Hey guys!
Hopefully someone could help me with this. I can't figure it out.
I just want filter the SECTIONS of a document out, which begin with a specific word or symbol.
E.G., the text is:
"Hello world!
Hi!
Lalala.
Hello everyone.
Still here?"
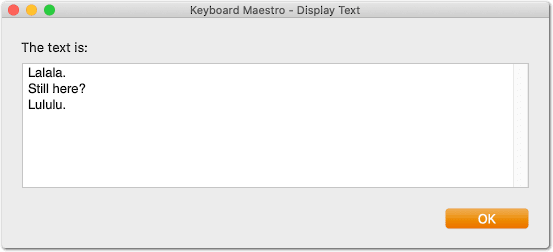
Than the output should be:
"Hello world!
Hi! Hello everyone."
[the line "hi" should be there too, because there is no empty line / break between "hello world" and "hi" in the Text-Input]
AND
The Source-Input-Text should change to:
"Lalala.
Still here?"
[so the result should be cut out]
I'm not sure if this is so easy, but I guess it should be possible with Keyboard Maestro, or isn't it?
I'm thankful for all suggestions!
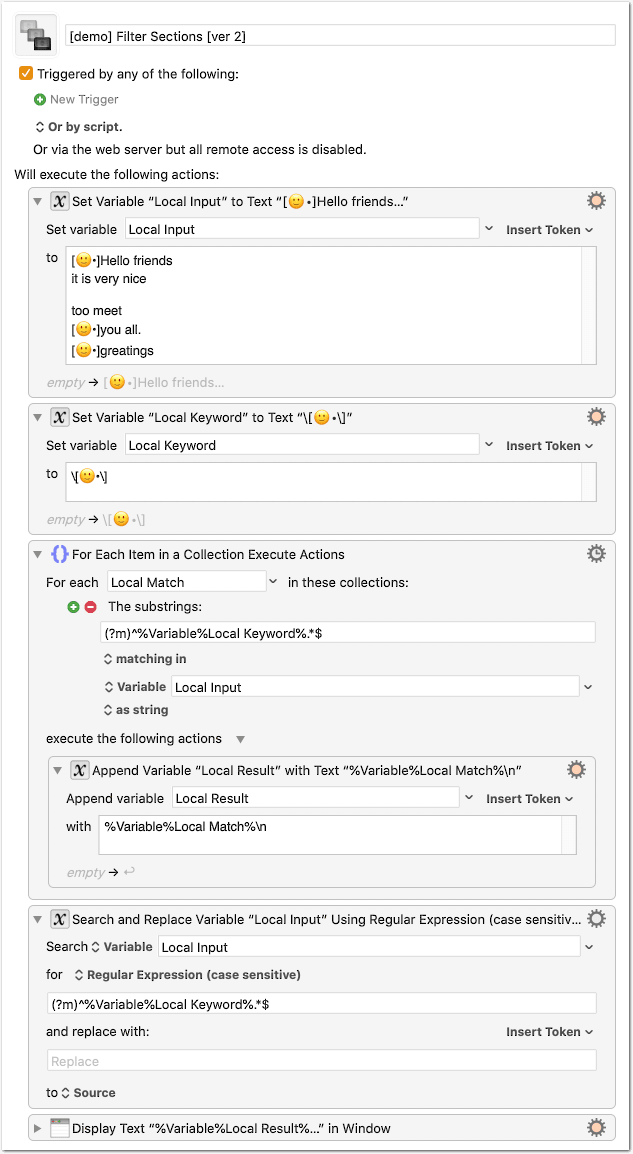
You see the input sample text in the first action (Set Variable).
According to your example I took 🙂Hello as the keyword.
In the sample text I have added a third type of section with 3 consecutive lines. It is treated like your example with 2 consecutive lines, that is all consecutive lines are matched. If you want to exclude the third line in such cases, you have to adapt the regex.
