So, for example, we can narrow down from:
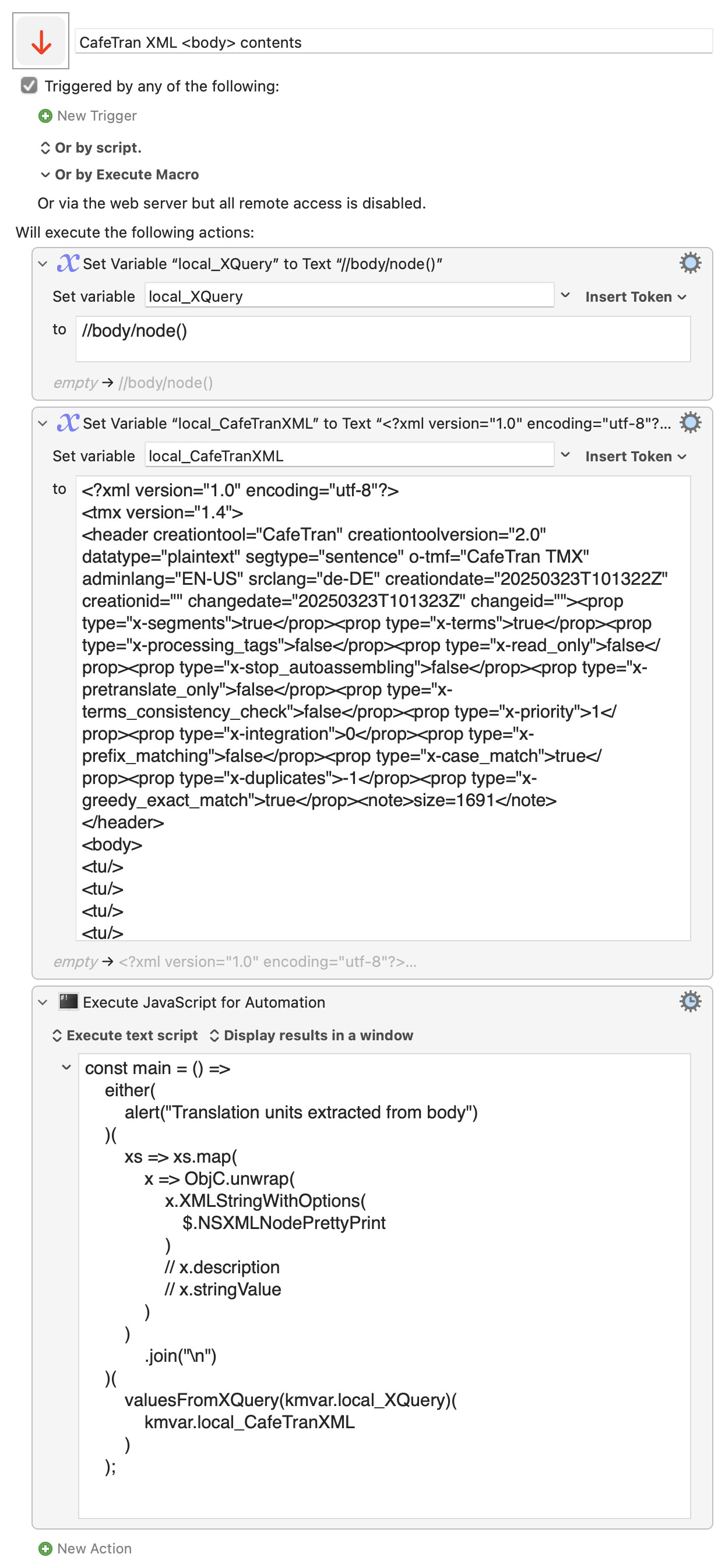
//body/node()
to the <tuv> segments contained in those nodes
//body/node()/tuv
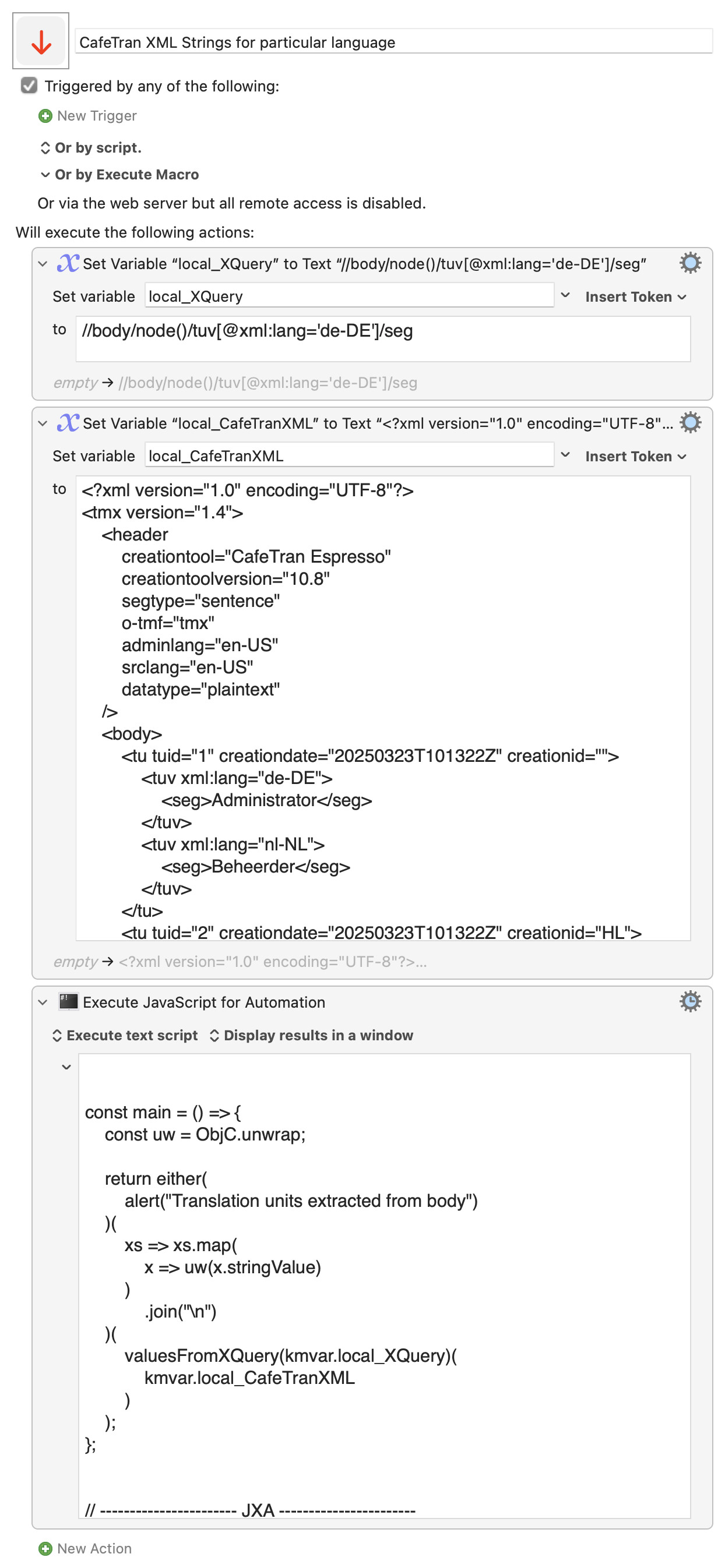
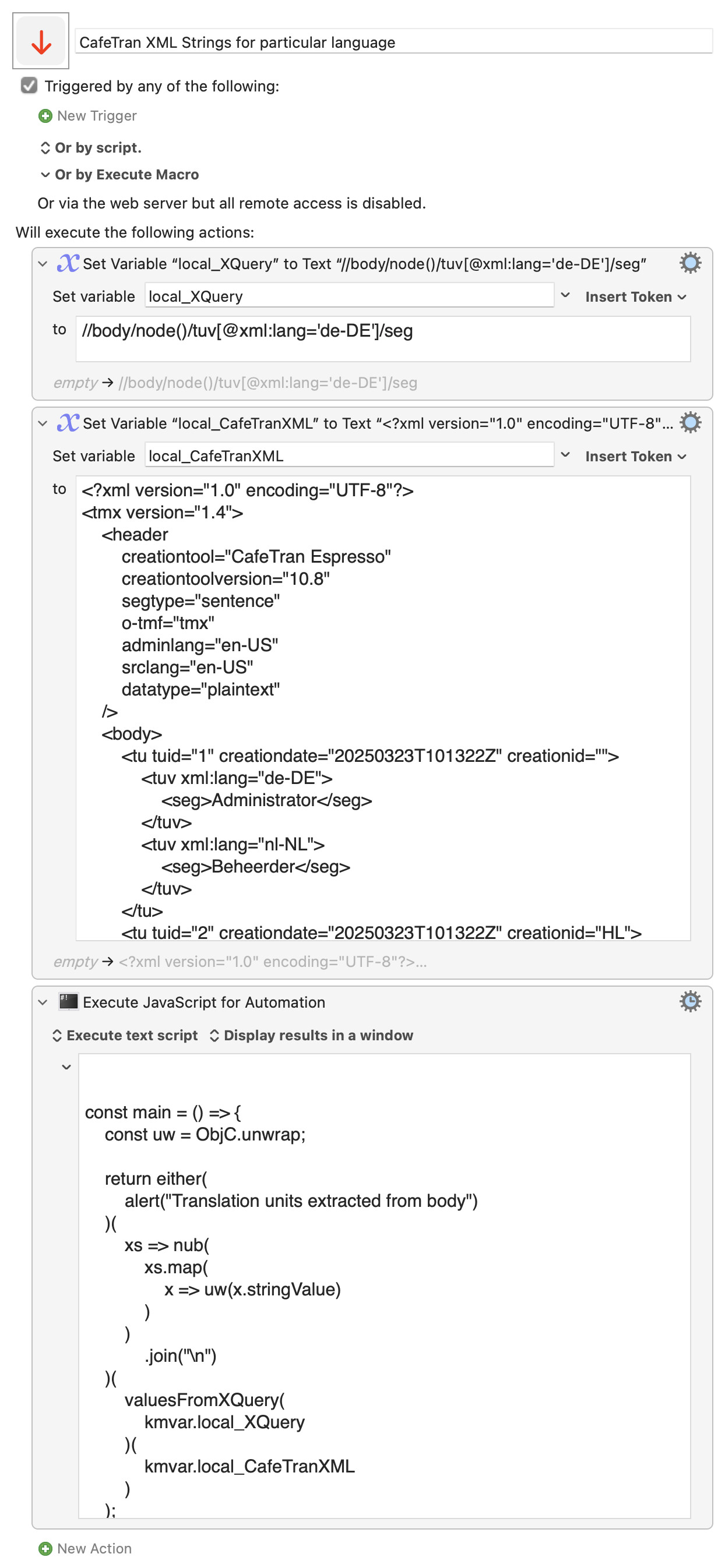
and filtering down, with a condition, to only those <tuv> elements in which the value of the xml:lang attribute is 'de-DE'
//body/node()/tuv[@xml:lang='de-DE']
and more specifically to the <seg> elements within de-DE <tuv> elements:
//body/node()/tuv[@xml:lang='de-DE']/seg
XPath expressions can typically be written in more than one way.
With your data here, we could also write:
//body/tu/tuv[@xml:lang='de-DE']/seg
or for those de-DE <seg> elements, just:
//tuv[@xml:lang='de-DE']/seg
And in the JavaScript return expression, we specify that what interests us is not pretty-printed XML, but just the text content of the filtered elements:
// x => uw(x.XMLStringWithOptions($.NSXMLNodePrettyPrint))
x => uw(x.stringValue)
e.g.
