I did some digging in search to get me started but came up empty. Here's what I'd like to do:
Click on a folder containing an unknown number of PDF files. Each PDF file is exactly the same layout (invoices from a subcontractor).
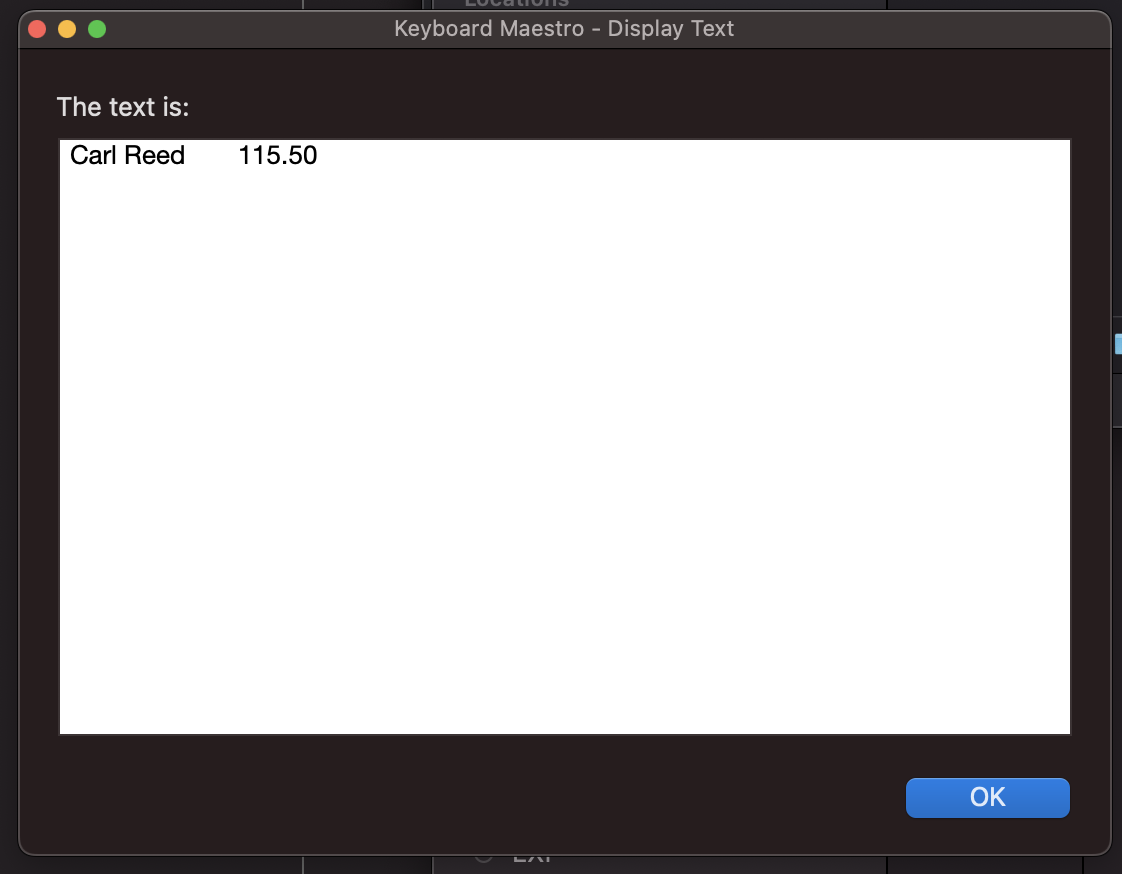
Activate a macro to copy specific information into a set of rows (one per PDF file) in numbers. Just client name, and invoice total.
Bonus if we can automatically sum the invoice amounts in numbers.
I don't even know where to start with this macro. I've not done file "handling" before and I have no idea if what I'm asking is even possible. If anyone has ideas or can point me in a direction to start messing around with this I would greatly appreciate it.
Here is some sample data. A spreadsheet and an example invoice.
I had a look at the sample pdf you provided and I see it is nothing more than a scanned document - so to extract the data you'll need to use OCR on it, rather than something like Tabula.
