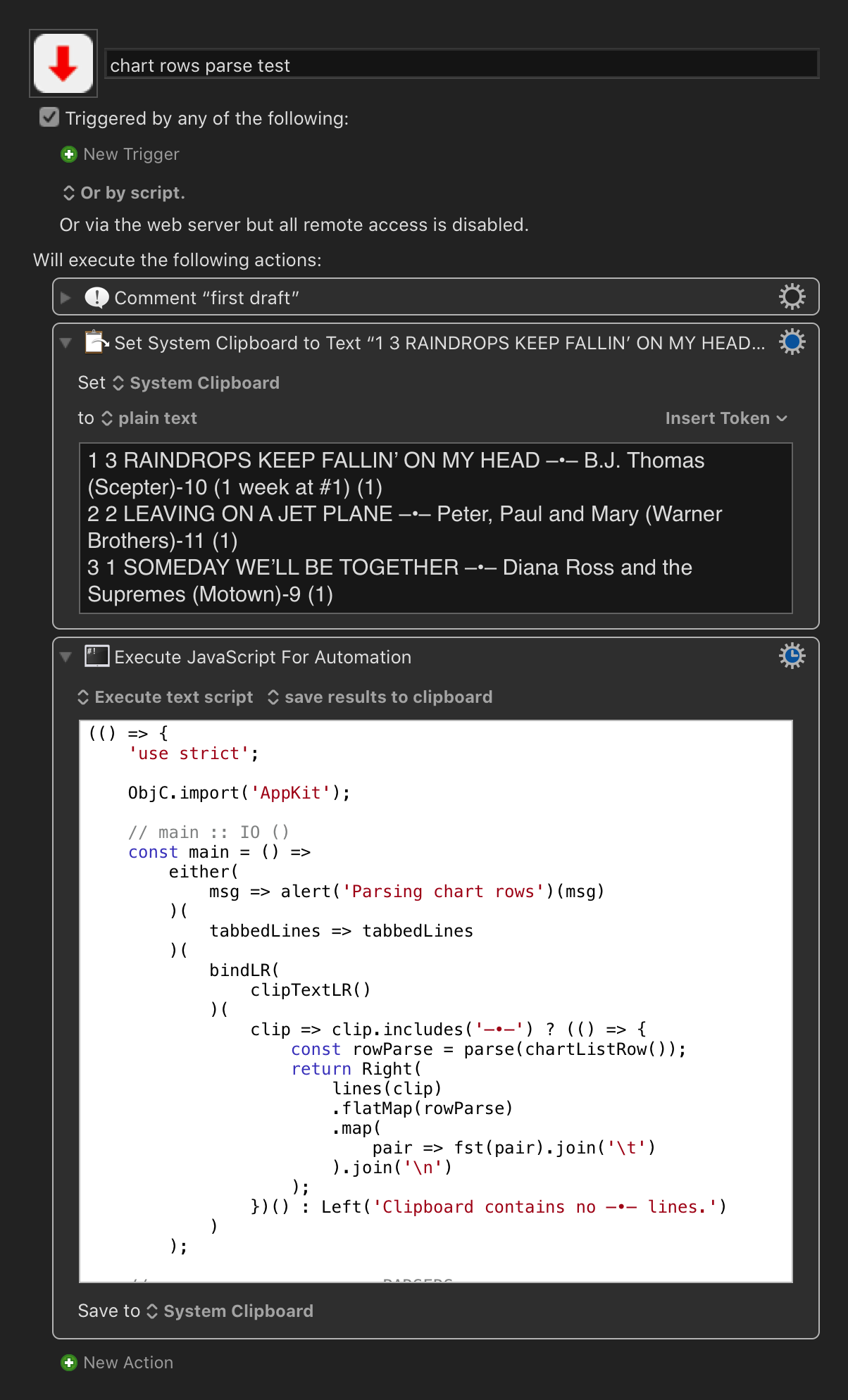
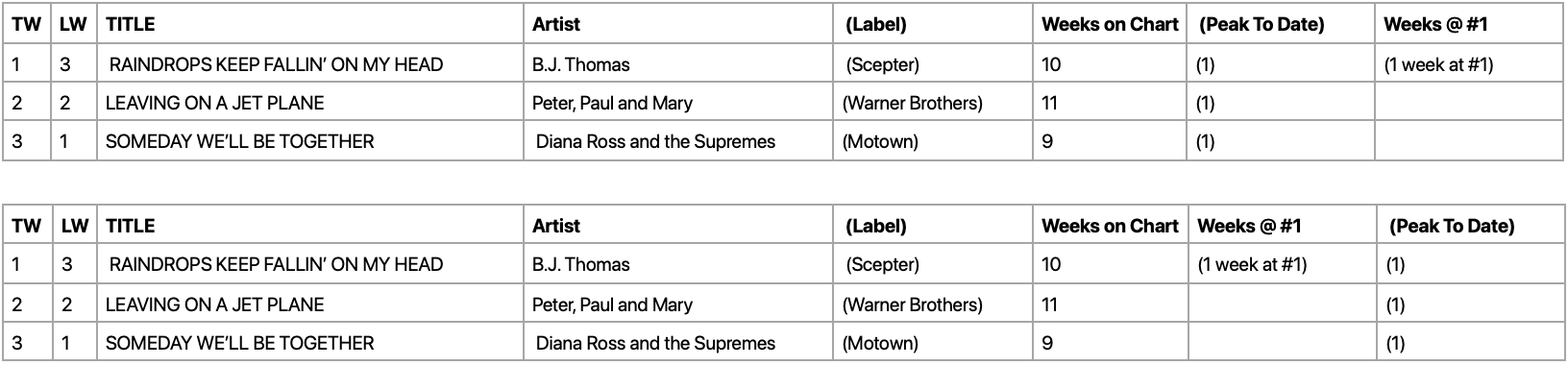
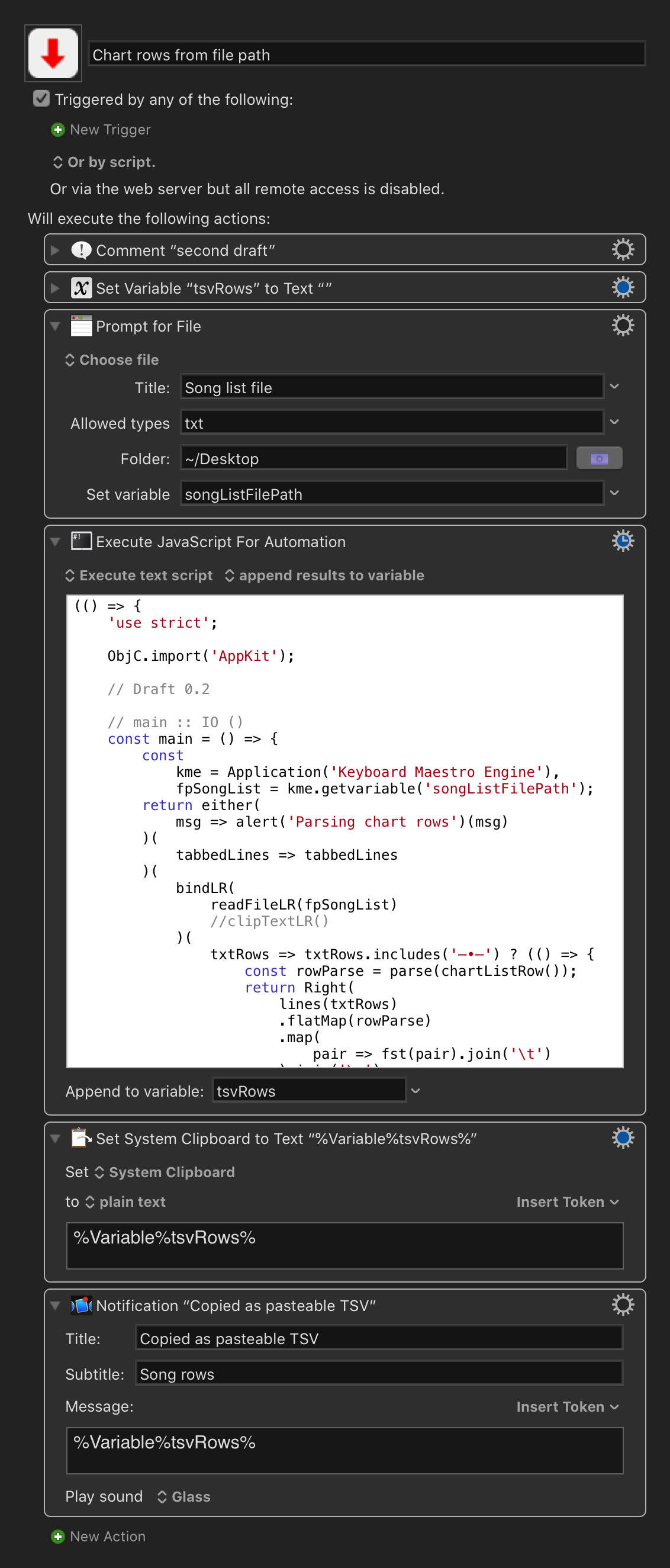
Meanwhile, assuming that the pattern of the rows is more or less consistent, the theory of this first sketch is that:
- if you have copied some rows of the the
–•– source format
- and run this macro
it should (if all goes well) repopulate the clipboard with a tab-delimited version of the rows, which you can then paste into something like Excel or Numbers.