CafeTran XML Strings for particular language.kmmacros (7.2 KB)
Expand disclosure triangle to view JS source
const main = () => {
const uw = ObjC.unwrap;
return either(
alert("Translation units extracted from body")
)(
xs => xs.map(
x => uw(x.stringValue)
)
.join("\n")
)(
valuesFromXQuery(
kmvar.local_XQuery
)(
kmvar.local_CafeTranXML
)
);
};
// ----------------------- JXA -----------------------
// alert :: String => String -> IO String
const alert = title =>
s => {
const sa = Object.assign(
Application("System Events"), {
includeStandardAdditions: true
});
return (
sa.activate(),
sa.displayDialog(s, {
withTitle: title,
buttons: ["OK"],
defaultButton: "OK"
}),
s
);
};
// --------------------- XQUERY ---------------------
// valuesFromXQuery :: XQuery String -> XML String -> Either String [a]
const valuesFromXQuery = xq =>
xml => {
const
uw = ObjC.unwrap,
eXML = $(),
docXML = $.NSXMLDocument.alloc
.initWithXMLStringOptionsError(
xml, 0, eXML
);
return bindLR(
docXML.isNil()
? Left(uw(eXML.localizedDescription))
: Right(docXML)
)(
doc => {
const
eXQ = $(),
xs = doc.objectsForXQueryError(xq, eXQ);
return xs.isNil()
? Left(uw(eXQ.localizedDescription))
: Right(uw(xs));
}
);
};
// --------------------- GENERIC ---------------------
// Left :: a -> Either a b
const Left = x => ({
type: "Either",
Left: x
});
// Right :: b -> Either a b
const Right = x => ({
type: "Either",
Right: x
});
// bindLR (>>=) :: Either a ->
// (a -> Either b) -> Either b
const bindLR = lr =>
// Bind operator for the Either option type.
// If lr has a Left value then lr unchanged,
// otherwise the function mf applied to the
// Right value in lr.
mf => "Left" in lr
? lr
: mf(lr.Right);
// either :: (a -> c) -> (b -> c) -> Either a b -> c
const either = fl =>
// Application of the function fl to the
// contents of any Left value in e, or
// the application of fr to its Right value.
fr => e => "Left" in e
? fl(e.Left)
: fr(e.Right);
// MAIN ()
return main();