Disclaimer: I just started to learn RegEx maybe 2 months ago. So what I'm going to say might not be technically correct. But I hope I have made my point.
From the wiki page, I learned that there are PCRE and ICU Regular Expressions, and KM follows the latter.
I have used RegEx in PHP, JS, Python. I guess these belong to PCRE, because as far as I understand the /g modifier in these languages will return all matches. This is the definition of global as I understood it.
Therefore, what the KM wiki page says (screenshot above) is not true. Or to speak more accurately, while the search is global, it returns only the first match, not all matches. In order to get all matches, we have to use the "For Each" action and then append each match to another variable.
For instance, if we use /g to search for apple in apple banana apple orange, we would expect the returned result to be something like appleapple, or apple apple, or apple,apple, or [apple,apple], depending on whether it is a string or an array, or what the text delimiter is (nothing, space, comma, linebreak, etc.).
But KM will return only the first match, i.e., apple.
My suggestion is: is it possible to add the (?g) modifier to the RegEx search action?
I think the only problem is to set a text delimiter (array is probably not an option here). The simplest is to pre-assign one, like one of those mentioned above (nothing, space, comma, linebreak, etc.).
Another option (preferred) is: once the user adds (?g) modifier, KM will add an option to allow the user to set a text delimiter (nothing, space, comma, linebreak, etc.).
This will make it a global search that returns the same result as other tools that use the modifier /g.
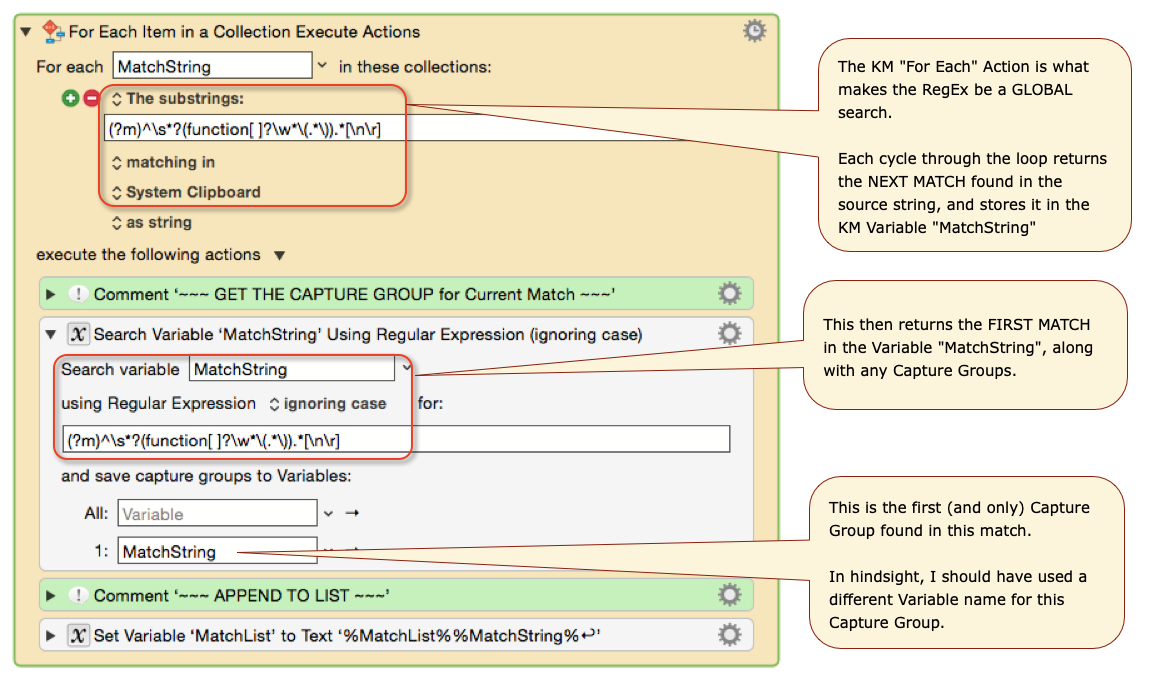
The Search using Regular Expression Action will return the first match it finds in the source string.
In order to make it be a “global” search, you need to put this Action in a For Each Action that uses the [ Substrings Matching in ] Collection. This will loop through all matches found in the source string.