chart rows parse test.kmmacros (33.7 KB)
JS Source
(() => {
'use strict';
ObjC.import('AppKit');
// Draft 0.2
// main :: IO ()
const main = () => {
// TW LW TITLE –•– Artist (Label) (Weeks on Chart) (Peak To Date)
// const xs = [
// '1 3 RAINDROPS KEEP FALLIN’ ON MY HEAD –•– B.J. Thomas (Scepter)-10 (1 week at #1) (1)',
// '2 2 LEAVING ON A JET PLANE –•– Peter, Paul and Mary (Warner Brothers)-11 (1)',
// '3 1 SOMEDAY WE’LL BE TOGETHER –•– Diana Ross and the Supremes (Motown)-9 (1)'
// ];
// const test = `1 3 RAINDROPS KEEP FALLIN’ ON MY HEAD –•– B.J. Thomas (Scepter)-10 (1 week at #1) (1)',
// 2 2 LEAVING ON A JET PLANE –•– Peter, Paul and Mary (Warner Brothers)-11 (1)
// 3 1 SOMEDAY WE’LL BE TOGETHER –•– Diana Ross and the Supremes (Motown)-9 (1)`;
return either(
msg => alert('Parsing chart rows')(msg)
)(
tabbedLines => tabbedLines
)(
bindLR(
clipTextLR()
)(
clip => clip.includes('–•–') ? (() => {
const rowParse = parse(chartListRow());
return Right(
lines(clip)
.flatMap(rowParse)
.map(
pair => fst(pair).join('\t')
).join('\n')
);
})() : Left('Clipboard contains no –•– lines.')
)
);
};
// ------------------- TRACK ROWS --------------------
// chartListRow :: Parser [String]
const chartListRow = () => {
const
integer = unsignedIntP(),
saucer = string('–•–'),
parenthesized = between(
char('(')
)(
char(')')
)(
many(satisfy(c => c !== ')'))
),
peak = token(
between(
char('(')
)(
char(')')
)(integer)
),
stringFromChars = cs => concat(cs).trim(),
asWord = fmapP(concat);
return bindP(
integer
)(tw => bindP(
integer
)(lw => bindP(
manyTill(item())(saucer)
)(title => bindP(
some(satisfy(c => '(' !== c))
)(artist => bindP(
parenthesized
)(label => bindP(
char('-')
)(_ => bindP(
integer
)(weeksInChart => bindP(
altP(sequenceP([peak]))(
sequenceP([
asWord(parenthesized),
asWord(peak)
])
)
)(onePeak => {
const peakOne = reverse(onePeak);
return pureP(
[
tw,
lw,
title,
artist,
label,
weeksInChart
]
.map(stringFromChars)
.concat(
1 < peakOne.length ? (
peakOne
) : peakOne.concat('')
)
);
}))))))));
};
// --------------------- PARSERS ---------------------
// Parser :: String -> [(a, String)] -> Parser a
const Parser = f =>
// A function lifted into a Parser object.
({
type: 'Parser',
parser: f
});
// altP (<|>) :: Parser a -> Parser a -> Parser a
const altP = p =>
// p, or q if p doesn't match.
q => Parser(s => {
const xs = parse(p)(s);
return 0 < xs.length ? (
xs
) : parse(q)(s);
});
// apP <*> :: Parser (a -> b) -> Parser a -> Parser b
const apP = pf =>
// A new parser obtained by the application
// of a Parser-wrapped function,
// to a Parser-wrapped value.
p => Parser(
s => parse(pf)(s).flatMap(
vr => parse(
fmapP(vr[0])(p)
)(vr[1])
)
);
// between :: Parser open -> Parser close ->
// Parser a -> Parser a
const between = pOpen =>
// A version of p which matches between
// pOpen and pClose (both discarded).
pClose => p => thenBindP(pOpen)(
p
)(
compose(thenP(pClose), pureP)
);
// bindP (>>=) :: Parser a ->
// (a -> Parser b) -> Parser b
const bindP = p =>
// A new parser obtained by the application of
// a function to a Parser-wrapped value.
