[After reading my post, I can see that it was confusing. I've edited it to hopefully provide more clarity.]
Seems like this should be easy. Maybe I'm missing something.
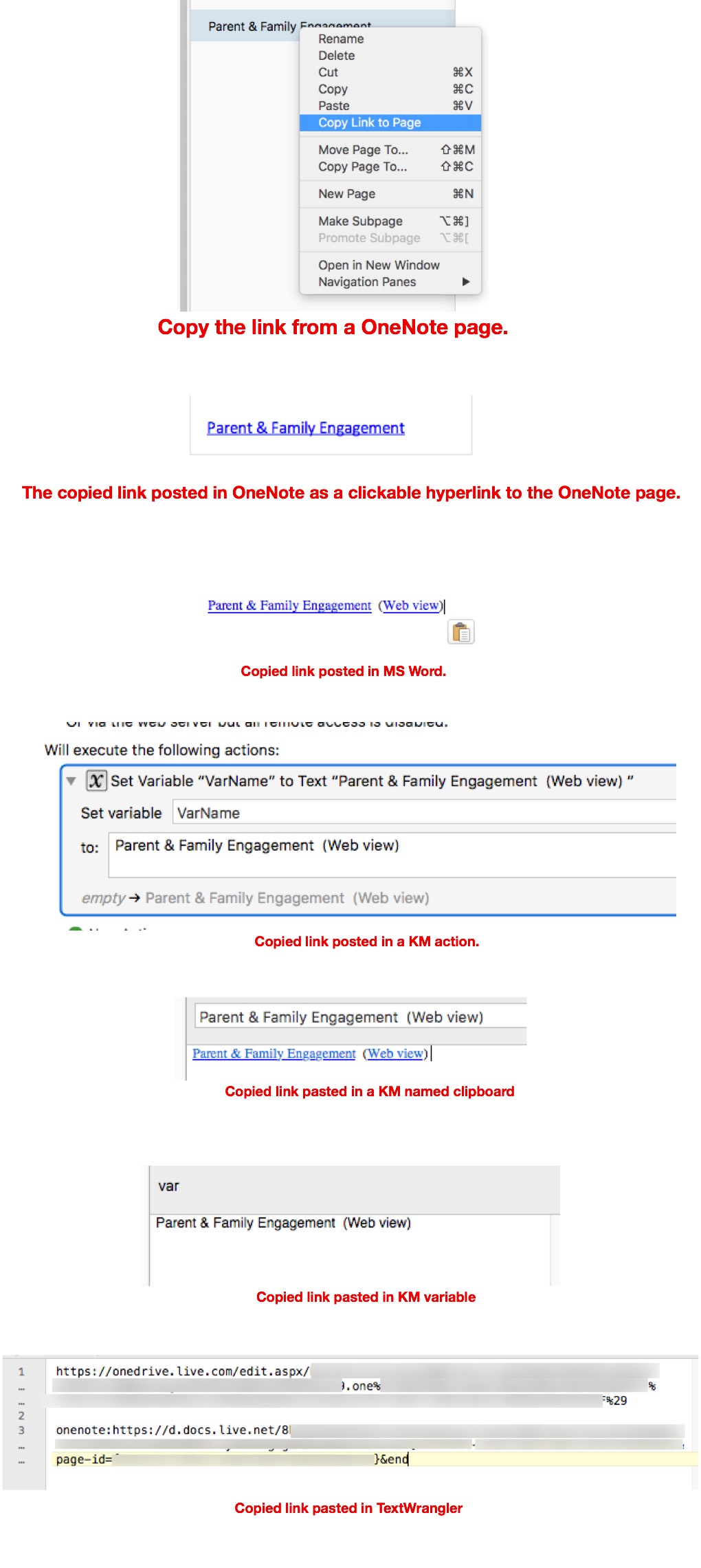
I'm trying to copy the underlying URL from a hyperlink that might appear in a microsoft word document, or in a OneNote page, or even as a OneNote link to a page.
The last example is the most relevant. I would like to glean the page URL from the OneNote hyperlink and create a web bookmark in a folder that, when double clicked, takes me to that OneNote page.
If I copy the page Hyperlink in OneNote, and paste the hyperlink in a clipboard or variable in KM, it always pastes the hyperlink text (The URL is never visible.), as a clickable hyperlink when pasting to a clipboard, and as plain text when putting the hyperlink in a variable.
