I'm hoping someone can please point me in the right direction with a macro I've cobbled together with the help of many forum threads and macros provided by the very helpful people in this community.
The core of the macro is working correctly, but I need to modify the way it behaves with looping behaviours. This is where I'm stuck, because I am still learning both Keyboard Maestro and general code logic.
(Thank you to @JMichaelTX, who created a macro based on an example in this forum by @ccstone. I have used most or all of his macro for this project!)
Overall Objective
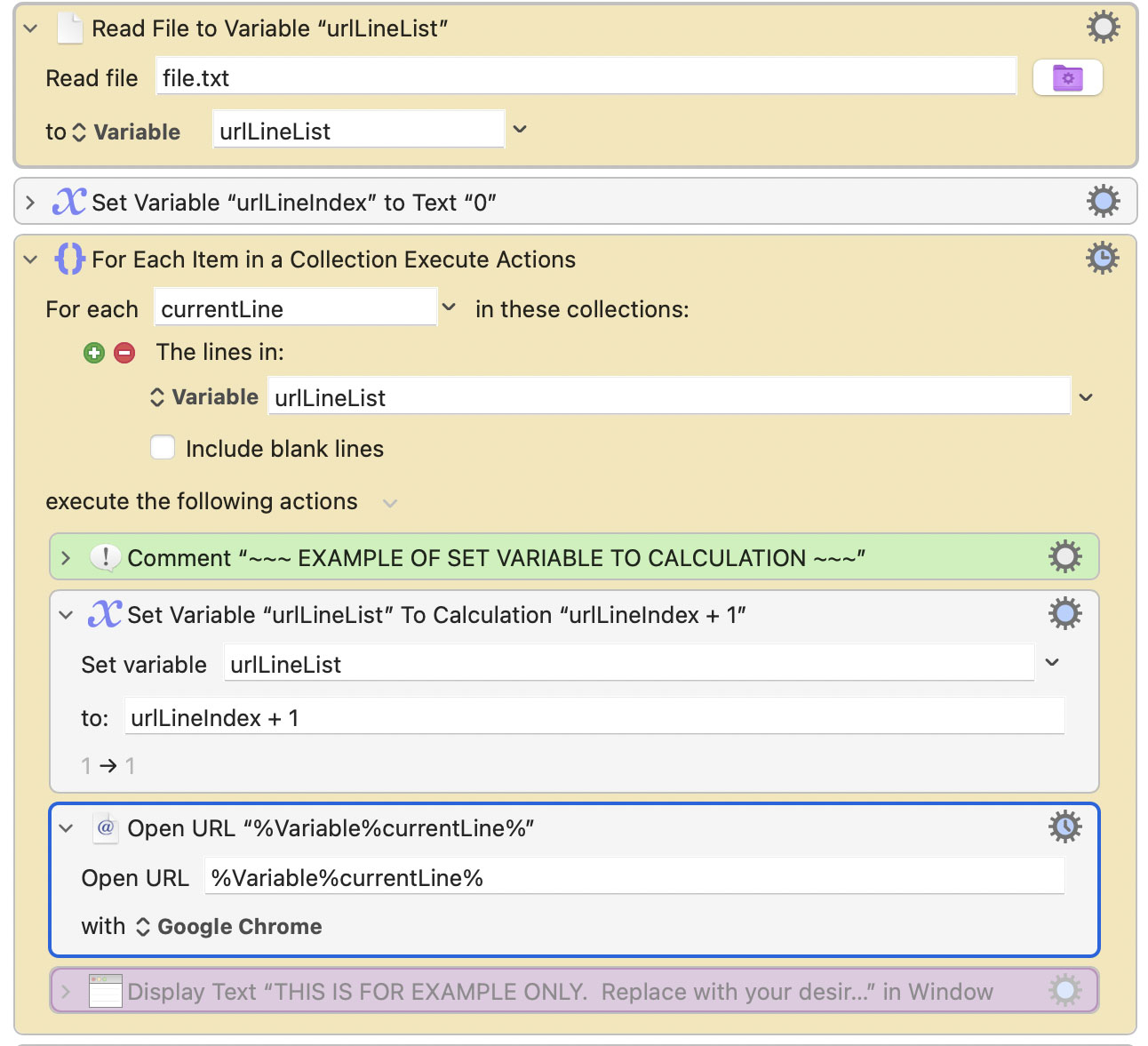
Save 1000+ URLs via Google Chrome (specifically - not Firefox or Safari), by drawing URLs from a text file (which contains each URL as a new line).