// The function must enrich its output, lifting it
// into a new Parser.
// Allows for the nesting of parsers.
f => Parser(
s => parse(p)(s).flatMap(
tpl => parse(f(tpl[0]))(tpl[1])
)
);
// char :: Char -> Parser Char
const char = x =>
// A particular single character.
satisfy(c => x == c);
// digit :: Parser Char
const digit = () =>
// A single digit.
satisfy(isDigit);
// fmapP :: (a -> b) -> Parser a -> Parser b
const fmapP = f =>
// A new parser derived by the structure-preserving
// application of f to the value in p.
p => Parser(
s => parse(p)(s).flatMap(
first(f)
)
);
// item :: () -> Parser Char
const item = () =>
// A single character.
// Synonym of anyChar.
Parser(
s => 0 < s.length ? [
Tuple(s[0])(
s.slice(1)
)
] : []
);
// liftA2P :: (a -> b -> c) ->
// Parser a -> Parser b -> Parser c
const liftA2P = op =>
// The binary function op, lifted
// to a function over two parsers.
p => apP(fmapP(op)(p));
// lookAhead :: Parser a -> Parser a
const lookAhead = p =>
// A version of p which parses
// without consuming.
Parser(
s => p.parser(s).flatMap(
second(_ => s)
)
);
// many :: Parser a -> Parser [a]
const many = p => {
// Zero or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const some_p = p =>
liftA2P(
x => xs => [x].concat(xs)
)(p)(many(p));
return Parser(
s => parse(
0 < s.length ? (
altP(some_p(p))(pureP([]))
) : pureP([])
)(s)
);
};
// manyTill :: Parser a -> Parser e -> Parser [a]
const manyTill = p =>
// All of the matches for p before e matches.
// Wrapping e in lookAhead can preserve any
// string which matches e, if it is needed.
e => {
const
scan = () => altP(
thenP(e)(pureP([]))
)(
bindP(
p
)(x => bindP(
go
)(xs => pureP(
[x].concat(xs)
)))
),
go = scan();
return go;
};
// oneOf :: [Char] -> Parser Char
const oneOf = s =>
// One instance of any character found
// the given string.
satisfy(c => s.includes(c));
// parse :: Parser a -> String -> [(a, String)]
const parse = p =>
// The result of parsing a string with p.
p.parser;
// pureP :: a -> Parser a
const pureP = x =>
// The value x lifted, unchanged,
// into the Parser monad.
Parser(s => [Tuple(x)(s)]);
// satisfy :: (Char -> Bool) -> Parser Char
const satisfy = test =>
// Any character for which the
// given predicate returns true.
Parser(
s => 0 < s.length ? (
test(s[0]) ? [
Tuple(s[0])(s.slice(1))
] : []
) : []
);
// sequenceP :: [Parser a] -> Parser [a]
const sequenceP = ps =>
// A single parser for a list of values, derived
// from a list of parsers for single values.
Parser(
s => ps.reduce(
(a, q) => a.flatMap(
vr => parse(q)(snd(vr)).flatMap(
first(xs => fst(vr).concat(xs))
)
),
[Tuple([])(s)]
)
);
// some :: Parser a -> Parser [a]
const some = p => {
// One or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const many_p = p =>
altP(some(p))(pureP([]));
return Parser(
s => parse(
liftA2P(
x => xs => [x].concat(xs)
)(p)(many_p(p))
)(s)
);
};
// string :: String -> Parser String
const string = s =>
// A particular string.
fmapP(cs => cs.join(''))(
sequenceP([...s].map(char))
);
// thenBindP :: Parser a -> Parser b ->
// (b -> Parser c) Parser c
const thenBindP = o =>
// A combination of thenP and bindP in which a
// preliminary parser consumes text and discards
// its output, before any output of a subsequent
// parser is bound.