Note the collage of pics below. Only a paste in TextWrangler reveals the underlying hyperlink.
In Keyboard Maestro, I've been able to create the bookmark with a working URL to a OneNote page, but not without manually pasting the hyperlink into TextWrangler, which fortunately pastes as the URL, not the hyperlink. (So now I can see the underlying URL.) I then copy that URL from TextWrangler, manually place the URL in a KM action, then use the actions to condition the URL for a bookmark file, and create the file.
Is it possible to use KM to glean the URL from the hyperlink without having to go to TextWrangler to see and copy the URL?
Yes, but we have to get the HTML on the Clipboard and decode it.
Here's an example Macro to get you started:
Copy the rich text hyperlink to the Clipboard
Trigger this macro.
Results are set to KM Local Variables:
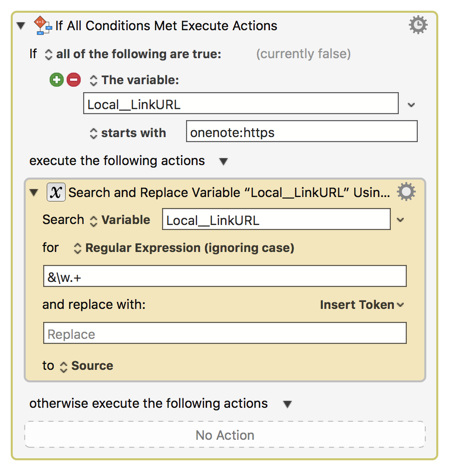
Local__LinkURL
Local__LinkText
MACRO: Extract Text & URL from HTML on Clipboard [Example]
#### DOWNLOAD:
<a class="attachment" href="/uploads/default/original/3X/7/c/7c87ef815573d84ff3e7b55ea9977e34a346be39.kmmacros">Extract Text & URL from HTML on Clipboard [Example].kmmacros</a> (13 KB)
**Note: This Macro was uploaded in a DISABLED state. You must enable before it can be triggered.**
---

---
Questions?
Thanks @JMichaelTX. I got it to work but only after "double encoding" by sending the variable "Local_LinkURL" through the filter action "Percent encode for URL", so that...
%20 became %2520
# → %23
{ → %7B
} → %7D
Note: These characters are elements of a OneNote page link.
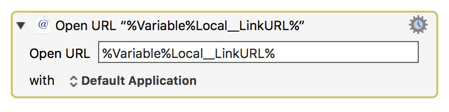
Even then, it only seems to work if I put the "double" percent encoded URL on the clipboard and opened it with an action like this:
Open URL “%CurrentClipboard%” or Open URL "%SystemClipboard%"
Note: Even the "single" percent encoded URL won't work with the above action.
And the "single" or "double encoded" URL won't open if I paste the clipboard contents (the double encoded URL) into a Open URL action.
Works only if "double encoded" and opened using the Open URL "%SystemClipboard%" action.
And yet...
When I created a bookmark file (kind: Web site location) in the Finder using the single encoded URL, that DID open in OneNote.
I wonder if I'm playing "31 flavors" with the text. (i.e. How different flavors of the text can reside on the clipboard simultaneously.)
Ultimate goal: Create a bookmark file that opens to a particular OneNote page. It did. Purpose served. Thank you!!!
The page reference stops just before §ion-id above.
