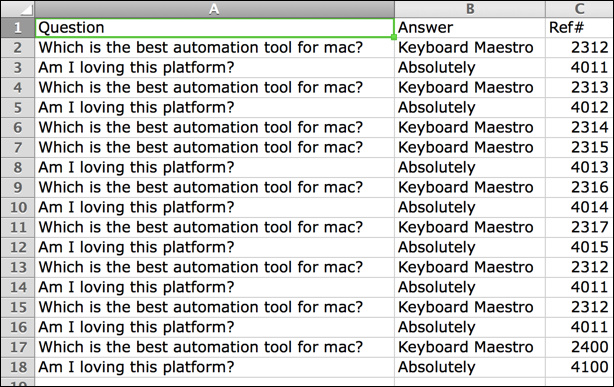
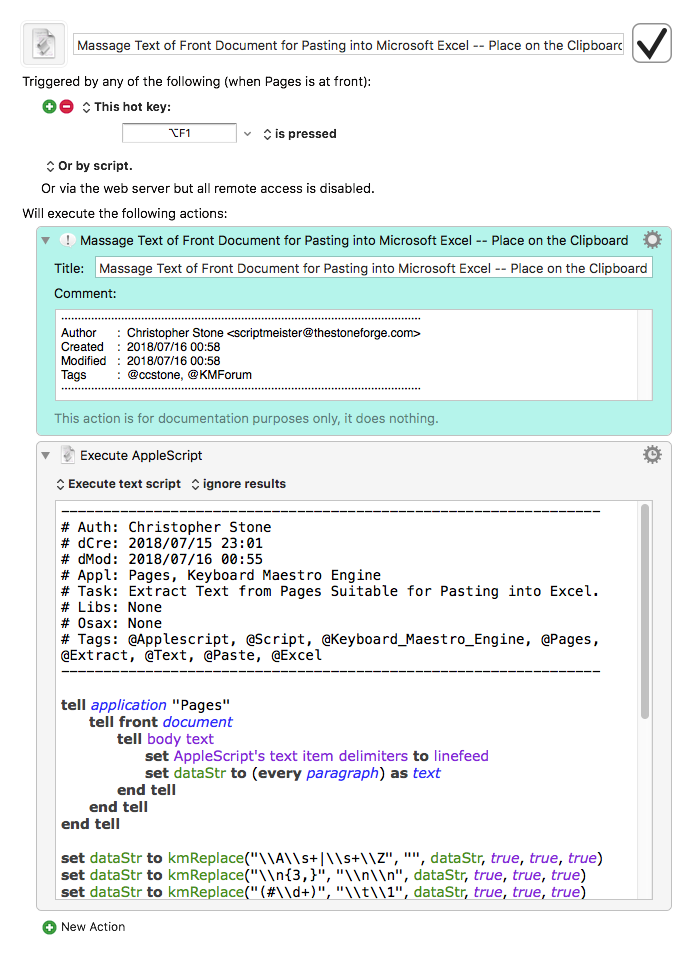
Rich harvest of good solutions !
Just in case this question (or the tags attached to it) provide a useful reference for later searchers, here is one more approach:
- also starting with the bodyText, but
- leaving Regexes aside, and
- writing in JS. (tho AS would work just as well)
Taking only the body text lines which are questions or answers,
filter(
x => x.includes('?') || x.includes('#'),
lines(strText)
)
(see filter, lines)
partitioned, on the basis of a test, into a pair (or 'tuple') of lists:
tpl = partition(
x => x.includes('?'),
filter(
x => x.includes('?') || x.includes('#'),
lines(strText)
)
),
(see partition)
In other words partitioning the filtered lines into:
- a list of questions, and
- a list of answers.
qs = fst(tpl),
as = snd(tpl)
(see fst, snd)
- Having these two lists allows for a check that the count of questions and answers matches, and for
- returning either a usable Excel translation in a Right channel,
- or a helpful message to the user in a Left channel.
(Values which can have either a Left or Right type of content turn up, for example, as
return qs.length === as.length ? Right(
// Translation to an Excel-readable format ...
) : Left(
"Mismatch in counts of '?' and '#' on this page."