This is often indicated in other tools by the /g modifier.
and this screenshot that I posted in your other thread will also help:
I still think a g modifier is handle so that we don't need to use the for each loop to get all the matches.
I guess the challenge is that KM does not seem to have array as variable (correct me if I'm wrong) and a pre-assigned text delimiter may be included in the matches so that they will conflict ( the result is that it is easily to extract each match. An array would have no problem with it).
That is why I suggested user-defined text delimiter above.
Even with those apps/languages that use a "g" (or equivalent) modifier, it usually still requires additional code to loop through all of the found matches.
For example, in JavaScript:
var sourceStr = `
ABCD-123abc
Some text ABCD-abc234 some other text
ABCD-76y65yj90
ABCD-76yABC90 some text ABCD-code6547AA
`
var regEx = /(ABCD\-[^\s]+)/g;
var captureList = [];
var matchResults;
while (matchResults = regEx.exec(sourceStr)) {
captureList.push(matchResults[1]);
}
(I just started learning programming languages a few months ago by myself. I just take the codes from wherever I can find and edit it to suit my needs, often not knowing how they work.)
<script>
var sourceStr = `
ABCD-123abc
Some text ABCD-abc234 some other text
ABCD-76y65yj90
ABCD-76yABC90 some text ABCD-code6547AA
`
var regEx = /(ABCD\-[^\s]+)/g;
var captureList = [];
var matchResults;
while (matchResults = regEx.exec(sourceStr)) {
captureList.push(matchResults[1]);
}
alert(captureList);
</script>
The result is the same as (without the loop):
<script>
var str=`ABCD-123abc
Some text ABCD-abc234 some other text
ABCD-76y65yj90
ABCD-76yABC90 some text ABCD-code6547AA`;
var match=str.match(/(ABCD\-[^\s]+)/g);
alert(match);
</script>
Nothing wrong with using examples to help learn a language.
However, IMO, it could be very dangerous to use a code snippet without understanding it.
While it may work in one specific use case, it could fail in others.
There is a big difference between match results, and capture group results, If you don't understand that, I encourage you to study and test until you do.
Also, JavaScript has a number of different methods to use RegEx, each working somewhat differently and sometimes returning different results. Again, study and testing is needed to understand.
Thanks for your caution and advice.
It's been crazy in the past months. I've learned HTML, JS, PHP, AS, Python. RegEx is another great thing I have learned, literally from knowing nothing to knowing enough to serve most of my needs. Database is another monster. I've only tasted a little bit, but have not been putting it into real use in my own coding.
I mostly take examples from online tutorials, such as those at w3schools.com. I guess these should be relatively safe to use and adapt. I know there is potential danger for using others' codes without understanding them. But in most of the cases, it was not that I did not want to understand, but that even after reading the tutorials, I still couldn't understand! One of the reasons I learned so many different languages in the past months was because I could neither understand nor use the language I was learning, but found an example in another language I could use and understand the syntax well enough to adapt it.
I saw on the web you provide saying:
Regular expressions are used with the RegExp methods test() and exec() and with the String methods match() , replace() , search() , and split() .
So I have been using the String methods. The RegExp methods seems to be a bit more complicated than the String methods. I can understand the String methods much better.
