I agree with @ComplexPoint about using a parser instead of a regex—or maybe in combination with a regex—when you have structured text like JSON or XML. The parser will simplify your work and will handle edge cases better. This assumes that your structured text is complete and well formed (what’s in the original post isn’t, although I assume that was because it was a quick copy and paste from something that was complete and well formed) and that you have a parser handy.
JavaScript is a natural choice for a JSON parser, but there are lots of them around. If you use Homebrew, it’s easy to install jq, which has some really nice features for extracting and manipulating JSON data. It also integrates well with Keyboard Maestro because it communicates via standard input and output.
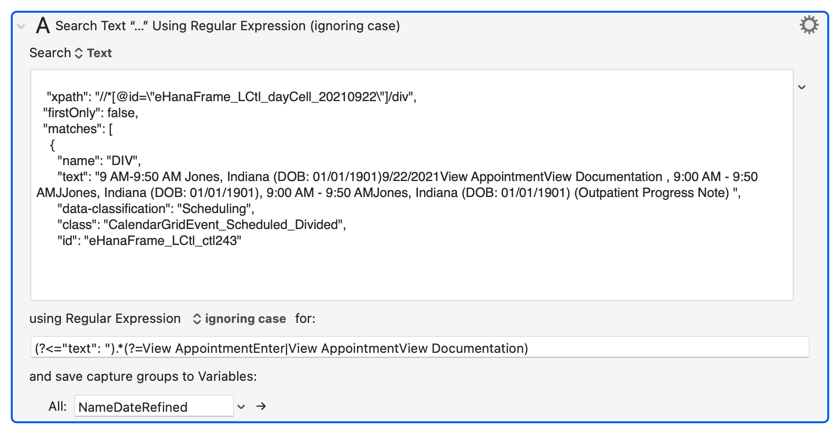
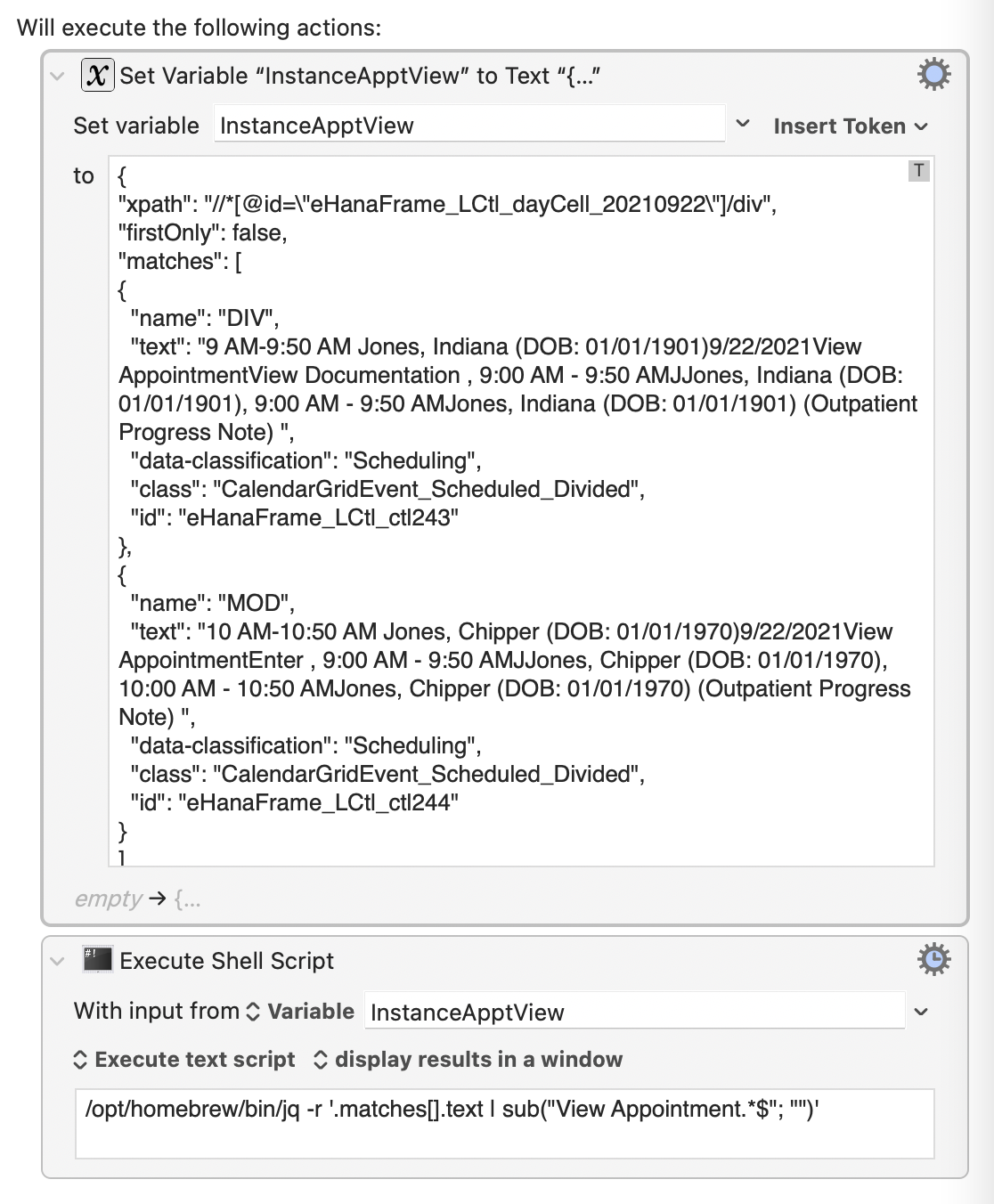
Here’s a quick example:
You can download the macro itself from here: Appointment.kmmacros (2.7 KB)
The example text is
{
"xpath": "//*[@id=\"eHanaFrame_LCtl_dayCell_20210922\"]/div",
"firstOnly": false,
"matches": [
{
"name": "DIV",
"text": "9 AM-9:50 AM Jones, Indiana (DOB: 01/01/1901)9/22/2021View AppointmentView Documentation , 9:00 AM - 9:50 AMJJones, Indiana (DOB: 01/01/1901), 9:00 AM - 9:50 AMJones, Indiana (DOB: 01/01/1901) (Outpatient Progress Note) ",
"data-classification": "Scheduling",
"class": "CalendarGridEvent_Scheduled_Divided",
"id": "eHanaFrame_LCtl_ctl243"
},
{
"name": "MOD",
