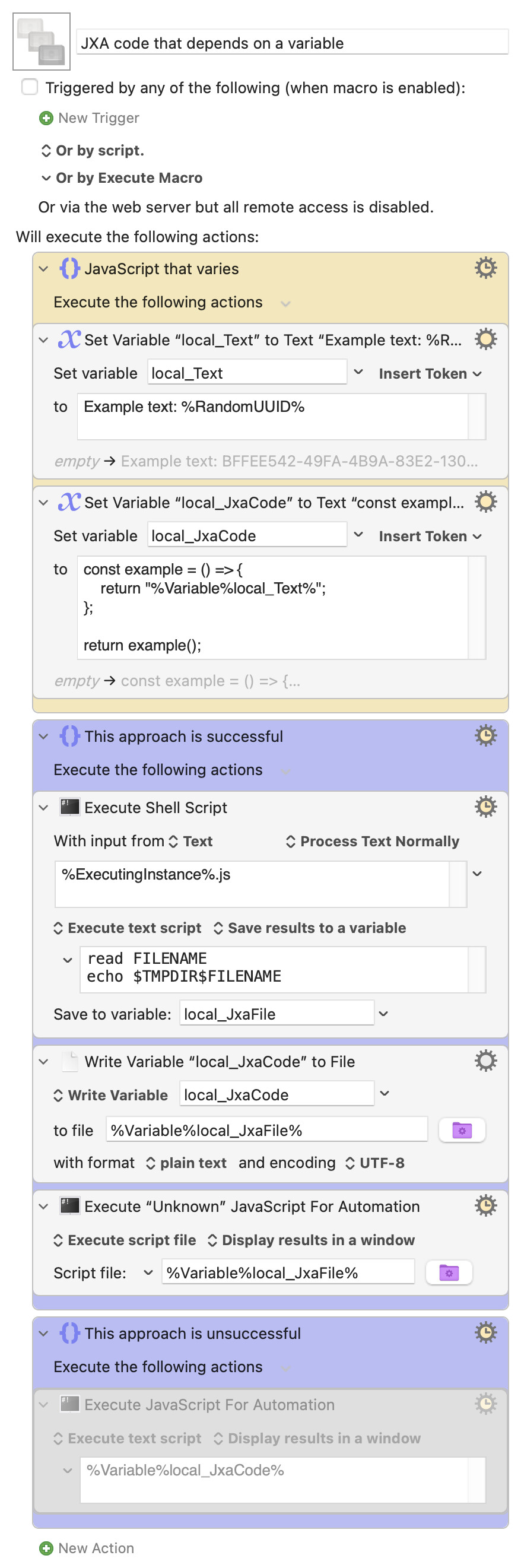
I'm creating a macro that will include an Execute a JavaScript For Automation action with code that will depend on Keyboard Maestro variables. Just to be clear, the code will vary, not JavaScript variables within the code.
I've been experimenting. It appears that I need to write the code to a file and then run the JavaScript file. Also, when constructing the code, it seems that I've had to change the Set Variable to Text action to Process Text Tokens Only.
Here's a trivial example that illustrates the the first issue, but because the code is so trivial it functions even without the change to Process Text Tokens Only.
Darn, I should have started by sharing my overall objective. (I know better; sorry, I was just being lazy. )
Better late than never...