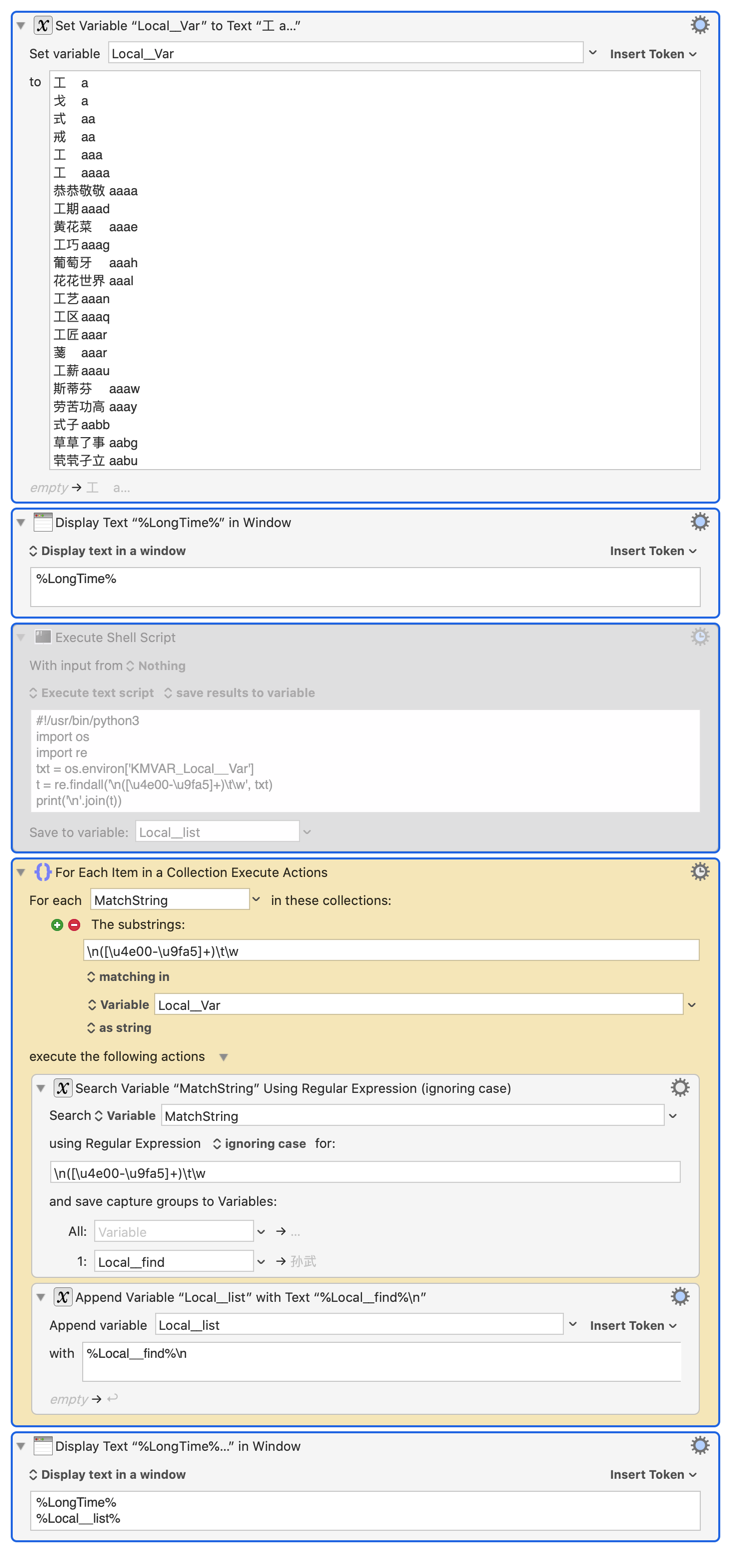
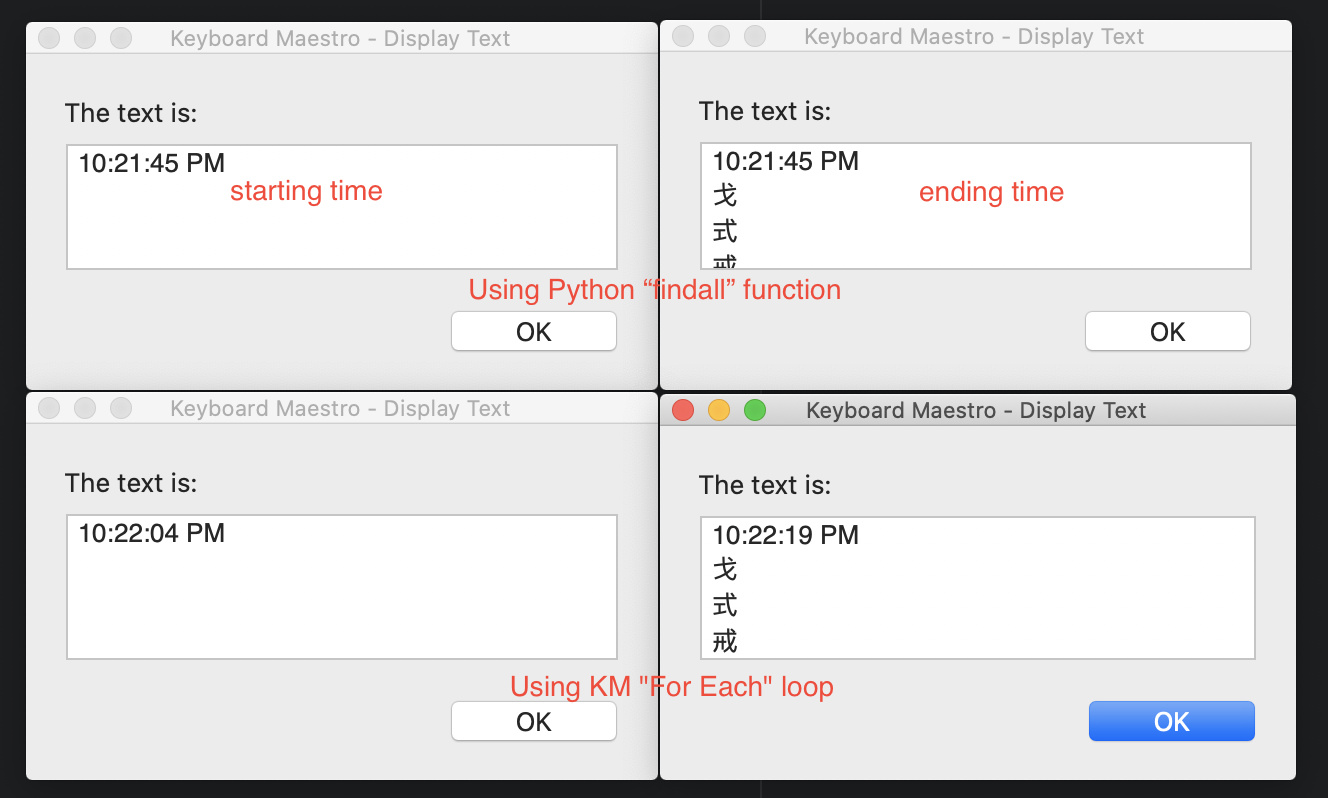
To illustrate the time difference it can make, I have made a macro, one with Python "findall" function, the other with the "For Each" loop currently KM provides.
I don't know how to display time with smaller than 1s unit. I just use the %Longtime% token. The difference is evident. My variable has 5,000 lines (each line has only 1-4 chinese characters followed by a Tab, then 1-4 English letters.
In this example, I could simply use RegEx, replacing \t\w+ with nothing. But this is irrelevant to my point. My original variable has other text elements. Therefore, this RegEx search is the best solution for me. Also, my original variable has more than 80,000 lines. Due to the limit of the environment variable size, I reduced it to 5,000 lines. It would take the "For Each" loop more than 1 min to complete the 80,000 lines task!
We have always said to use the tool that works best for you.
There are many cases where a script (AppleScript, JXA, JavaScript, Python, Ruby, etc) will run faster than KM.
OTOH, KM is much easier to use for those that have little or no programming experience.
I know there are other solutions that might be better than the native KM actions. But in this post, I'm requesting a feature of "global" modifier for RegEx search that functions similarly to that in other programming languages, so that we don't need to use the "For Each" action to get similar results.
I think this is a reasonable request. That is why I posted it. But I'm ok if @peternlewis says "no" to it. I'm grateful for what KM already provides.
But I don't understand how a global regex search that returns multiple answers can work if you don't want to iterate through the answers to process each of them…?