Save the first URL (line 1) of the text file as a variable.
Open this first URL in Google Chrome.
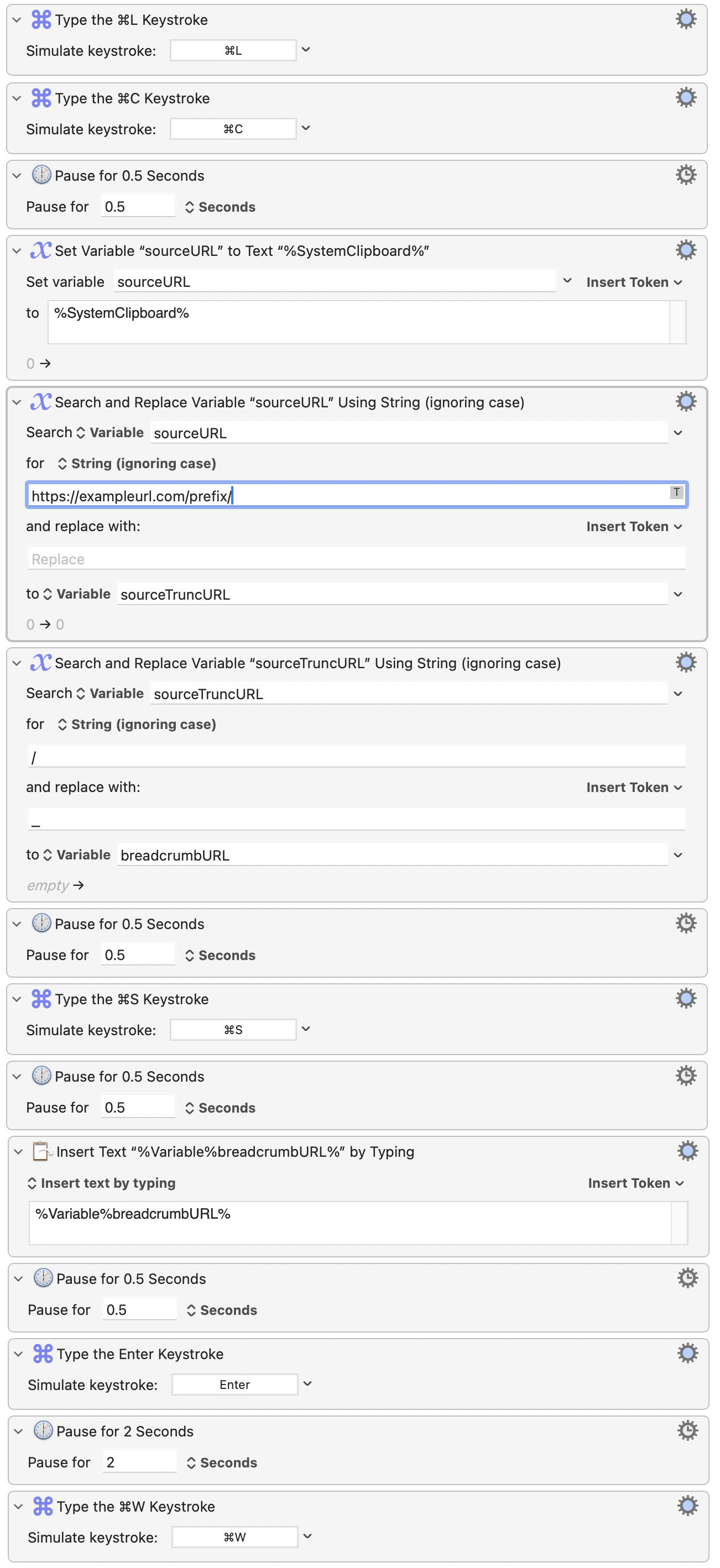
Search the this URL and replace the URL prefix (e.g. https://exampleurl.com/prefix/) with nothing, so that only the thisisthe/urlpart/toextract/forsaving suffix remains.