Hi Tiffle, thanks for responding! Not sure why that's showing as a scanned PDF for you. These are absolutely not scanned. I can select text no problem. I even used the "redact" feature to select text and remove personal identifying info before posting. Here is a screen cap of this:
Well, yes - you can select text but what can you do with it.
As an illustration, I've selected some text from your pdf:
and then copied and pasted into TextEdit with this result:
So you can see that a simple copy/paste won't work. I thought your pdf was a scanned document because that's what Tabula told me when I tried to process it.
Maybe there are other data extraction tools available, but I'm not sure KM can do it for you single-handedly.
There may well be someone here who can point out the error of my ways and be more helpful than me!!
Dang! I never actually tried pasting the text (silly me). Maybe because these invoices are generated from quickbooks. Perhaps quickbooks does something to intentionally scramble the output.
I very much appreciate the time you've put into this Tiffle. Perhaps somebody else on here has another idea to approach it.
AH! I just tried this on three other invoices, and they all worked. I think maybe when using the redact tool in preview it does this to prevent copying any info from the document.
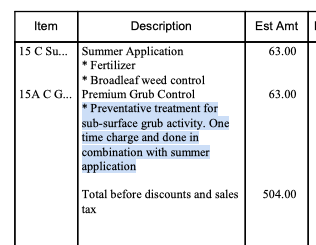
Below is sample output. I have manually typed over confidential info with XXX INFO XXX, but it shows you where it exists in the document. The last dollar amount and client name are what I'm looking to get into a spreadsheet in this case XXX CLIENT NAME XXX and $110.25
Here is a sample output:
XXXVENDOR NAMEXXX
XXX VENDOR STREET XXX
XXX VENDOR ADDRESS
Date
7/15/2020
Invoice
Invoice #
34815
Bill To
XXX COMPANY NAME XXX
XXX CLIENT NAME 2XXX
XXX CLIENT ADDRESS XXX
P.O. No.
Qty
Terms
Due on receipt
Rate Curr %
Project
Item
Description
Est Amt
Prior Amt
Prior %
Total %
Amount
15 C Su... 15A C G...
07 R Tic...
Summer Application
Fertilizer
Broadleaf weed control Premium Grub Control
Preventative treatment for sub-surface grub activity. One time charge and done in combination with summer application
Application to reduce tick populations in turf areas.
Total before discounts and sales tax
36.75 36.75
36.75 404.25
1 1
1
36.75 36.75
36.75
100.00% 100.00%
100.00% 27.27%
100.00% 100.00%
100.00% 27.27%
36.75 36.75
36.75 110.25
Subtotal
Sales Tax (0.0%) Total Payments/Credits Balance Due
$110.25
$0.00 $110.25
$0.00 $110.25
That makes a lot of sense - if you could "read" the text under the redaction it wouldn't be much use!
OK - I suggest you look at post #1 in this discussion
which basically tells you how to extract the text from one pdf and then extend that to cover many pdfs in a folder.
Once you've got that working you need to find a way to
Extract the 2nd line following "Bill To" to get "XXX CLIENT NAME 2XXX"
Extract the 2nd dollar amount from the last line to get "110.25" (or whatever is there)
Personally, I would use the Search Using Regular Expression action to perform the extraction - but there are many other ways; a search of the KM forum will turn up many examples of the use of regular expressions and scripting.