"text": "10 AM-10:50 AM Jones, Chipper (DOB: 01/01/1970)9/22/2021View AppointmentEnter , 9:00 AM - 9:50 AMJJones, Chipper (DOB: 01/01/1970), 10:00 AM - 10:50 AMJones, Chipper (DOB: 01/01/1970) (Outpatient Progress Note) ",
"data-classification": "Scheduling",
"class": "CalendarGridEvent_Scheduled_Divided",
"id": "eHanaFrame_LCtl_ctl244"
}
]
}
where I’ve added another entry and the necessary brackets and braces to fill out a complete JSON structure. This is fed as standard input to the shell command
/opt/homebrew/bin/jq -r '.matches[].text | sub("View Appointment.*$"; "")'
which extracts the text from each of the matches, gets rid of everything from “View Appointment” until the end, and returns the results, one per line,
9 AM-9:50 AM Jones, Indiana (DOB: 01/01/1901)9/22/2021
10 AM-10:50 AM Jones, Chipper (DOB: 01/01/1970)9/22/2021
which you can then process however you like in Keyboard Maestro.
(Be careful about the path to jq; Homebrew may install it in a different place on your computer.)
As in @ComplexPoint’s solution, the use of a parser to pull out the text makes the subsequent manipulation much simpler. His split("ViewAppoint") doesn’t use regular expressions at all; my sub("View Appointment.*$"; "")—a substitution command in jq—is barely a regex.
The cost of this simpler manipulation is that you have to break out of Keyboard Maestro itself and use some outside tool. I think it's worth the cost, but everyone values things differently.