I am not sure if the script will be useful for you because it cleans up the metadata based on my file naming convention. Look; I tell Bookends to rename my PDF files on a certain format:
Author Year Title
What does this script does is then, embed these elements into the metadata of the PDF (a straightforward way would be to have Bookends directly embed the metadata into the file; but, bookends cannot do so yet)
The embedding of the metadata is done by standard shell script in combination with exiftool; another potent metadata manipulation tool widely used for archiving photographs (media files). It also works well with PDF files.
Here is Hazel rule (a lot idiosyncratic rule; You have to simplify them to fit your needs)
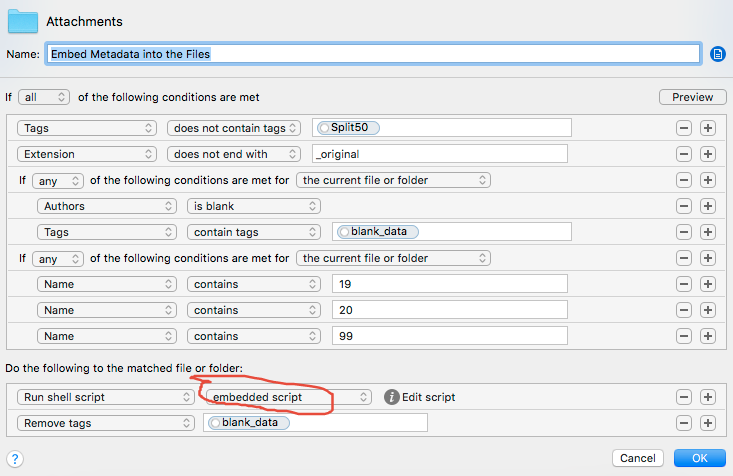
and, here is the script:
#!/bin/sh
titlee=${1##*/}
title=${titlee%.*}
author=${title%% *}; title=${title#* }
year=${title%% *}; title=${title#* }
exiftool -Author="$author" -Title="$title" -CreateDate="$year" "$1"
blank_data is a tag I use to mark PDF files which contain no metadata. For files which contain a good metadata, there is no need to overwrite them.
How do I know which of the files have blank metadata? I made Hazel to inspect the files. It inspects them and tag them with blank_data, before running the above rule.