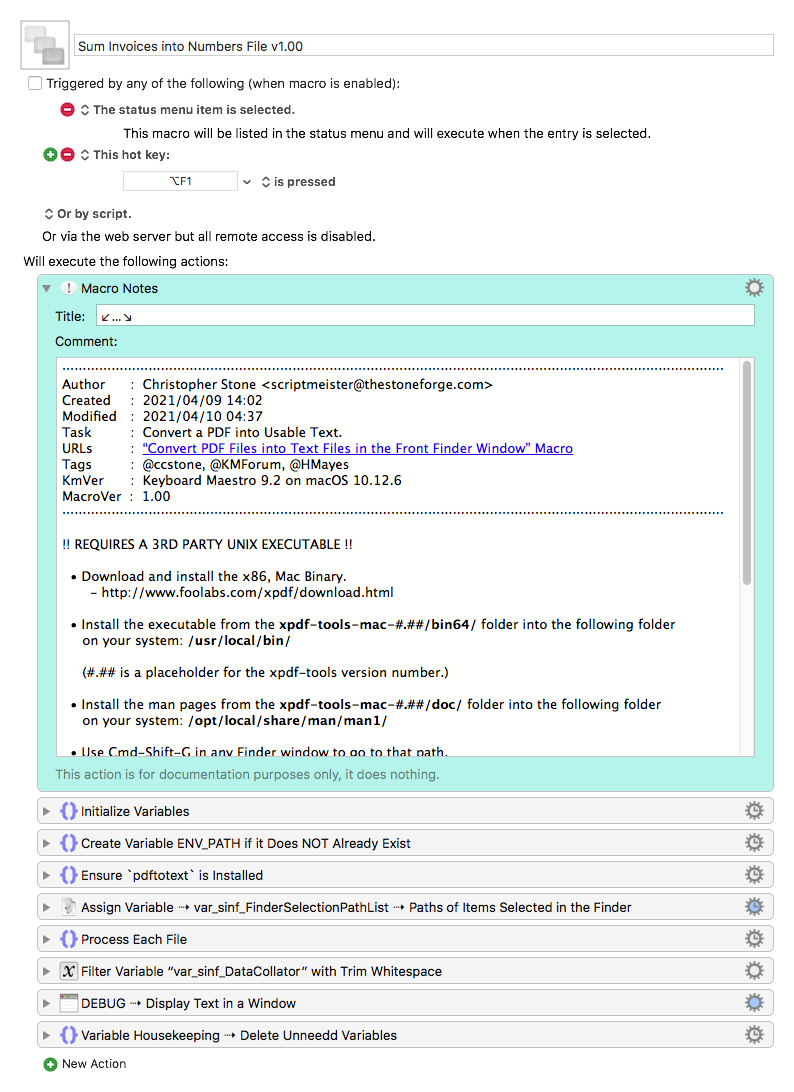
I OCRed your example PDF with PDFpenPro and then ran my script that uses pdftotext from Xpdf Tools to send the text of the selected PDF file in the Finder to BBEdit .
The output using the -layout switch looks to be easily parsed.
pdftotext -layout "<#path#>" - will give you much better output that what you copied and pasted in post #8 above.
Okay thank you for your help so far folks! I've got Chris's macro modified so that it creates a text file for each file inside of a folder - great. I've also got a regular expression built that I think gets me started.
Here is the regex on sample output from pdftotext.
Here's where I'm stuck:
I know next to nothing about shell scripts. I'm clueless how to pass the output of pdftotext into a variable to be parsed by the regex instead of creating a text file.
Once that happens, I'm not sure how to select the correct matches/groups from the regex to get that information into a variable. I think my match groups are Match 3 Group 1 and Match 24 Group 2.
Then I'll need to open up a new numbers file and paste the variables into a new line. although thinking about this, it may be simpler to collect them all for each file in a new line on the clipboard and paste it all at once at the end. thoughts?
Name here would be “Jill Sample Name”. That format always exists. Since this is from a subcontractor, under bill to the first line is always my company name, second line is the client name.
Last dollar amount: correct. The amount after “balance due”.
The only thing that changes in terms of format of the invoice is number of line items and what’s in them.
I see you broke this into multiple regex. Don't know why I did not think of that, was trying to create one that did it all. Thank you for your help on this so far!
People get overly proud of themselves for creating some very complex regular expression, and then it breaks...
BTDT.
Keep It Simple Sylvester is the name of the game.
This makes your macro easier to create and easier to maintain if/when it breaks – especially 2-days, 2-weeks, or 2-years from now when you've completely forgotten how you composed that thing in the first place.