);
(see Left, Right, and, for further down, bindLR)
From our two matching sets of questions and answers,
we can obtain a single 'zipped' list of matching Q&A pairs:
zip(qs, as)
(see zip)
and mapping some kind of string-constructing function over that list of pairs,
gives us a list of (for example, tab-delimited) lines.
map(
pair => `${fst(pair)}\t${
snd(pair).split(' #').join('\t')
}`,
zip(qs, as)
)
(see map)
A concatenation of the list of lines (as a single string) with a prepended header,
'Question\tAnswer\tUnique ID\n' +
unlines(
map(
pair => `${fst(pair)}\t${
snd(pair).split(' #').join('\t')
}`,
zip(qs, as)
)
)
(see unlines)
produces a usable result for the Right channel,
Right(
'Question\tAnswer\tUnique ID\n' +
unlines(
map(
pair => `${fst(pair)}\t${
snd(pair).split(' #').join('\t')
}`,
zip(qs, as)
)
)
)
and all of this can be wrapped in a context which returns either that usable Right value or a Left channel message that no document is open in Pages,
const
ds = Application('Pages').documents,
lrTabbed = bindLR(
0 < ds.length ? (
Right(ds.at(0).bodyText())
) : Left('No document open in Pages'),
strText => {
const
tpl = partition(
x => x.includes('?'),
filter(
x => x.includes('?') || x.includes('#'),
lines(strText)
)
),
qs = fst(tpl),
as = snd(tpl);
return qs.length === as.length ? Right(
'Question\tAnswer\tUnique ID\n' +
unlines(
map(
pair => `${fst(pair)}\t${
snd(pair).split(' #').join('\t')
}`,
zip(qs, as)
)
)
) : Left(
"Mismatch in counts of '?' and '#' on this page."
);
}
)
bindLR takes two arguments:
- An Either value (i.e. either a Left(something) or a Right(something))
- a function.
If the either value is a Left, bindLR just passes it straight on, unchanged.
If the either value is a Right, then bindLR:
- extracts its contents from the Right wrapper,
- applies the function to it,
- returns the result, re-wrapped as Right(something).
As a result, nested uses of bindLR:
- Pass anything in the Left channel straight through to the final result, or
- continue a pipeline of function applications through the Right channel.
( This pipelining of optional values turns out to be simplifying and very useful, and is becoming central to code-structuring in newer languages like Swift and Rust )
Given either a message or some tab-delimited text, bindLR can add a further stage to the pipe-line, either passing on a message, or passing tabbed text into the clipboard:
(Full script for a KM Execute a Javascript for Automation action)
(() => {
'use strict';
const main = () => {
const
ds = Application('Pages').documents,
lrTabbed = bindLR(
0 < ds.length ? (
Right(ds.at(0).bodyText())
) : Left('No document open in Pages'),
strText => {
const
tpl = partition(
x => x.includes('?'),
filter(
x => x.includes('?') || x.includes('#'),
lines(strText)
)
),
qs = fst(tpl),
as = snd(tpl);
return qs.length === as.length ? Right(
'Question\tAnswer\tUnique ID\n' +
unlines(
map(pair => `${fst(pair)}\t${
snd(pair).split(' #').join('\t')
}`,
zip(qs, as)
)
)
) : Left(
"Mismatch in counts of '?' and '#' on this page."
);
}
),
lrResult = bindLR(
lrTabbed,
strTabbed => {
// standardAdditions :: () -> Application
const standardAdditions = () =>
Object.assign(Application.currentApplication(), {
includeStandardAdditions: true
});
return (
console.log(strTabbed),
standardAdditions().setTheClipboardTo(strTabbed),
Right('Tabbed text copied to clipboard from Pages Q&A')
);
}
);
return lrResult.Left || lrResult.Right;
};
// GENERIC FUNCTIONS --------------------------------------
// https://github.com/RobTrew/prelude-jxa
// Left :: a -> Either a b
const Left = x => ({
type: 'Either',
Left: x
});
// Right :: b -> Either a b
const Right = x => ({
type: 'Either',
Right: x
});
// Tuple (,) :: a -> b -> (a, b)
const Tuple = (a, b) => ({
type: 'Tuple',
'0': a,
'1': b,
length: 2
});
// bindLR (>>=) :: Either a -> (a -> Either b) -> Either b
const bindLR = (m, mf) =>
m.Right !== undefined ? (
mf(m.Right)
) : m;
// filter :: (a -> Bool) -> [a] -> [a]
const filter = (f, xs) => xs.filter(f);
// fst :: (a, b) -> a
const fst = tpl => tpl[0];
// lines :: String -> [String]
const lines = s => s.split(/[\r\n]/);
// map :: (a -> b) -> [a] -> [b]
const map = (f, xs) => xs.map(f);
// partition :: Predicate -> List -> (Matches, nonMatches)
// partition :: (a -> Bool) -> [a] -> ([a], [a])
const partition = (p, xs) =>
xs.reduce(
(a, x) =>
p(x) ? (
Tuple(a[0].concat(x), a[1])
) : Tuple(a[0], a[1].concat(x)),
Tuple([], [])
);
// snd :: (a, b) -> b
const snd = tpl => tpl[1];
// unlines :: [String] -> String
const unlines = xs => xs.join('\n');
// zip :: [a] -> [b] -> [(a, b)]
const zip = (xs, ys) =>
xs.slice(0, Math.min(xs.length, ys.length))
.map((x, i) => Tuple(x, ys[i]));
// MAIN
return main();
})();