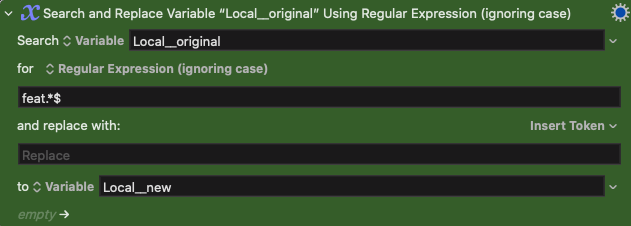
I'm still learning RegEx as I use it with some macros, but I ended up with this expression to delete everything after a certain word or group of words feat.*$
So this:
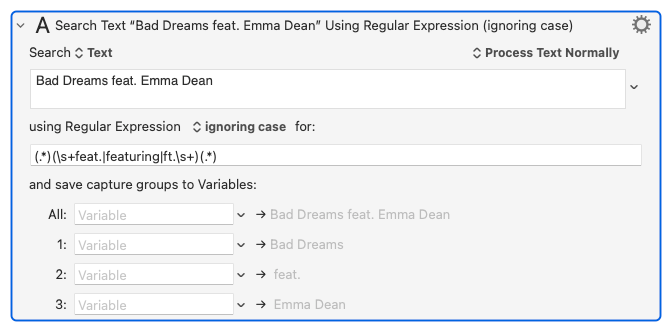
"Bad Dreams feat. Emma Dean" (ignore the quotes)
Becomes this:
"Bad Dreams " (with the extra space at the end)
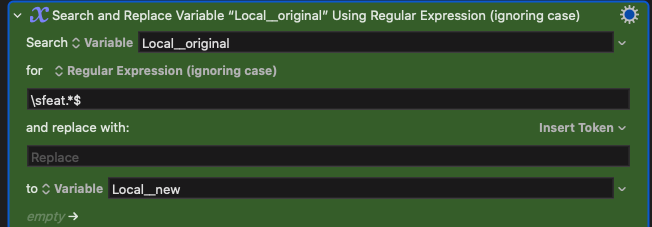
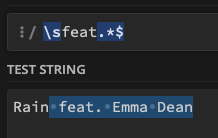
Also, if I want to delete a space from the beginning, I used \sfeat.*$
"Bad Dreams feat. Emma Dean"
Becomes this:
"Bad Dreams" (WITHOUT the extra space at the end)
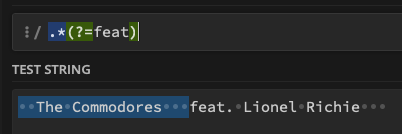
And after some testing, I was able to find how to do the opposite, where I replace the text before a certain word or group of words: .*(?=feat)
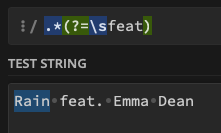
or this .*(?=\sfeat)
I tested and both options work. I'm just wondering if this is the right way to do it, if there's any chance that it will create any issues in other scenarios, etc?
you said you wanted to delete text "after" a string, but it seems that you are actually deleting a word "starting from" a string. Same concern with "before a string" really doing "up to and including" a string.
I would usually say "\s+" instead of "\s" to get multiple spaces.
I see nothing wrong with your method, but here's another option using capture groups that will allow you to use (or ignore) any part of the string without explicitly deleting anything.
Yes, it was a "typo". I wanted to say "after" as in "start with that word, and then everything after that (or before). The expressions I shared did the trick.
In this particular case I only want to remove the space right before "feat", because if I save the remaining info to a variable and then use it to, let's say, rename a file, it will add the space, which is not what I need.
Thanks. Yes, I had that website on my notes about RegEx.
My thing is that certain things we use with KM (RegEx, Shell, AppleScript, etc), are not things I use all the time and since I'm not a developer or anything like that, it's hard for me to really put aside time to learn all of those on a deeper level when I rarely use it. And you know, when you don't use it often, you tend to forget it.
So I ask for tips, learn it, save actions/macros with those scripts and expressions and reuse them. Some things are simpler than others, but not always.
