I am trying to extract numbers from some text and put each extracted number on a new line.
This is my text that is copied to clipboard:
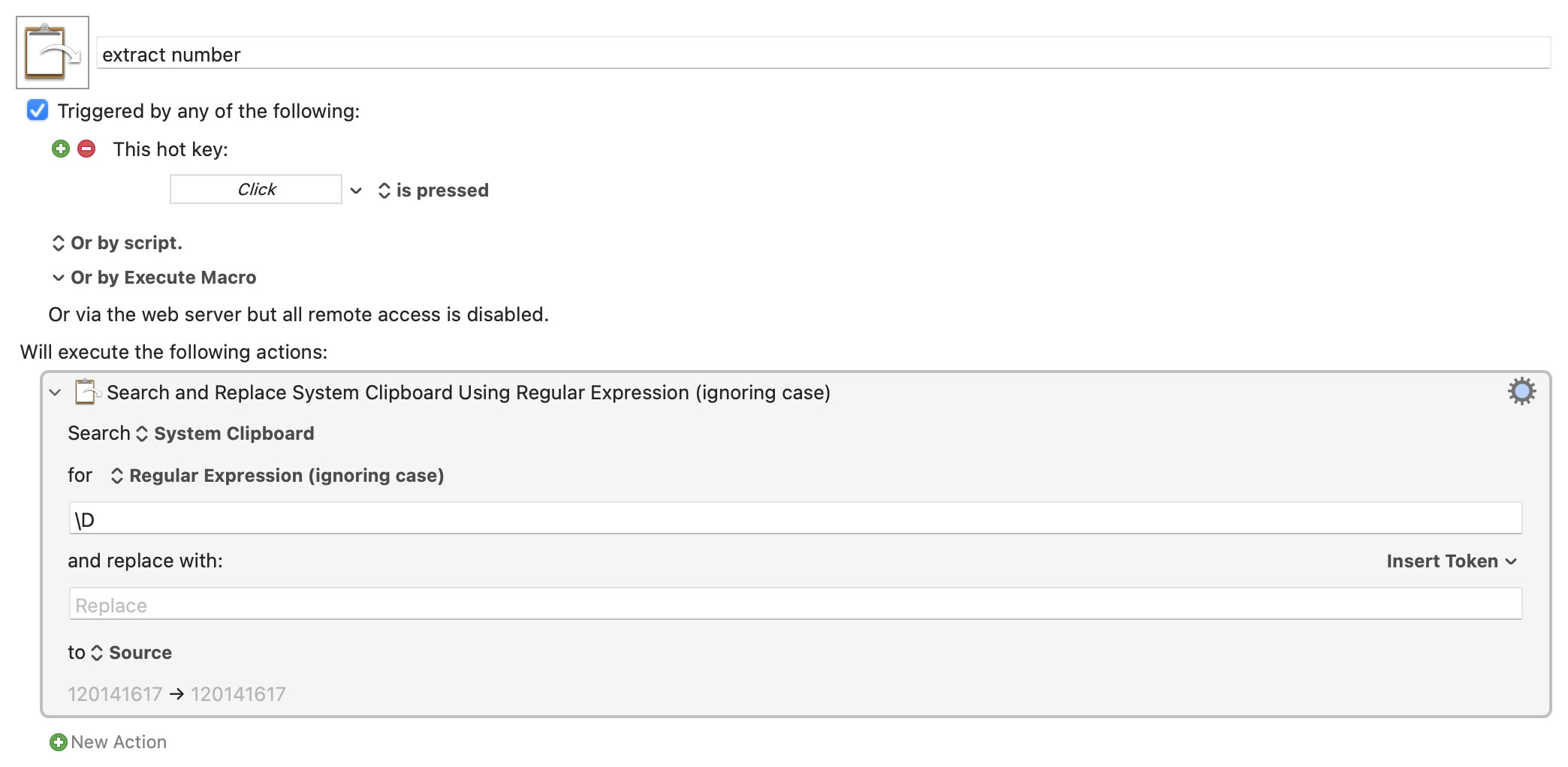
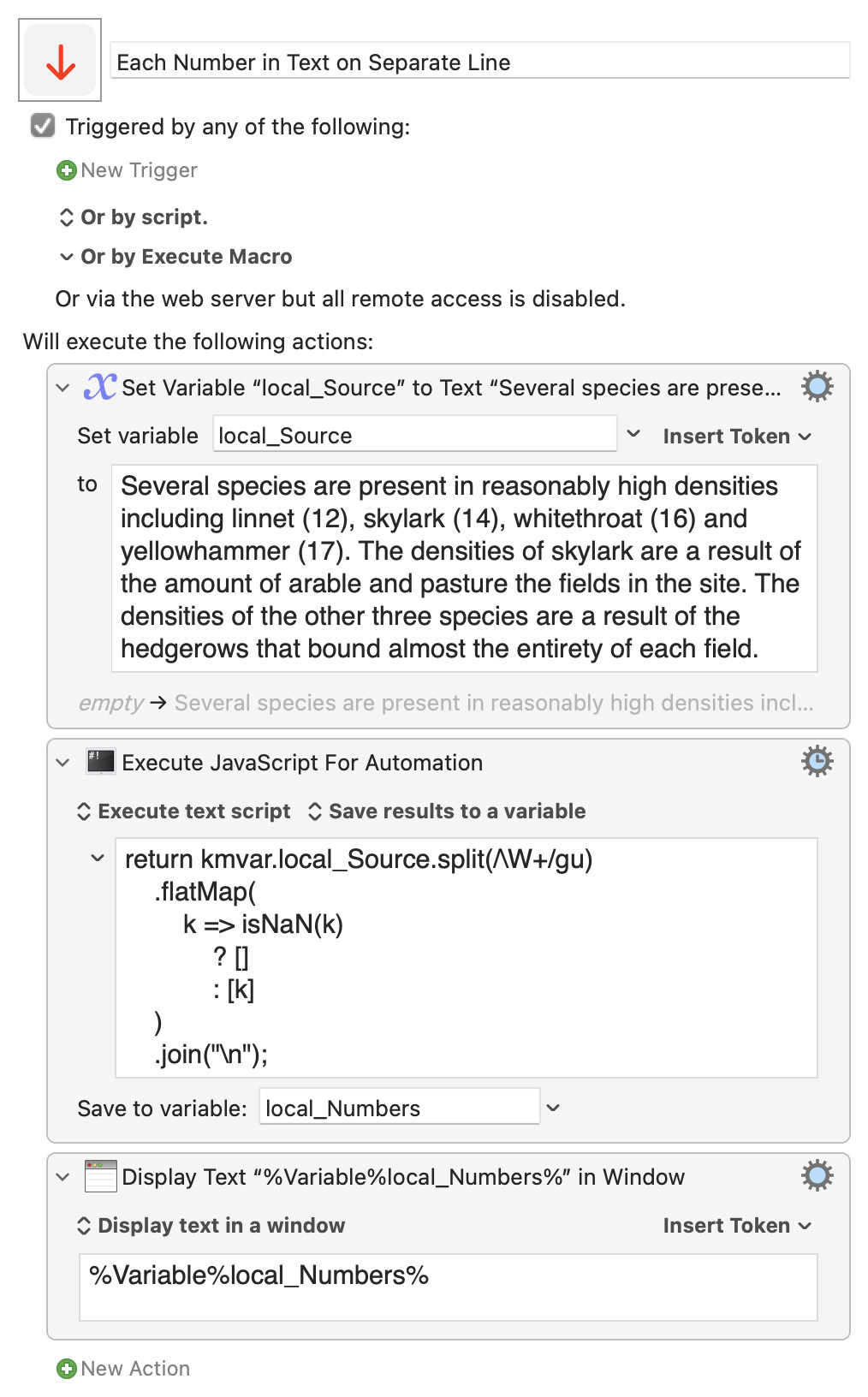
Several species are present in reasonably high densities including linnet (12), skylark (14), whitethroat (16) and yellowhammer (17). The densities of skylark are a result of the amount of arable and pasture the fields in the site. The densities of the other three species are a result of the hedgerows that bound almost the entirety of each field.