In the example macro I uploaded above, I just need to get the Chinese characters.
In this particular case, I could have used a search and replace to delete all English letters and the Tabs. But as I said above, the original file has other Chinese characters and signs that I do not want to include. I only want to get the Chinese characters that are followed by a Tab + some English letters.
What does that mean? What are you going to do with the multiple search results if you don't want to use a For Each action to process them?
But I don't understand how a global regex search that returns multiple answers can work if you don't want to iterate through the answers to process each of them…?
I don't need to process each line individually. I need to use the found result as a string for further actions. In this case, I need to do a regex search in this string. I need to test if my selected characters exist in this string or not.
If I do a match iteratively line by line (more than 80,000 lines), it is much slower. But if I do a regex search in a string (a string with 80,000 lines), it is instant. Therefore, I need the result to become a string.
That is why in my python example, I have found all matches that are saved as a list, I still need to make the list into a string.
t = re.findall('\n([\u4e00-\u9fa5]+)\t\w', txt)
print('\n'.join(t))
This 80,000 line file is an extreme example. I only needed to do it once. I have saved the result into a named clipboard. But I do have another similar file. It has 600 lines now. This file will change. I need to do a RegEx search in this file every time, combine these two into a string. Then see if this string contains my selection. If it does, do something, if it does not, process my selection and append it to the now 600-line file. I need to do it quite often. It has grown from 0 lines to 600 lines.