Save this URL suffix as a new variable (sourceTruncURL).
Search for all / characters within variable sourceTruncURL and replace with _
Save this modified URL suffix as a new variable (breadcrumbURL).
Save the current webpage using Cmd+S.
Type the variable breadcrumbURL into the file save bar and hit Enter to save (so that the webpage output name is thisisthe_urlpart_toextract_forsaving).
Close the webpage with Cmd+W.
Move to the second URL (line 2) of the text file, and repeat above.
Repeat until all URLs have been completed.
Problem
I originally had all of the macro actions embedded within the For Each loop (see below), but this opened all URLs at once, before iterating through the Save/Close actions, and nearly crashed Chrome in the process!
Thoughts
I figure I probably need to restructure the order/nesting of the For Each loop, or have some kind of means to stop one part of the macro before executing the next part. But I am not really sure how to structure this to cater for the one-by-one approach AND to continue looping throughout all URLs of the text file.
Any ideas/tweaks would be much appreciated. (If you think a different approach altogether would make more sense, I'm happy to hear your thoughts!)
I'm trying to understand the problem, which took a while because I don't use Chrome and therefore I don't know what you are doing with those hotkeys. But I think I figured it out. You have a long list of URLs in a file and you want to download those URLs using Chrome and save each page in a file using the URL as the basis of the filename but fixing up the URL so that any illegal characters for a filename are replaced by legal characters.
Is that accurate? I'm pondering it. One thing I'm pondering is whether to try to fix your macro or show you a more effective way to do that. Sometimes it's better to just patch up a macro, while sometimes it's better to show another way.
Thanks for your reply! I can see now that I didn't explain the URL cleanup part very well, so I'll go back and edit that now. I appreciate you taking the time to ponder this
Believe it or not, what you are trying to do is a common thing for people to do, and there are ways to do that in a single line of code. I'm googling it now, because I'm not very experienced at doing this myself. However even if I show you a single line of code that can do it, you have the right to insist upon using KM's loop feature.
Here's an example of how to do what you are basically trying to do in a single line. It reads lines of URLs from a file named ~/data/sample/url.txt and places all the output files in the same directory.
The problem with this solution is that it doesn't give your output filenames a clean version of your URL. I'm trying to fix that now. I'm enjoying trying to make it work for you.
Okay this is one step closer to what you want:
It saves each file using the name of the URL and replaces "/" with "_". It doesn't use your breadcrumb URL yet. I'm not sure why you want to do that. Is this the kind of thing you want to do? I can probably fix the breadcrumb issue if you want.
In order to make my solution work without error, I would need to see a list of all the characters that may be found in your url.txt file. That's because some characters found in URLs are illegal to use in filenames. I can fix that easily enough. They are:
#%{ }&< >*?$!:@+|= (and all quotes " ' `)
Due to the fact that there are special characters in that last KM action, I'll paste them here for your easy use:
cd ~/data/sample
for i in $(cat url.txt); do curl "$i" -o `echo $i | tr "/" "_" `; done
Thank you again @Airy for this! I'll give this a try and let you know how it goes!
The breadcrumb part is important, because I want to avoid saving the full URL into the filenames (especially as some of the filenames, based on the URL, can get quite long). It would also cause issues with special characters. The breadcrumb part is the important identifier for the pages
The only special characters that would be found in the breadcrumb portion of the URLs are hyphens. The rest are just alphanumeric characters.
That's very easy to fix. I'll try to fix it right now. But you will have to test it.
But now I'm suddenly confused. Show me 3 examples of URLs and what you expect them to be saved as. Don't use a verbal description. Show me three actual examples, even if they are hypothetical.
Since you haven't responded, I'll start you off. What are the names of the three files my program would have to create if these were the three URLs. Just give me the three filenames.
I completely forgot to mention that it's important that the webpage is saved via the browser, because the website is rendered using JSON and so other approaches (such as wget) haven't worked. Would your approach cater for this?
I have no idea. I've never had any trouble with any website I've tried in the past, but I haven't tried every web page on the Internet, and I don't think you've told us what your websites are. So I can't test it.
If you discover that you need to use a browser, then you can revert to your original plan, but I'll be leaving on vacation in a couple of days so I may not be able to help.