There's different ways to do this (most of them utilising regex), and if you change your macros search term to \D+, and replace with \n you should have a function version of your macro. Often times with a leading and trailing newline though, if that is a problem you could use the Filter action to Trim Whitespaces
The positive search would be something like \d+(\.\d+)?, and I am actually not sure how I could negate it, so here's an approach using this here pattern:
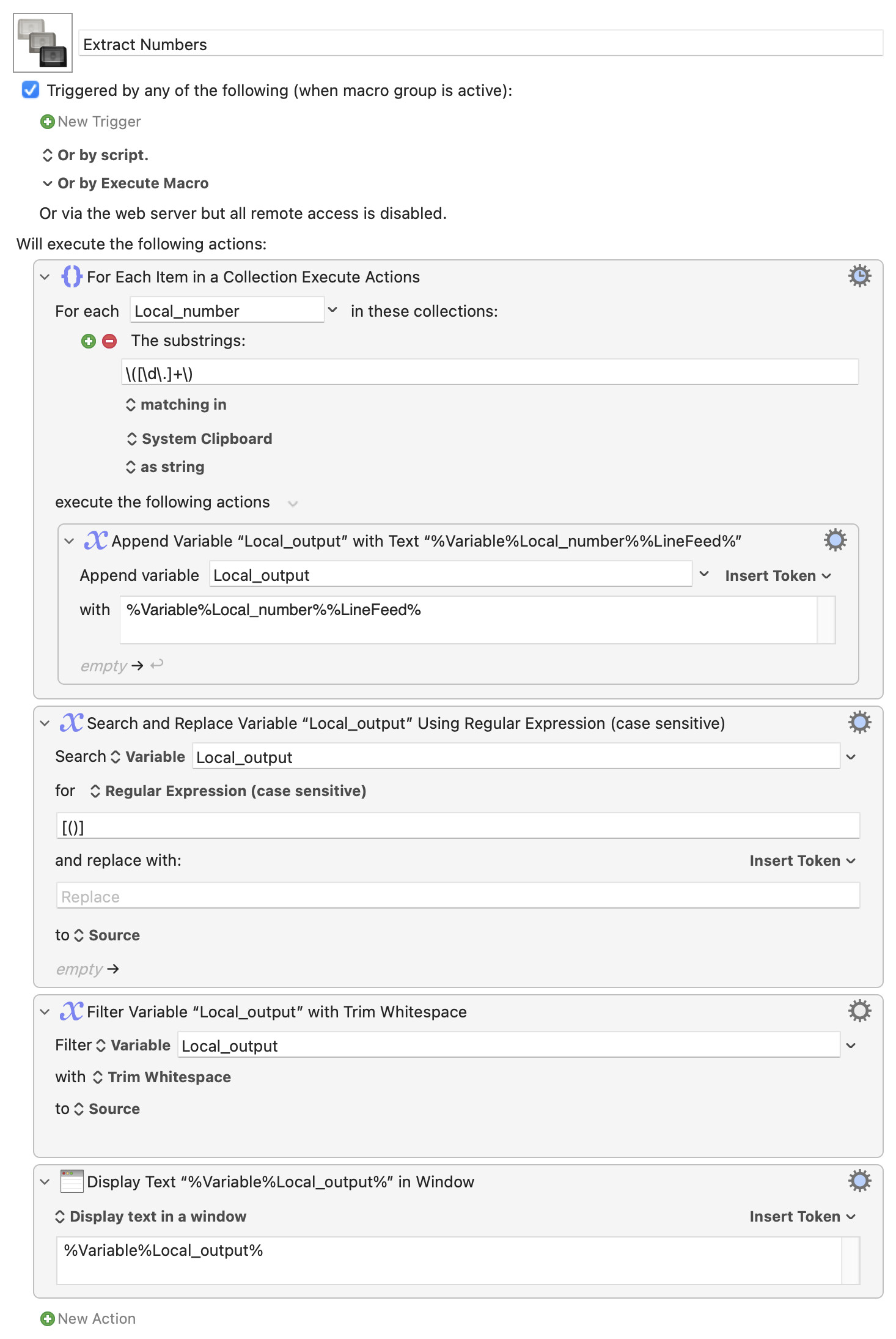
Probably the easiest -- and the most readable! -- way of doing this is via a "For Each..." action working on a Collection of substrings. Here I'm assuming that, as in your text, the numbers are always inside ( ) and can include decimals (although that isn't strict -- DUCY?):
Negate how? Numbers that aren't decimals -- just miss out the decimal point as you did before. If you want only decimals, insist on a single decimal point followed by at least 1 digit: \d*\.\d+
I am probably not using the right term. With 'negation' I meant a patern that captures the opposite of \d+(\.\d+)? — as in matching all character that isn’t a consecutive string of number, possibly followed by a period and a another string of consecutive numbers. After searching a bit around I am beginning to think that this might not be possible with Regex alone.
But there are good workarounds, and I think doing a positive search iterating through and capturing all matches, as you also did, makes the more sense here. So my question was mostly in the hopes of finding means to relieve my itching curiosity.
