OK, now I'm getting greedy, I need a little regex help if I could.
From the following text (always in the same format)
I'd like to get the first name and last name, as separate values, after the text "Next Candidate"
and the 10 digits on the right side of the line after the name.
NOTE ADDITION: There is also always additional text after the last line I displayed of 'Applied x days ago'. So please consider when testing if possible.
Back to Candidate List
MK
Previous Candidate
Next Candidate
Ria Batson
+1 929 225 7723
Applied 3 days ago
The only variable that could be at play is: when I'm on the last candidate, the term 'Next Candidate' is not there and this following text is obtained.
MK
Previous Candidate
Brielle Di Poalo
+1 908 601 5725
Applied 3 days ago
Ah, yes, it seems there is always a +1 at the start of the line.
If I could, I noticed another variable.
When it's the first candidate, the text is without a 'next candidate' or 'previous candidate'.
It is as follows....
MK
Dawn A. Weltzien
+1 9144130956
Applied 2 days ago
I agree with @ccstone that you might need some smarter logic to sort out which words are part of a family name and which are just personal names. Possibly more logic than regular expressions are really designed (or well equipped) to cope with.
(a scripting language – JavaScript or AppleScript or Python probably – will always give you more flexibility, and much more readability and ease of refactoring too).
Putting aside full name parsing, here is one way of getting the name and number into a single Keyboard Maestro JSON variable, in which you can refer directly to the parts you want (using the KM %JSONValue% token in lieu of the %Variable% token) in an idiom like:
Last name: %JSONValue%candidate.lastName%
First name: %JSONValue%candidate.firstName%
Full name: %JSONValue%candidate.fullName%
Phone: %JSONValue%candidate.phone%
Hey Chris, works great, can you get the phone number out of it?
I put your regex in regex101 site to try and understand what it's doing but I have no idea.
So it doesn't matter if there are more lines of text before or after the name and number? It still works, which is great, because in the final analysis, when I copy the webpage, there is more date/lines of text after the applied x days ago.
But again, I did a test and it works fine. Don't know why =)
If I could get the phone number out of it, I'd be good.
Thank you
Hey @ComplexPoint , thank you! It works good. On me is that I didn't let you know that there is always text beyond the line 'Applied 3 days ago' So I would have to first set a variable to the text before 'ago'......
I spent awhile looking at regex and googling to find a simple 'match everything before a word', and I'll be darned if I cannot find anything!!!!!
Also, with a name like Di Poalo - would it be possible to get the Di into a 'middle name' variable? then I could combine them if desired.... just a thought.
thank you much, seriously....
I just tried the macro in the 'real world' and it works great, I would like to know how it's working, it doesn't need to know if there is a 'previous' text or 'next' or neither of them. It just works! How is that?
So yeah, If you can get the phone number out of it, that would be great Chris, thank you so much.....
Troy
from the start of the complete text up to that word..... I should elaborate, apologies....
In my example above of the raw text being the following:
There is always more text beyond the last line that I showed, of "Applied x days ago"
there are always more lines of text in the 'scrape' that I do.
So you're solution works only if the line "Applied x days ago" is the last line.
So I thought IF I could figure out, or have you show me what would 'capture' only the text before the last word of 'ago' - I would do that in one step then run your current macro on the result and that would work.
I hope I am being clear.....
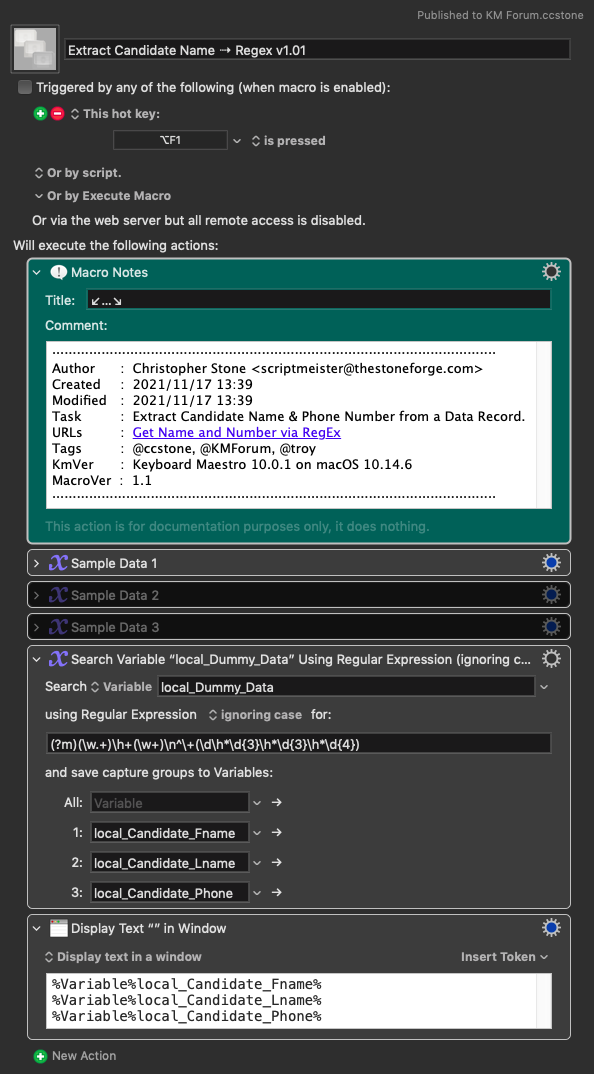
It works, because I'm anchoring on the phone number and going backwards from there to find the first line above and parsing using word characters and spaces.
(?m)(\w.+)\h+(\w+)\n^\+(\d\h*\d{3}\h*\d{3}\h*\d{4})
(?m) == Multiline switch.
(\w.+) == Capture group any word character 1 or more followed by any character 2 or more.
\h+ == Horizontal space 1 or more.
(\w+) == Capture group any word character 1 or more.
\n == Linefeed character.
^ == Beginning of line anchor.
\+ == Literal plus sign.
( == Start capture group.
\d == 1 digit.
\h* == Horizontal space - 0 or more.
\d{3} == Digit x 3.
\h* == Horizontal space - 0 or more.
\d{3} == Digit x 3.
\h* == Horizontal space - 0 or more.
\d{4} == Digit x 4.
) == Close capture group
split a text into easy chunks (perhaps with very simple regexes at each split), and then
work on the start or end of each chunk.
To simplify the automation of the chunking, and make it solid and readily intelligible (especially a month or two later) we would need to zoom back a bit and ask you for a picture of what you are actually doing.
Batch-converting a whole list of candidates to some other format ?
Selecting candidates one by one to compose candidate-specific documents ?