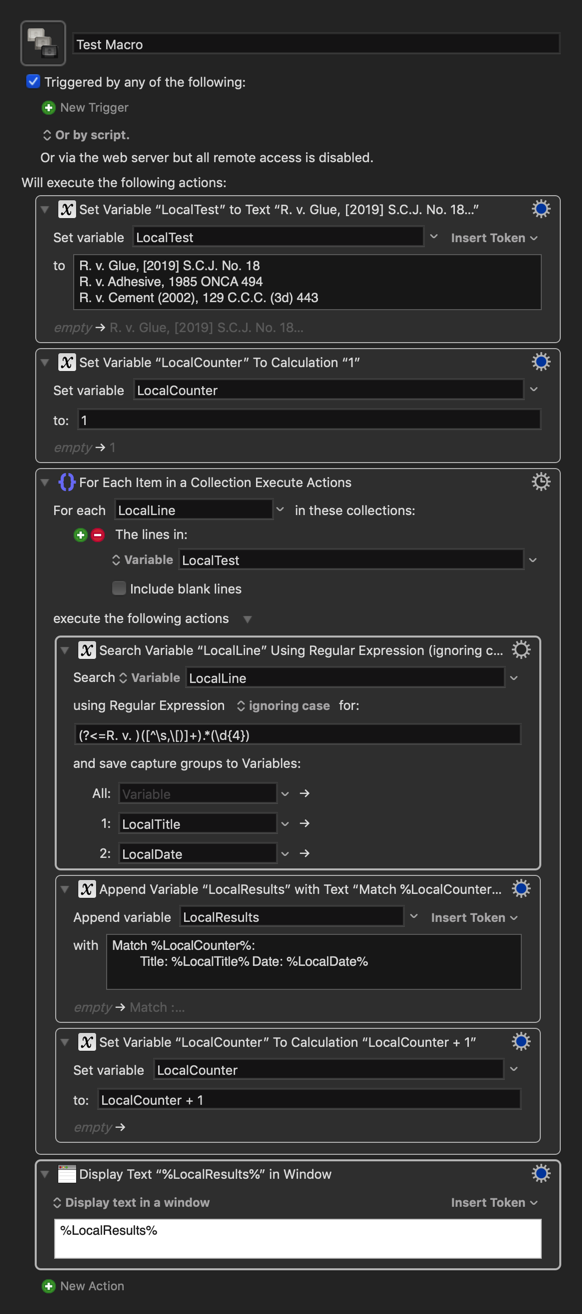
Hi, people who are less terrible than me at programming languages:
I'm trying to write a macro or hazel rule that parses certain information in a PDF's filename into that PDF's metadata (to then use in DT3 smart rules).
These are law cases that are titled by their citations. The citations are in various formats, but all of them begin with "R. v. [NAME]" and include the year somewhere, for example:
R. v. Glue, [2019] S.C.J. No. 18
R. v. Glue, 2019 ONCA 494
R. v. Glue (2019), 129 C.C.C. (3d) 443
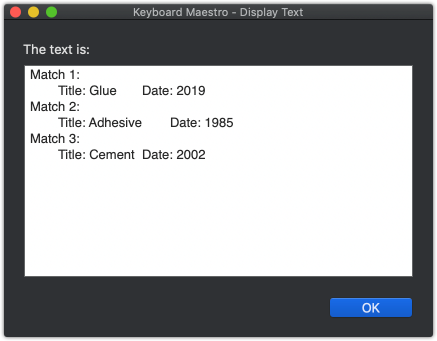
…among others. What I'm hoping to do regardless of format is parse out [Glue] (i.e. the word after "v.") into the "Title" metadata field and [2019] (i.e. a year in 19## or 20## format) into the "Date" metadata field.
I just spent an unhappy half-hour trying to adapt the bash in Desalegn's post here—but it occurred to me that what will probably take me hours to get right might be the work of seconds for someone with a moment to spare in this generous community. Or maybe someone has a better idea of how to go about doing this?.
You didn't say how you would be processing these file names (Manual selection? Whenever one is added to a folder? Going through every existing file in a folder?) so without more details, it's difficult to demonstrate a full-featured macro that could meet this need, but if you're just looking for how to parse the filenames for their data, based on the examples you provided and the format you describe, this should get you started:
Amazing. Thanks so much. I'll play with this this aft and report back.
And I hadn't considered how I'd be processing the filenames—I guess there'll be a tremendous number of files to process at first, and then going forward I'd be doing it piecemeal—but I think (hope) I can figure out that end of it with some poking around.
In the For Each you will enter a KM Variable in which will be stored the POSIX file path for each item in the list as KM processes the loop. I usually name this "Local__FilePath".
You can then get the file name (or other property) of the file using the Get File Attribute action. We'll call this "Local__FileName".
The "Local__FileName" will be the source for use with the RegEx that @gglick provided above. So, where he used "LocalLine", you will use "Local__FileName"
I don't have any idea of how to update the PDF metadata, but you should try a search of the forum, as there have been may topics about PDFs.
Try putting together the macro yourself, and if you get stuck, feel free to post back here.