To use the "For Each" action, I will just need to iteratively append each match + a linebreak to a variable. The result is the same as print('\n'.join(t)) in Python, using linebreak as the text delimiter.
In this case, I could use other text delimiters. But I imagine in some other cases, other text delimiters might be needed.
Take another case for example:
In this case, if two lines contain the same code, and all matches are needed. And we simply need to get all the matches joined by, say, 2 linebreaks (or whatever text delimiters). Now, we will need the "For Each" action to append the matches + user-defined-text-delimiter.
But, besides the much more time needed with the "For Each" action (if the original file is large, the difference becomes noticeable) an extra text delimiter will always be appended at the end of the result:
"match1"
text delimiter
"match2"
text delimiter
"match3"
text delimiter
What we want is probably
"match1"
text delimiter
"match2"
text delimiter
"match3"
Actually, I came up with this feature request when I was helping with this case. I suggested the "For Each" solution to the OP. But it got me thinking why a (?g) modifier is not supported.
For myself, I've already been using the Python code I mentioned above and I am satisfied with the instant speed (but I would love to see a native KM action available).
I don't know of any language that lets you do a find all and just returns the result as all the matches run together with some sort of joining string. Your Python example is functionally equivalent to a For Each action in Keyboard Maestro - it returns the array, which it processes with join. Keyboard Maestro has no arrays, so you process arrays using For Each.
To implement this would require a whole new action, to search using a regular expression, finding all matches, and providing a delimiter (and optionally whether the delimiter should be included at the end or not). I can't see that there is enough demand for this action to be worth the added complexity. I imagine a Plug In action could be created to do it relatively easily, and that seems like a better solution unless there are really myriad of other cases where this could be helpful in solving real world problems, but it seems to me like most cases it could be done with the Search and Replace action.
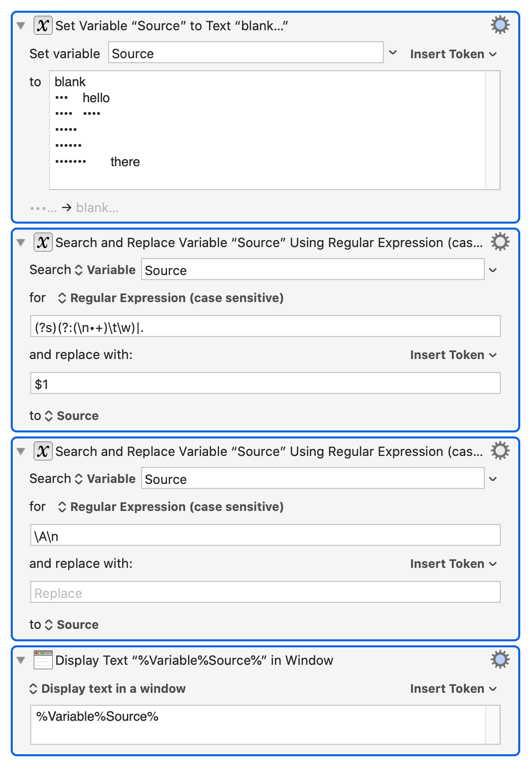
BTW, I think you can accomplish your task of extracting the Chinese characters with something like this:
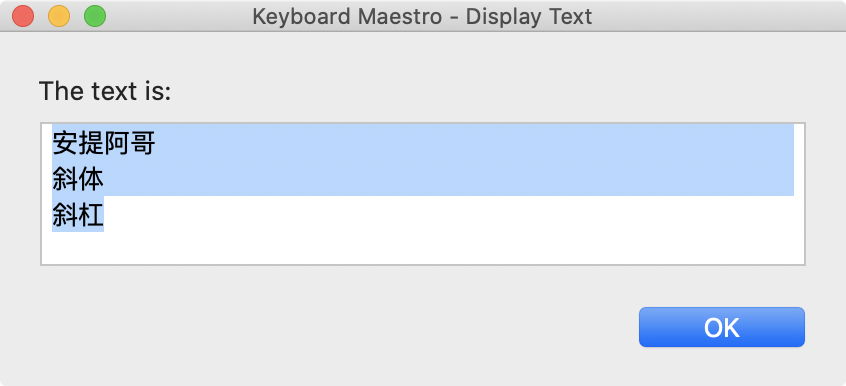
It worked in my test (I used bullets instead of Chinese characters just because it's easier for me to test, but replacing • to get:
@peternlewis, thanks a lot for your explanation and example.