But I'm not sure what you mean by the opposite of that -- particularly the optional part. As always with regex, some examples of matching and non-matching strings would help.
I think it is probably not possible, but the pattern I am thinking of is the pattern that could be used to return exactly the same as my uploaded macro above, only following OP’s original approach with a simple search and replace, searching for for anything that isn’t a (decimal) number, replacing with \n, instead of the For each iteration.
Example input:
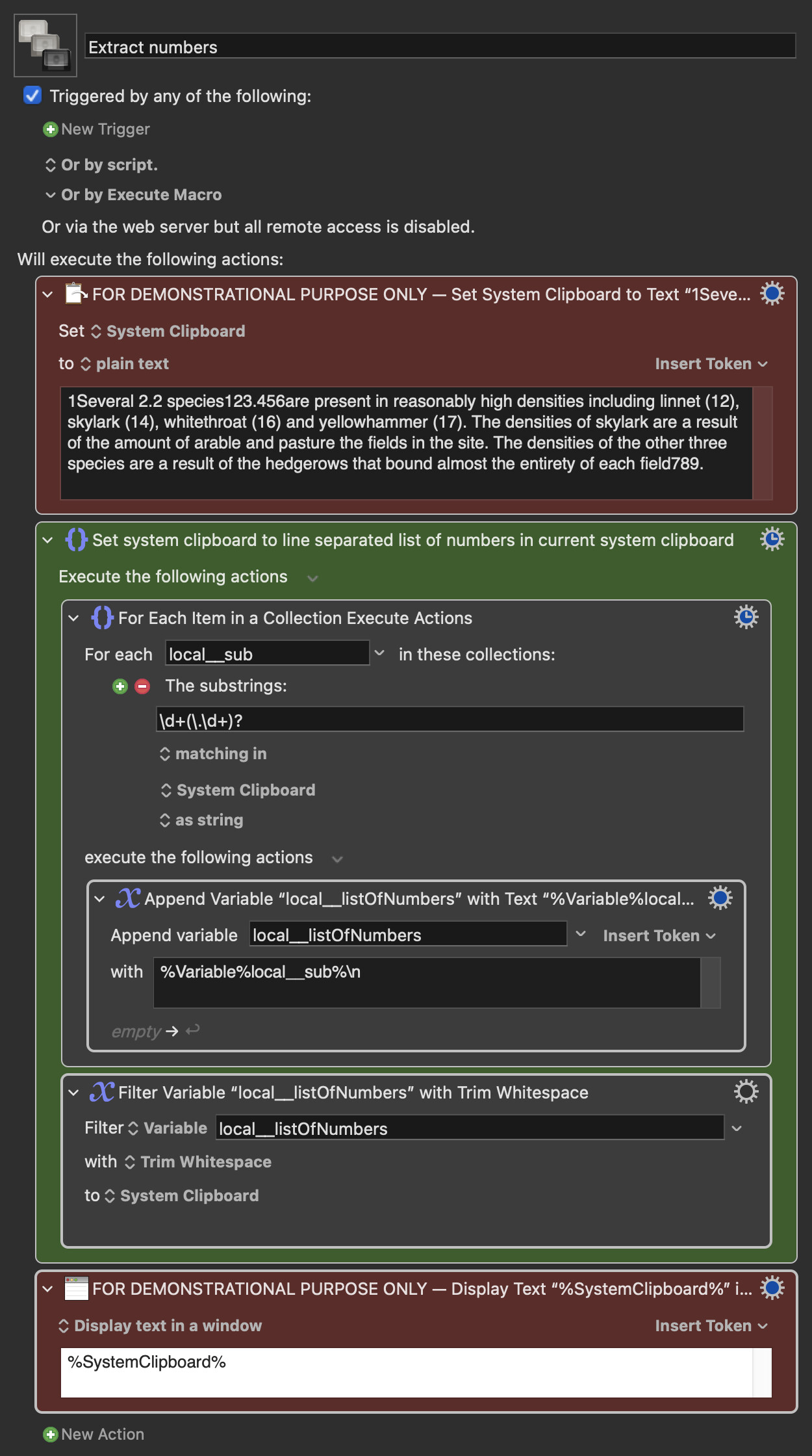
1Several 2.2 species123.456are present in reasonably high densities including linnet (12), skylark (14), whitethroat (16) and yellowhammer (17). The densities of skylark are a result of the amount of arable and pasture the fields in the site. The densities of the other three species are a result of the hedgerows that bound almost the entirety of each field789.
Output should be:
1
2.2
123.456
12
14
16
17
789
In kind of an extreme simplification I was thinking of a pattern that would 'negate' \d+(\.\d+)? in the same way that \D 'negates' \d. All though I of course see that it is not the same negating a composed pattern as it is negating a simple character class.
I think you'll need to look at lookaheads -- my brain starts to melt at that point. And they'd be a lot less efficient than your "For Each" (or that may just be my excuse for not trying harder ).
What you could do is split it into two ops
Search [^\d\.]+ and replace \n to get rid of all but digits and points
Search (?m)(^\.\n|\.$) and replace with nothing to get rid of the old full stops, now on lines by themselves, and any period at the end of a line.
I'm back from vacation and I wanted to offer an alternate solution.
That produces the requested output. Then you subsequently added a new request for including decimals as part of the numbers. My solution ALMOST solves that if you include a decimal after the 9 in my solution (see below.)
The problem with decimals is that now you have to start worrying about context. For example, using the alternate sample text, my code with a decimal will produce:
1
2.2
123.456
12
14
16
17
.
.
789.
You can see a couple of problems in that output. First, there are a couple of lines containing just "." which are the periods in some sentences. (That's easy to fix.) The second problem we see is that the final line is "789." which comes with a period. Since both "789" and "789." are both potential valid results, it's unclear why the "789" in the example provided above should NOT include the period. Is the code supposed to understand the difference between a period used in an English sentence and a period that is not part of English punctuation? "Understanding English" is not something any script can do, even with regex and lookahead.
Yes, I can see your error. You are using a capital letter "I" (the letter between H and J) instead of a vertical bar, which we call the pipe character (which is usually above the RETURN key.)
What the script (and macro) does is replace any character that is not a numeric character with a newline, then removes all empty lines using the grep command. You need the pipe character to make it work.