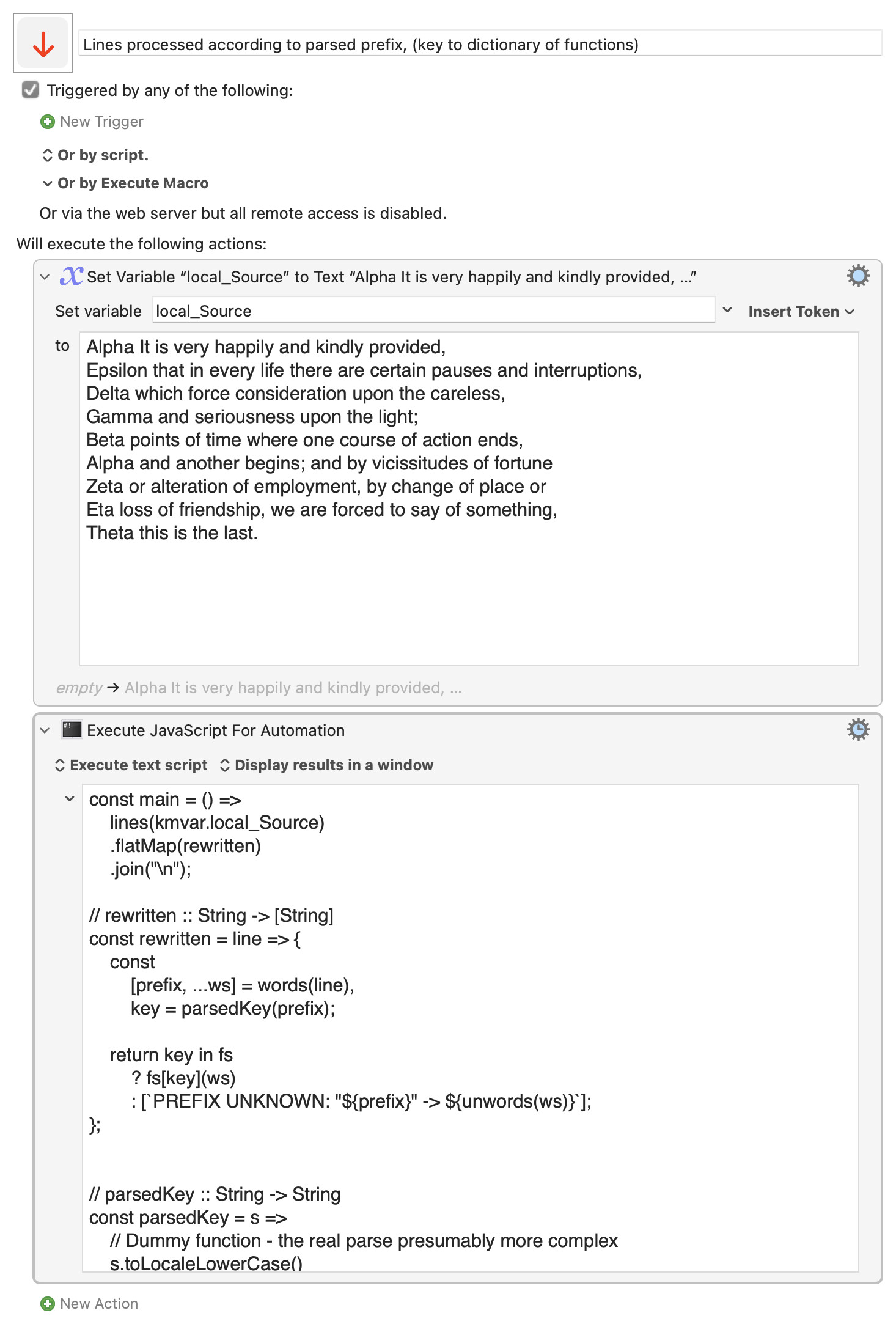
I will be working with files that could potentially contain thousands of lines of plain text. Each line will start with one of ten single-character codes which will dictate how the remainder of the line should be parsed.
In some cases, the parsing is complex. I’ve already created the ten parsing functions and they are working well.
I am creating a subroutine macro with eleven parameters—one for the text (i.e., local_Text) and one for each of the ten codes (e.g., local_A). If any of the ten code parameters are empty, that's an indication that lines that begin with that particular code should be skipped rather than parsed.
The subroutine processes local_Text and accumulates parsed results, but only for the codes specified by the calling macro.
Based on the above requirements, my objective has been to avoid including a conditional check (parse, or don't parse) for each of the ten codes within the main processing loop. So my thought was to first evaluate the subroutine parameters and then "build" the parsing functions conditionally:
For example, if the subroutine parameter local_A is not empty:
With this approach, the logic within the main processing loop could remain fixed regardless of the subroutine parameter values specified by the caller.
@ComplexPoint (or other expert programmers out there), I suspect you may offer up a more elegant solution—I'm all ears. Thanks in advance!
The output of your code, for each file, is a new file with modified lines ?
(or are there effects beyond the file-system ?)
In this case:
const parseA = (line) => {};
we are skipping an output line ? Or simply having no effect elsewhere ?
I wonder if it would be possible to show us a sample of input and desired output ?
If, for each file, the code maps each source line (consisting of a prefix and a residue) to 0 or more output lines, with the particular map function over the residue chosen, from a finite set, by some function over the prefix, then I'm not quite clear why an eval component seems necessary.
Sorry to be unclear, I'm just asking what, by applying the appropriate code to each line's residue, you code is actually producing.
Is it text ?