Your Python example is functionally equivalent to a For Eachaction in Keyboard Maestro - it returns the array, which it processes with join . Keyboard Maestro has no arrays, so you process arrays using For Each .
Yes. I understand the lack of array poses a challenge. I was wondering if there could be a brief code like the Python code run in the background, to get
(1) the source string
(2 )the RegEx pattern and (3) if (?g) is detected, add an input box (just like those for the capture groups when a parenthesis is detected) for users to input a text delimiter.
Once the three variables are passed, run this code to process them, and pass it to a KM variable.
I guess a Plug In would function like this?
I don't know how Python processes the function. But the difference of time used is noticeable (less than 1s vs. 15s for a 5,000 line string).
Your example is very helpful!!! I still don't fully understand the search pattern, but it did get my desired results.
I used the (?:(\n[\u4e00-\u9fa5]+)\t\w)|. pattern and without the replacing \A\n with nothing action, and still get the same result.
There are many more lines following it, but all having the same pattern with the last three lines. I need to get the Chinese characters in these lines, like this:
安提阿哥
斜体
斜杠
Can you explain:
what is |. doing?
why using (?s) and why not using it does not change the result? (I know ?s is to include '\n' in . I just don't understand why did you include it)
why using \A\n and why not using it does not change the result?
This opens a new door to my RegEx journal. I would never come up with this by myself.
Thanks a lot.
The expression is searching for either what you want or any character - if it finds what you want, it replaces it with just the capture bracket. Otherwise, it matches any character (and with the (?s), that includes the newline character), and replaces it with the capture bracket which is empty since that part did not match.
Otherwise it will not match line endings, and so blank lines will be included in the output.
Because as written it includes the newline before the match with each search, resulting in one extra newline at the start of the result, which then needs to be removed. The same as the issue you mentioned previously where the difference between the newlines as delimiters, or the newlines after each entry, resulting in an additional newline, except in how I have done it, it is at the start instead of the end.
Thanks @JMichaelTX for working on the Wiki. I happened to know about g but wondered recently if that’s what I had to do. The edit would’ve saved me time. So I’m sure it will save others time.
Looks like the (Capture group)|. pattern can somewhat function as the g modifier without any text delimiter. If the \n happens to be in it, it can function as a text delimiter, as in my case.
To implement this would require a whole new action, to search using a regular expression, finding all matches, and providing a delimiter (and optionally whether the delimiter should be included at the end or not). I can't see that there is enough demand for this action to be worth the added complexity.
I would not ask you to make a whole new action.
It would still be good though, to still have the g modifier available. Perhaps you can make the text delimiter preset, unique enough, such as \n###\n (If this is not too much trouble to add)? (a single linebreak is not a good option, because the match string may contain linebreaks).
It will look like:
match1
[linebreak]
###
[linkebreak]
match2
Users then can replace this \n###\n with whatever else text delimiter they want in the next action.
I know this can be accomplished with the "For Each" action. But as I have shown above, for a large file the "For Each" action takes much longer time. And it takes more steps to set up the actions.
This function is good for anyone who only wants to get all the matches, for display, log, or whatever other further processes (in my case above, I would simply need to replace \n###\n with \n). I generally try to avoid "For Each" action if possible.
why using (?s) and why not using it does not change the result? (I know ?s is to include '\n' in . I just don't understand why did you include it)
Otherwise it will not match line endings, and so blank lines will be included in the output.
why using \A\n and why not using it does not change the result?
[/quote]
Because as written it includes the newline before the match with each search, resulting in one extra newline at the start of the result, which then needs to be removed. The same as the issue you mentioned previously where the difference between the newlines as delimiters, or the newlines after each entry, resulting in an additional newline, except in how I have done it, it is at the start instead of the end.
In my macro, without the (?s), no blank lines are included in the output variable. Therefore, I don't need the \A\n replacement action as well. Even after appending linebreaks both before and after. They are still gone. Any idea why?