p => f => Parser(
s => parse(o)(s).flatMap(
vr => parse(p)(vr[1]).flatMap(
tpl => parse(f(tpl[0]))(tpl[1])
)
)
);
// thenP (>>) :: Parser a -> Parser b -> Parser b
const thenP = o =>
// A composite parser in which o just consumes text
// and then p consumes more and returns a value.
p => Parser(
s => parse(o)(s).flatMap(
vr => parse(p)(vr[1])
)
);
// token :: Parser a -> Parser a
const token = p => {
// A new parser for a space-wrapped
// instance of p. Any flanking
// white space is discarded.
const space = whiteSpace();
return between(space)(space)(p);
};
// parse :: Parser Int
const unsignedIntP = () =>
token(some(digit()))
// whiteSpace :: Parser String
const whiteSpace = () =>
// Zero or more non-printing characters.
many(oneOf(' \t\n\r'));
// ----------------------- JXA -----------------------
// alert :: String -> String -> IO String
const alert = title =>
s => {
const sa = Object.assign(
Application('System Events'), {
includeStandardAdditions: true
});
return (
sa.activate(),
sa.displayDialog(s, {
withTitle: title,
buttons: ['OK'],
defaultButton: 'OK'
}),
s
);
};
// clipTextLR :: () -> Either String String
const clipTextLR = () => (
v => Boolean(v) && 0 < v.length ? (
Right(v)
) : Left('No utf8-plain-text found in clipboard.')
)(
ObjC.unwrap($.NSPasteboard.generalPasteboard
.stringForType($.NSPasteboardTypeString))
);
// --------------------- GENERIC ---------------------
// Left :: a -> Either a b
const Left = x => ({
type: 'Either',
Left: x
});
// Right :: b -> Either a b
const Right = x => ({
type: 'Either',
Right: x
});
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
b => ({
type: 'Tuple',
'0': a,
'1': b,
length: 2
});
// bindLR (>>=) :: Either a ->
// (a -> Either b) -> Either b
const bindLR = m =>
mf => undefined !== m.Left ? (
m
) : mf(m.Right);
// compose (<<<) :: (b -> c) -> (a -> b) -> a -> c
const compose = (...fs) =>
// A function defined by the right-to-left
// composition of all the functions in fs.
fs.reduce(
(f, g) => x => f(g(x)),
x => x
);
// concat :: [[a]] -> [a]
// concat :: [String] -> String
const concat = xs => (
ys => 0 < ys.length ? (
ys.every(Array.isArray) ? (
[]
) : ''
).concat(...ys) : ys
)(list(xs));
// either :: (a -> c) -> (b -> c) -> Either a b -> c
const either = fl =>
// Application of the function fl to the
// contents of any Left value in e, or
// the application of fr to its Right value.
fr => e => 'Either' === e.type ? (
undefined !== e.Left ? (
fl(e.Left)
) : fr(e.Right)
) : undefined;
// first :: (a -> b) -> ((a, c) -> (b, c))
const first = f =>
// A simple function lifted to one which applies
// to a tuple, transforming only its first item.
xy => {
const tpl = Tuple(f(xy[0]))(xy[1]);
return Array.isArray(xy) ? (
Array.from(tpl)
) : tpl;
};
// fst :: (a, b) -> a
const fst = tpl =>
// First member of a pair.
tpl[0];
// isDigit :: Char -> Bool
const isDigit = c => {
const n = c.codePointAt(0);
return 48 <= n && 57 >= n;
};
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single
// string delimited by newline and or CR.
0 < s.length ? (
s.split(/[\r\n]+/)
) : [];
// list :: StringOrArrayLike b => b -> [a]
const list = xs =>
// xs itself, if it is an Array,
// or an Array derived from xs.
Array.isArray(xs) ? (
xs
) : Array.from(xs || []);
// reverse :: [a] -> [a]
const reverse = xs =>
'string' !== typeof xs ? (
xs.slice(0).reverse()
) : xs.split('').reverse().join('');
// sj :: a -> String
function sj() {
// Abbreviation of showJSON for quick testing.
// Default indent size is two, which can be
// overriden by any integer supplied as the
// first argument of more than one.
const args = Array.from(arguments);
return JSON.stringify.apply(
null,
1 < args.length && !isNaN(args[0]) ? [
args[1], null, args[0]
] : [args[0], null, 2]
);
}
// snd :: (a, b) -> b
const snd = tpl =>
// Second member of a pair.
tpl[1];
// MAIN
return main();
})();