So, I found that the URL works fine if you post process the URL by removing the "&" and everything after it like this:
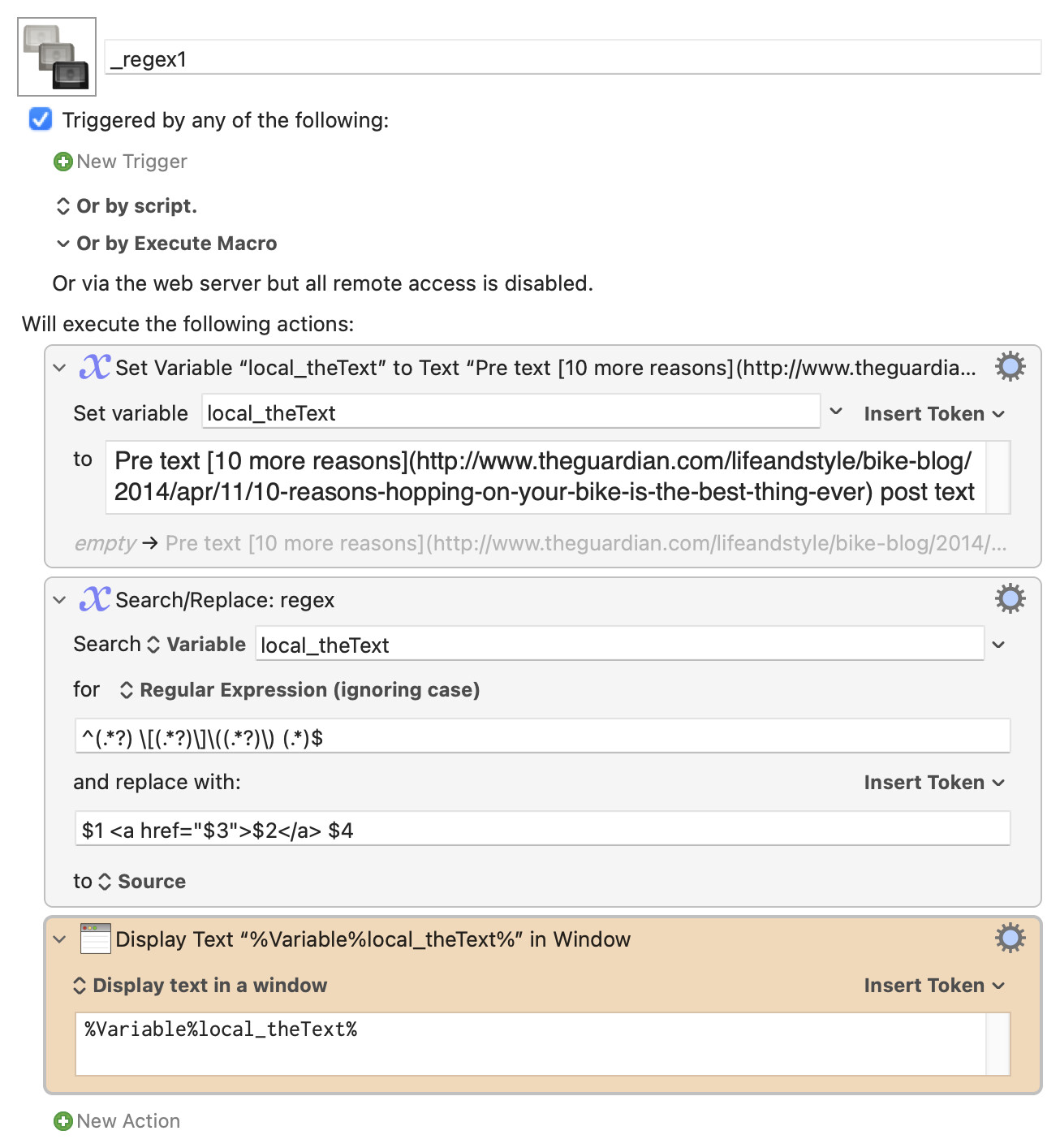
Hi - this script is great. My challenge at the moment is changing a RichText block such as: "Pre text [10 more reasons](http://www.theguardian.com/lifeandstyle/bike-blog/2014/apr/11/10-reasons-hopping-on-your-bike-is-the-best-thing-ever) post text"
Into an HTML block such as: "Pre text <a href=“http://www.theguardian.com/lifeandstyle/bike-blog/2014/apr/11/10-reasons-hopping-on-your-bike-is-the-best-thing-ever” target=“_blank”>10 more reasons</a> post text"
This script text helps with the middle HTML link - does anyone know how I'd go about adapting it to return the pre and post link text as well please? I'm afraid that's beyond my meagre scripting skills ...
The regular expression looks ugly, but that's mainly because the brackets and parentheses have to be escaped with \ to be used literally. The find part reads:
Find from beginning of line: ^
The minimum characters up to a space-open bracket: (.*?) \, and capture that (the surrounding parentheses) as capture group $1. This is now the captured pre-text
Capture the minimum characters up to the closing bracket into the second capture group, $2: (.*?)\]. This puts the link text in $2.
Find an opening parentheses, and capture any text before the close parentheses into $3: \((.*?)\). We now have the URL itself in $3.
Finally, capture everything after the space following the closing parentheses until the end of the line into capture group $4: (.*)$
With all the parts separated, the Replace With just puts them back in the desired order, with the added text where required.