That being said, that website can be helpful, but I still need to be more comfortable with how the basic of RegEx works
For this particular case, the titles will always be formatted as "feat", never with "ft" or "featuring", but it's good to see how to combine different options.
Do you mind breaking down the expression in "plain English", since I'm still not very comfortable with RegEx?
the () capture groups are not necessary for matching; they only serve to return the enclosed characters (this is how Keyboard Maestro can save them into variables)
since the . character is a meta character in regular expressions reserved for matching any character, we must (as @tiffle noted) escape it with \ so that it's treated as a literal "."
If you have any questions, I'll gladly try to provide some clarity.
.* - match any number of any characters until... \s+ - you see one or more whitespace characters, then... feat. - after the whitespace you see these literal characters, then... \s+ - one or more whitespace characters again, then... .* - any number of any characters, infinitely.
First of all, \s doesn't match "the space" it matches all "white space" including tabs, returns and similar characters as mentioned by others. And of course \s+ matches multiple white space. This is also mentioned in another reply to you.
Second, now that you've told us you are trying to remove leading and trailing spaces from a string so that the resulting string is used to "rename a file" then that's all the more reason to remove multiple white space by using \s+. Generally speaking, most people don't want extra spaces in file names.
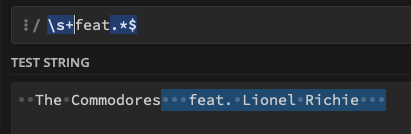
Thirdly, the remaining string after you've done this could still contain white space, and other characters that are illegal in file names. For example, if you were processing this string: (I will use "_" for a space)
__The_Commodores___feat._Lionel_Richie___
using your method the resulting file name would still have spaces at the beginning or end of your new filename. Either one of these:
__The_Commodores Lionel_Richie___
I think the people who responded provided good information that answered your question, "How would \s+ work in real life?"
Last night I watched a YouTube "crash course" on RegEx by this guy TheNetNinja, if you don't know about him. I love how he teaches and I was able to learn a lot from those.
So now I am able to reply to some of you with a clearer understanding of what you are sharing. So I hope I can clarify some things. Let's see how it goes...
For my particular case, because of the way I'm using this KM macro, I would never have 2 or more whitespaces, so having \s+ would not accomplish anything different than just using \s
This, of course, is for this particular macro and for the way my files are being renamed. I can see how this could change in a different scenario.
Last night, while learning from those YouTube videos, I used it a lot and I can now see how this can help me test my expressions.
I can see how just using . instead of \. would affect the results. In this particular case, the dot was not related to the word "feat", but instead was to actually match everything that comes after "feat". So what I mean is: match everything that comes after the pattern _feat (the underscore being a space).
So if the song is "Rain feat. Emma Dean", it will keep "Rain" and delete everything.
Now for the second example .*(?=\sfeat) I can now see that it actually matches the beginning of the string which is not what I need, if I'm using the Replace filter.
As opposed to
So I guess it depends on what I want to do and how I then use the results.
I can now look at your initial expression and fully understand what it means (by what I've learned last night) and looking at your break down now, it's even clearer. Really appreciate it!
For this particular case, since the file name will have a space before "feat." and my macro is set to rename them a certain way, the \s is related to the space, even if \s by definition includes tabs, etc.
This also clarifies that using \s+, for this particular scenario, is not applicable, because my files will not have 2 or more spaces.
I'm not one of those people , because I use 2 or more spaces all the time, usually at the beginning of the filename, just to make them go up a list of files, or to stand out even more. Of course I don't use this with files I share with others or for online purposes. It's just for myself, to make things more prioritized than others.
As mentioned, this would never be a case, at least for this particular macro where there are no 2 or more spaces, there are no spaces in random places such as the beginning or the end of the filename.
Since I want to target and delete everything after the song name, if I had 2 or more spaces before "feat" then I can see how using something like \s+feat.*$ would achieve that.
Or if I wanted to match the beginning only .*(?=feat)