I don't think you should need to use Function() here – perhaps just a case statement, or (my personal preference) a keyed dictionary of different functions – one for each prefix pattern ?
but if you're happy with Function(), it's not uninteresting to play with ...
const main = () =>
lines(kmvar.local_Source)
.flatMap(rewritten)
.join("\n");
// rewritten :: String -> [String]
const rewritten = line => {
const
[prefix, ...ws] = words(line),
key = parsedKey(prefix);
return key in fs
? fs[key](ws)
: [`PREFIX UNKNOWN: "${prefix}" -> ${unwords(ws)}`];
};
// parsedKey :: String -> String
const parsedKey = s =>
// Dummy function - the real parse presumably more complex
s.toLocaleLowerCase()
// Dictionary of functions of type [String] -> [String]
const fs = {
alpha: ws => [unwords(ws.map(s => s.toLocaleUpperCase()))],
beta: ws => [unwords(ws.toReversed())],
gamma: ws => [
unwords(ws.map(
(w, i) => [
0 === i % 2
? w.toLocaleUpperCase()
: w
]
))
],
delta: ws => [ws, ws, ws].map(unwords),
epsilon: () => []
};
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single string
// which is delimited by \n or by \r\n or \r.
0 < s.length
? s.split(/\r\n|\n|\r/u)
: [];
// unlines :: [String] -> String
const unlines = xs =>
// A single string formed by the intercalation
// of a list of strings with the newline character.
xs.join("\n");
// unwords :: [String] -> String
const unwords = xs =>
// A space-separated string derived
// from a list of words.
xs.join(" ");
// words :: String -> [String]
const words = s =>
// List of space-delimited sub-strings.
// Leading and trailling space ignored.
s.split(/\s+/u).filter(Boolean);
// MAIN ---
return main()
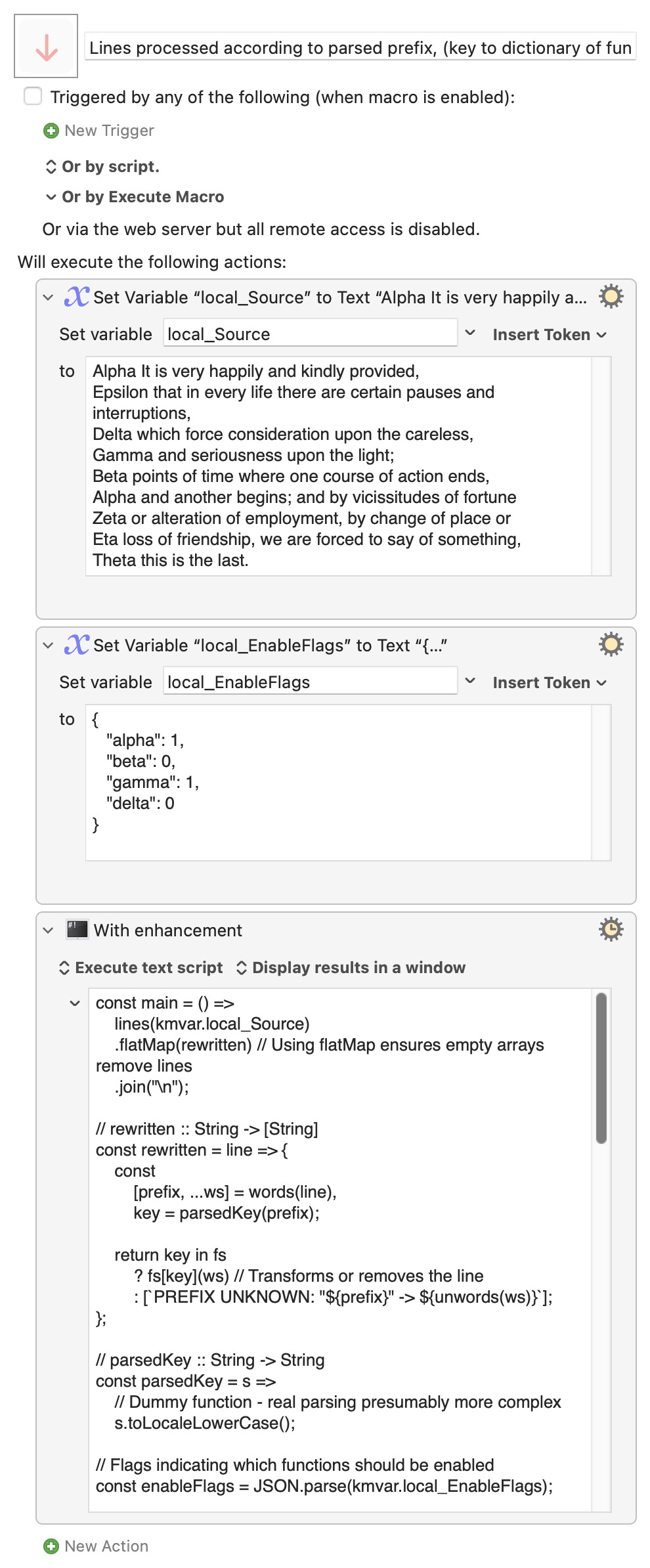
@ComplexPoint, thanks for demonstrating the dictionary technique. I've started with your code and modified it to accomodate the following requirements:
Add an enable flag for each transformation function (alpha, beta, gamma, delta).
