I hope everybody is having a wonderful time self-isolating and staying safe!
I have some data in a spreadsheet (CSV) file that I need to convert some data because it's destination requires the time codes to be in a 24-hour format for some reason.
To make this simple I can isolate all of the data that needs to be converted for the moment and just do the conversion via KM. (I think this would be the easiest way, I'm open to alternative methods)
I did manage to find some python code that will spit out a converted time, however, I'm not sure the best approach to do this automagically.
So assuming I have the file as timestoconvert.csv
Would it be easier to find some Regex to do this?
The formatting of the times appears as time ranges in each line
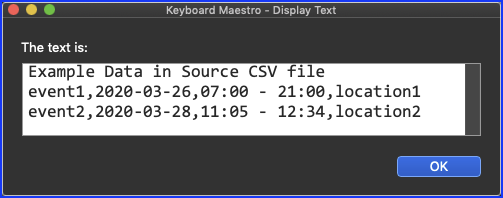
ex. 7:00 am - 9:00 pm
This is an example of the python code that works for a one off..
Since I can not go out, I spend everyday with Keyboard Maestro. It's really a good APP
I don't have experience with csv file. But if the line is like “7:00 am - 9:00 pm”.
You can use “search Using RegEx” macro in KM to extract first Time and last Time.
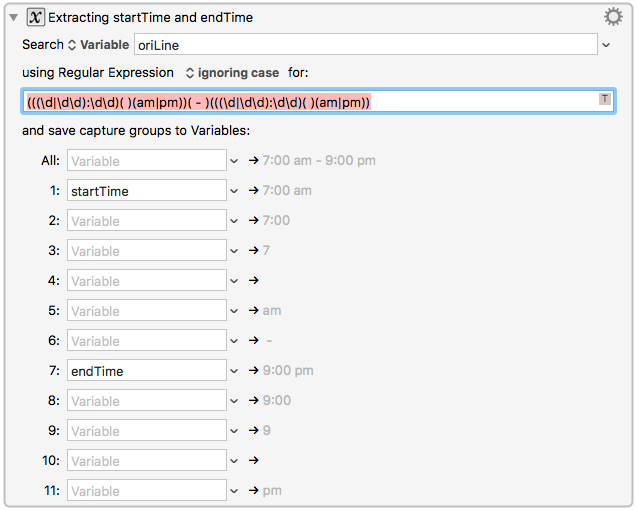
Problem 1: Extracting Time String From the Line
You can use "search using RegEx" macro.
the RegEx should be:(((\d|\d\d):\d\d)( )(am|pm))( - )(((\d|\d\d):\d\d)( )(am|pm))
It would be best for you to provide real-world examples of your CSV file BEFORE and AFTER the changes you want. The before and after formats will dictate the best approach to be used.
So, assuming that is an accurate representation of your times, I have developed the following Macro as an example to help get you started.
I was trying to frame out a solution, yours looks much more robust at first glance compared to where I am at currently.
Currently the file I'm cranking out has the breakdown of 7 days of data. I was testing the process on one isolated day.
I noticed that there's a few entries that have multiple openings and closings, I tried add in some logic checks, but I'm sure it would be much easier if I could figure out how to properly account for those variances.
There's some stylizing html that for some reason is included in the file when there is a multiple opening or closing. It starts with a closing p tag (
) and ends with a "> before the next iteration on the same line so I temporarily just did a search and replace on the string and converted it to *** to try and eventually get them to look like
08:00 - 15:00 16:00 - 19:00
For example
This is a copy of the data I'm using as a source for Monday (after I've manually done a search and replace on the data that isn't needed)
If there isn't an entry in the file and it's a blank line I've replaced the blank line with BLANK
Closed
Open 24 hours
Are the only other variances.
My good friend is trying to get a dynamic list going of local businesses that are opened still or are having changing hours and such due to the virus outbreak, so I'm trying to make a directory for them to use, and am trying to clean up this data dump and get it going .I'm super close! Thanks again for everybody's help, I appreciate it.
BTW, it would be best to name text files with a ".txt" extension, unless there is some good reason to do otherwise. I almost did not open your file because I had no idea what a ".pl" file is.
One more note, your file is 726 lines long, so it takes a few seconds to process. You might not notice anything happening until it finished.
I agree I tried uploading it and it gave me an error about being an unsupported extension, so I just saved it as a pl file because it said it was a supported extension.
PL = Perl script it was a popular programming language before PHP, I used to dabble in it during my days working with UBB (Ultimate Bulletin Board).
Apparently, I really needed the sleep for some reason I assumed it would only snag one-time code per line and the *** would bork it.
---- What I was asking is if in the source file before I sanitize it there was some stray HTML that made its way into the data. I was curious if there's an easy regex command, to take everything between two tags, for example, the ending of a
tag and "> and replace it with say a space?
I'm going to add finding a video tutorial that breaks this stuff down easy peasy to my to-do list.