I don't think the following can be done with Keyboard Maestro by itself. But perhaps some of you automation gurus have an idea how to do it:
I'm getting lots of scanned letters, invoices, etc. as PDF files. To sort them, I need them to be named after the date of the document they contain.
For instance, a PDF containing a letter that says "June 2nd 2017" would have to be named "170602 XYZ.pdf".
Right now, I'm doing this manually. I go through the PDFs in Finder, open QuickView using the [space] on my keyboard, and then look for the date inside the PDF and rename the file by pressing [Enter] and typing the number.
That is an idiot's task, and I'd be thrilled to get this "outsourced" to my computer's CPU.
I know that there are a couple of online services that use artificial intelligence / machine learning to identify data points such as dates or invoice amounts in PDF documents (one such example being autoentry.com).
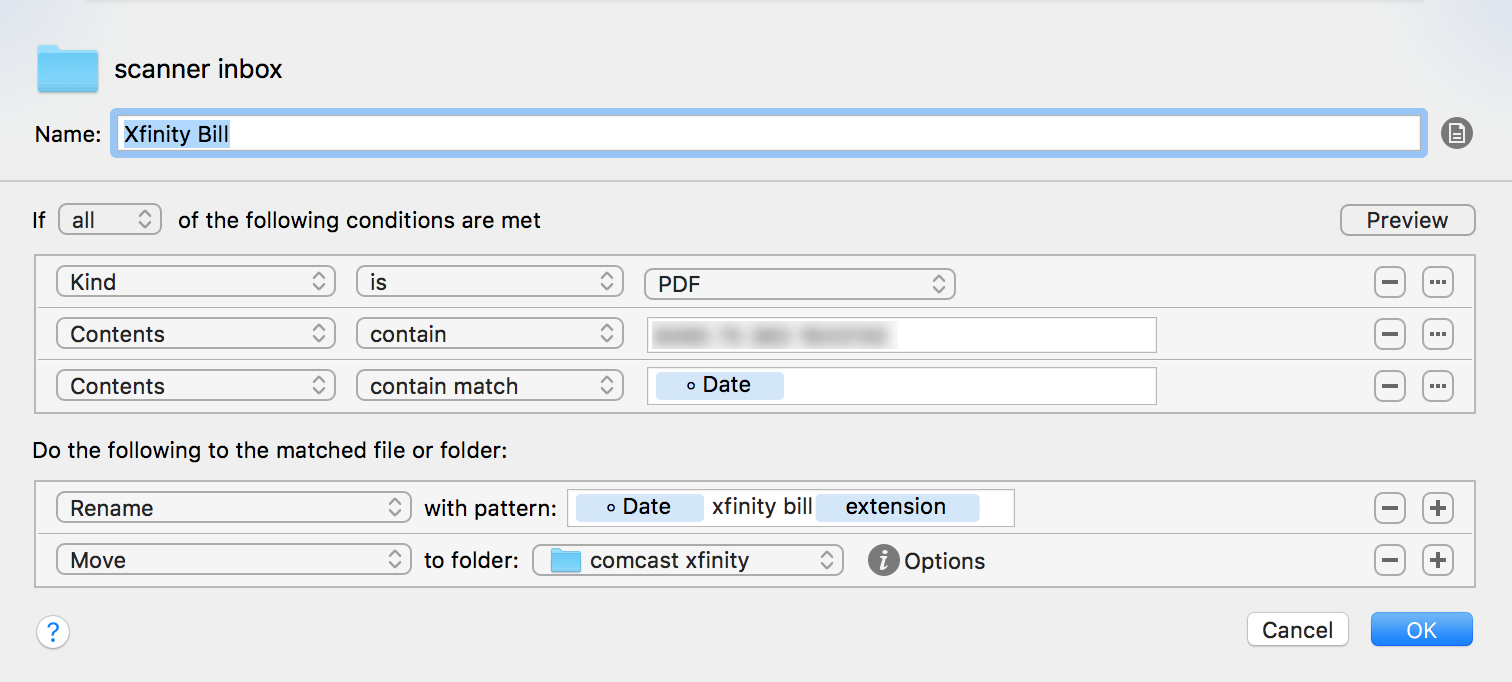
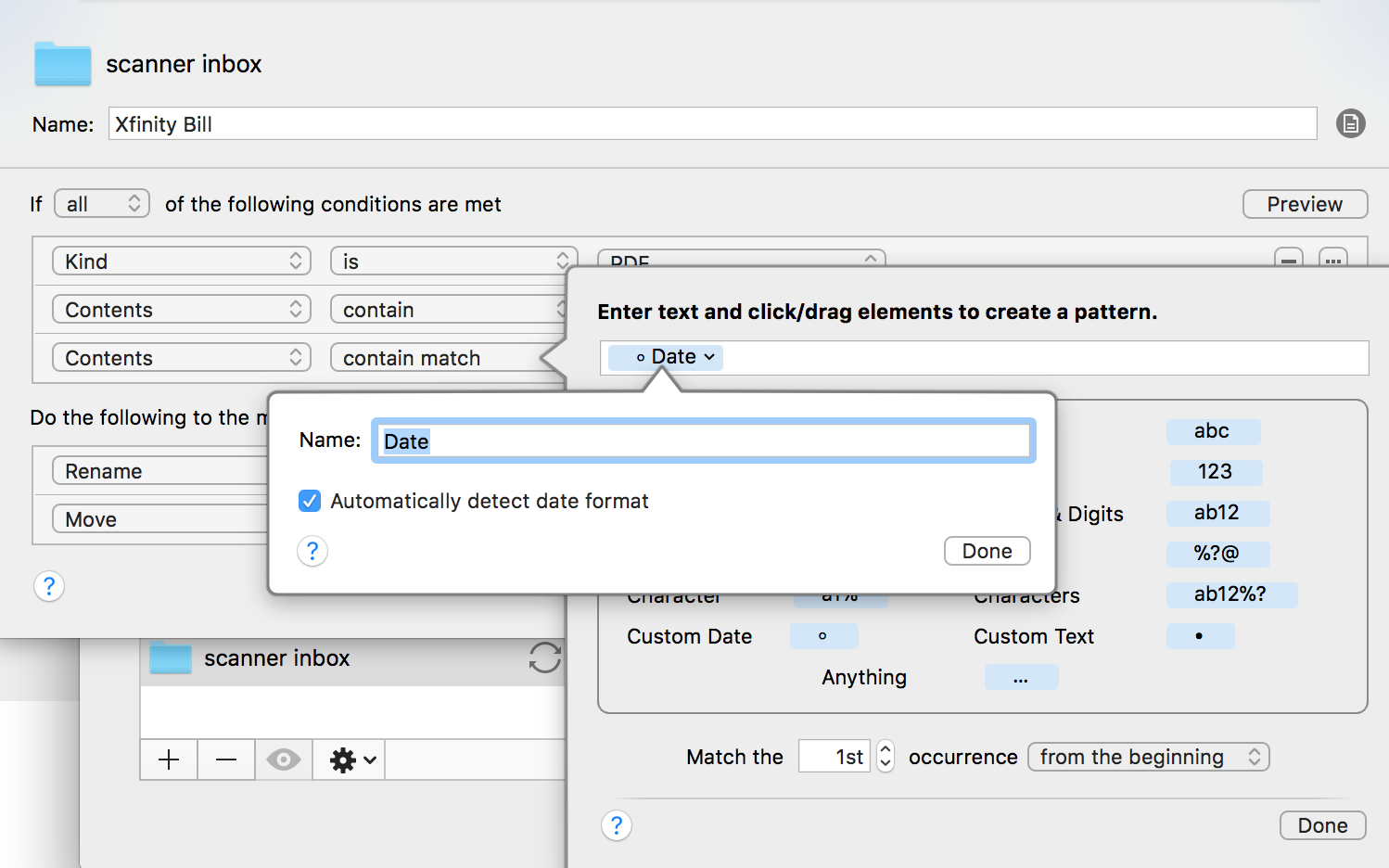
Another approach I think could be possible is to go down the path OCR > Regular Expression search. Meaning,
OCR each document
Search the text that was recognized for typical date patterns
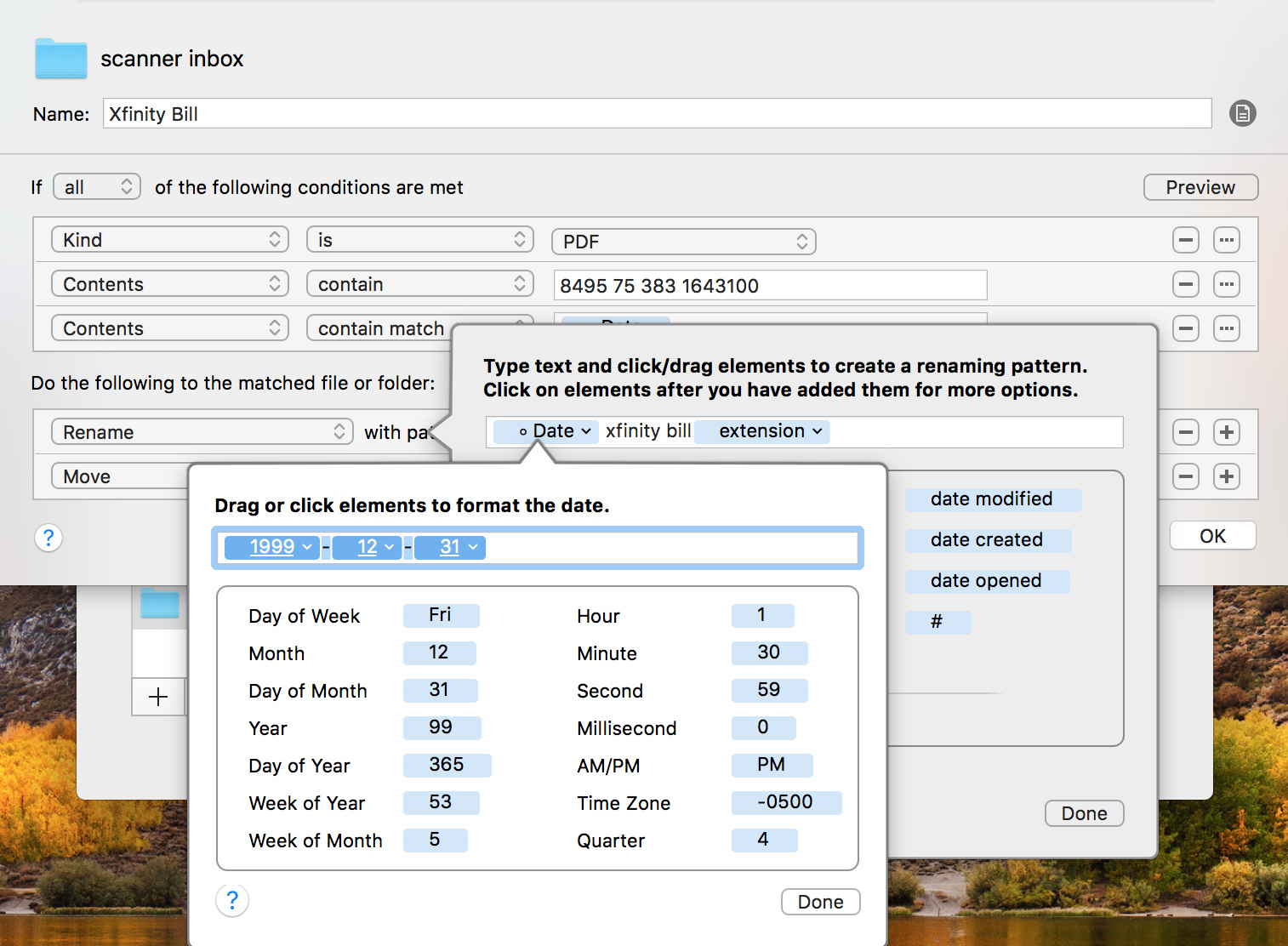
Convert date patterns into format YYMMDD
Rename the files where recognition was successful
Any ideas?
I'm attaching three sample documents (contents blurred with the exception of the date which would have to be extracted).
ABBYY has Automator workflows, too, but I found it unreliable - especially when OCRing documents in bulk. Accuracy is slightly better with ABBYY, I think.
My current workflow is:
Bulk OCR incoming documents using OCKit
A KBM script that…
runs mdimport to get the PDF’s embedded text
runs Regular Expressions on that in order to identify the date
It’s not perfect. It fails, for instance, if the OCR introduced wrong characters into the date, or if the sender used a date format that I did not forsee when writing my extraction rules.
It could be made better if I could somehow make the script factor in the position of the date string. So if multiple date patterns match in the document body, the script would always prefer the one that is isolated on the page, and on the top right as opposed to middle/center or bottom of the page.
Perhaps this could be achieved with Google Cloud Vision API, which seems to output recognized text blocks along with their coordinates on the page.
I see this is a 5-year old thread, but I do have the same request.
Have there been some improvements, dedicated scripts or anything in the last 5 years that would make the sorting of PDF by an OCR recognized date (with possible automated renaming of the file)?