Evaluate the flags at the start of execution, not in the main processing loop. (It's possible that thousands of lines will be processed.)
When a function is enabled, it should process its corresponding lines normally. In contrast, if a function is disabled, the processed lines should be effectively removed from the final output, i.e., rather than simply being ignored, these lines should be dropped. Note that epsilon is now unneeded.
const main = () =>
lines(kmvar.local_Source)
.flatMap(rewritten) // Using flatMap ensures empty arrays remove lines
.join("\n");
// rewritten :: String -> [String]
const rewritten = line => {
const
[prefix, ...ws] = words(line),
key = parsedKey(prefix);
return key in fs
? fs[key](ws) // Transforms or removes the line
: [`PREFIX UNKNOWN: "${prefix}" -> ${unwords(ws)}`];
};
// parsedKey :: String -> String
const parsedKey = s =>
// Dummy function - real parsing presumably more complex
s.toLocaleLowerCase();
// Flags indicating which functions should be enabled
const enableFlags = JSON.parse(kmvar.local_EnableFlags);
// Dictionary that maps each function name (key) to its transformation logic.
const allFunctions = {
alpha: ws => [unwords(ws.map(s => s.toLocaleUpperCase()))], // Converts all words to uppercase.
beta: ws => [unwords(ws.toReversed())], // Reverses the order of words.
gamma: ws => [
unwords(ws.map(
(w, i) => 0 === i % 2 ? w.toLocaleUpperCase() : w // Alternates case.
))
],
delta: ws => [ws, ws, ws].map(unwords), // Repeats the word sequence three times.
};
// This dictionary stores only the enabled functions.
// If a function is disabled, its definition is replaced with `() => []` to ensure lines are removed.
const fs = Object.fromEntries(
Object.entries(allFunctions).map(([key, func]) => [
key,
enableFlags[key] ? func : () => [] // Disabled functions return an empty array to remove lines.
])
);
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single string
// which is delimited by \n or by \r\n or \r.
0 < s.length
? s.split(/\r\n|\n|\r/u)
: [];
// unlines :: [String] -> String
const unlines = xs =>
// A single string formed by the intercalation
// of a list of strings with the newline character.
xs.join("\n");
// unwords :: [String] -> String
const unwords = xs =>
// A space-separated string derived
// from a list of words.
xs.join(" ");
// words :: String -> [String]
const words = s =>
// List of space-delimited sub-strings.
// Leading and trailling space ignored.
s.split(/\s+/u).filter(Boolean);
// MAIN ---
return main();
flatMap / concatMap with an (a -> [b]) function which wraps its output in a list or array, allows not only for returning empty lists (which, as you say, disappear under concatenation – the flat in .flatMap) but, more generally, for returning lists of any length – mapping one line, for example, to none or several.
i.e. where
.map always returns a list of the same length as the input, and
.filter returns a list of the same length or less,
.flatMap is completely flexible – it can return longer or shorter lists.
(JS .flatMap – in some languages concatMap – is the 'bind' operator in the 'list monad' pattern which underlies, among other things, the list comprehensions in Python and Haskell etc)
Expand disclosure triangle to view JS source
// cartesianProduct :: [a] -> [b] -> [[a, b]]
const cartesianProduct = xs =>
// Every tuple in the cartesian product
// of xs and ys.
ys => [...xs].flatMap(
x => [...ys].map(
y => [x, y]
)
);
JSON.stringify(
cartesianProduct(["alpha", "beta", "gamma"])([1, 2, 3])
)