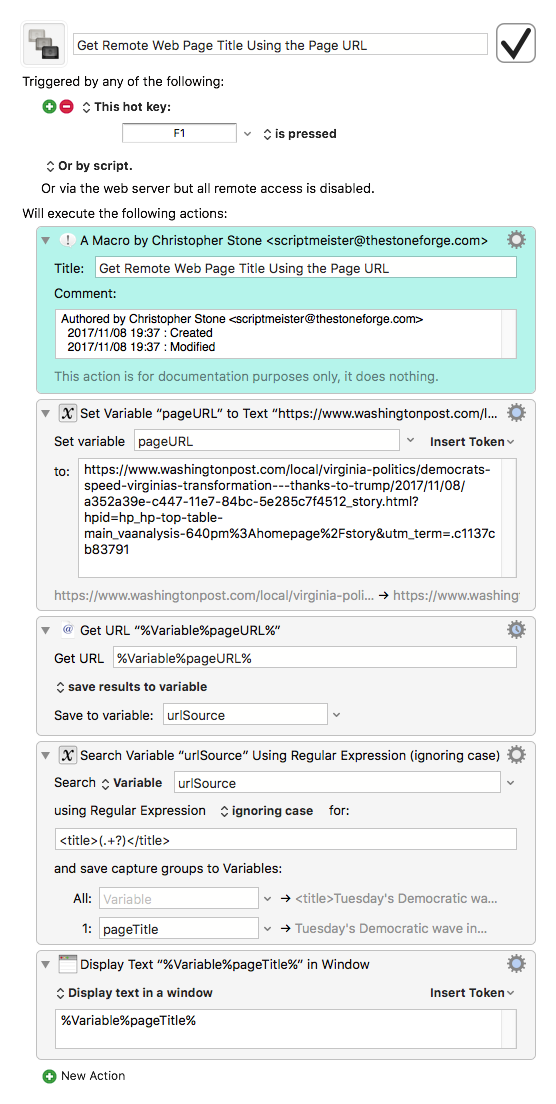
(SEE UPDATES BELOW!)
This macro is invoked by a typed string trigger and simply takes a URL in the clipboard, extracts the URL title, swaps the URL for a Markdown link in the clipboard, and pastes it. The macro solves a minor problem that nagged at me which was that I didn't want to have to open a hyperlink to get a proper Markdown link for the URL in the link. Now, you can simply right click on hyperlinks, select "Copy Link":

Then, in your document, type your string trigger, and a Markdown link will output:
- [Mass Shootings Don’t Have to Be Inevitable - The New York Times](https://www.nytimes.com/2017/11/06/opinion/texas-guns-shooting-trump.html)
Here it is in action, where I'm copying URLs from hyperlinked article headlines and pasting the Markdown links in an email compose window in Postbox, (then I use an add-on to render the HTML):

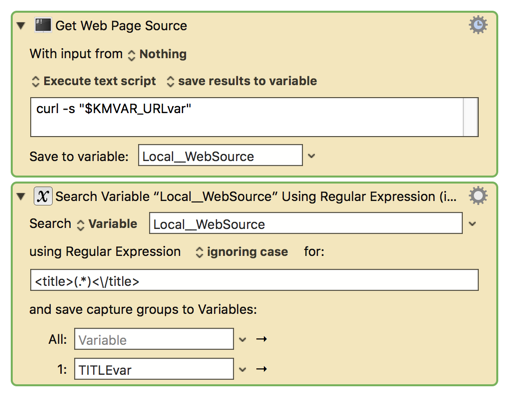
The original version of the macro didn't get all Titles, but it got a lot of them. (It used a "curl" shell script which I found in an old post by Patrick Welker of RocketINK, but I can't find the post now, apologies! - And thanks, Patrick!).
This is what the original macro looked like:

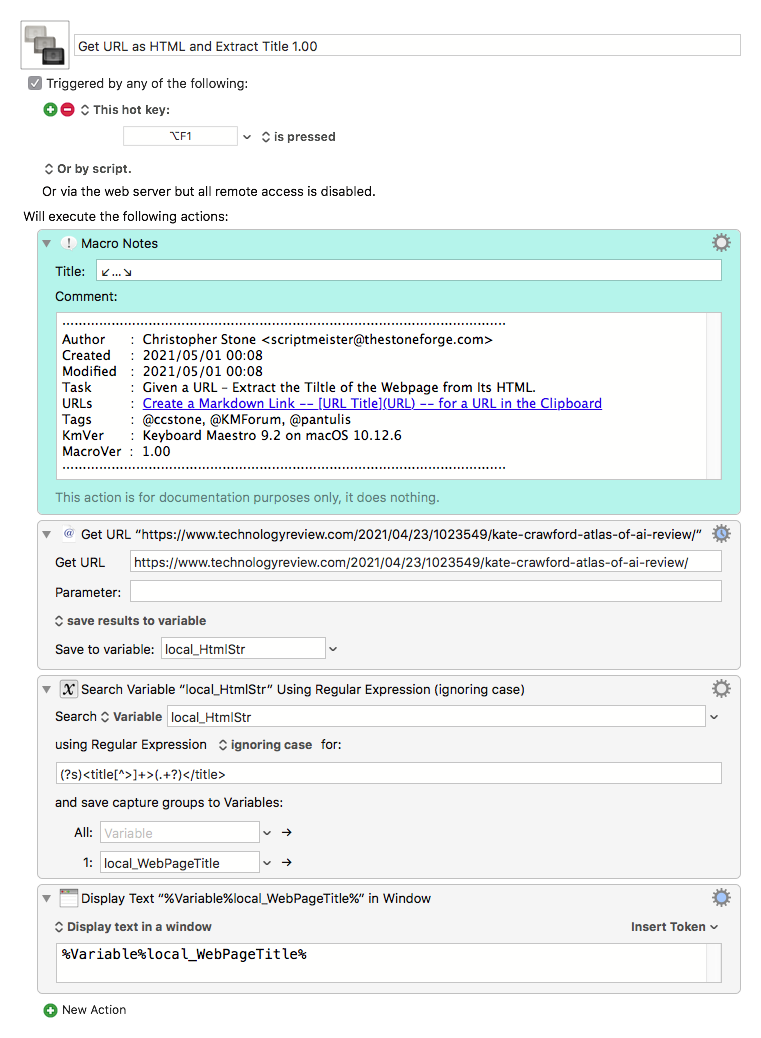
The UPDATED macro can be downloaded here, and it now incorporates changes to the script suggested by JMichaelTX, which seems to capture URL titles in all cases (that I have tried):

Again, the updated, fully functional macro is available here!
Cheers!