Tom this is exactly was I needed! Thank you so much! I have no idea, how this works, but I guess, I have to learn regex, right? Thanks again for answering so fast!
In the Help menu of KM you find a link to ICU Regular Expression Reference. Not a tutorial but all the elements used in the above regexen are explained there.
Learning: Search the forum for “learning regex” and you’ll find plenty of tips. My personal favorite is Regular Expressions Info. Very comprehensive and very good (and easy to read) explanations.
For testing out your regexen and having fun playing around with them go to regex101.
Sorry, I tried a lot, but sometimes it works, sometimes it does not, I have no idea why. So maybe this is too complex right now for me. So here is - hopefully - an easier question:
Can you help me cut out just the lines, that begin with [•]
The blank lines are not so important. And can it work for an large amount of lines?
E.G.
INPUT
[•]Hello friends
it is very nice
too meet
[•]you all.
[•]greatings
OUTPUT
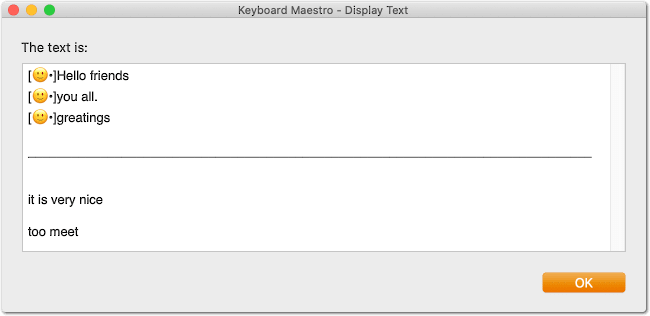
[•]Hello friends
[•]you all.
[•]greatings
it is very nice
too meet
P.S.: This is the macro I made out of your advice, but it doesn't really work.
What exactly does not work? And which macro? My macro from above, or are you referring to the macro in your PS?
I’ll get back to you later this afternoon for your new input text.
For the moment: Please check your text example in the forum post. There is a horizontal rule between “[•]greatings” and “it is very nice”. Is this intended?
(It seems you are not aware that the forum interprets Markdown-formatted text, so you might have produced that line unintentionally. Asking this because without knowing the exactly desired output I cannot write a correct macro.
See here for forum formatting. Besides that, most of the more common Markdown syntax is working.)
Thanks for your answer.
Both macros do not work properly, but maybe I do not really understand how they work. Tried to figure out the regex for hours yesterday, but I try it again now. The problem is, that not all lines are proceeded correctly. So they are missing in the output.
The horizontal rule is intended by the way, but it does not matter at all and when it has a special meaning I just could be another break. I just used it, to differentiate between the 2 different outputs, that's all. I just typed _ many types.
P.S.: This is my interpretation of your regex, but somehow I don't get it.
(?s)INPUT.*?\R(?=\R)
(?s) = activate dot matches new line
INPUT = The starting-String I want to match
. = get whole line
* = with 0 or more symbols
? = don't have to be anything
\R = than get a New Line
(?=\R) = I don't get this one
(?s)(\R)*INPUT.*?\R{2,}
(?s) = activate dot matches new line
\R = than get a New Line and group it for $2 ???
* = get 0 or more lines
INPUT = but only with starting-String after them
. = get whole line
* = with 0 or more symbols
? = don't have to be anything
\R = than get a New Line
{2,} = at least 2 or more ???
No. The dot matches any character. (See ICU Reference.) In this case – since we have set the s flag – also a newline character.
* = with 0 or more symbols
Yes, matches 0 or more times.
? = don't have to be anything
No. Matches zero or one times (see ICU Reference). Also has other functions, for example in (?s) it marks a flag, or in combination with =, <, ! it marks an assertion (see below).
\R = than get a New Line
Yes, matches most types of newline characters.
(?=\R) = I don't get this one
A positive look-ahead assertion. (See ICU Reference; or here on Regular Expressions Info.)
(?s)(\R)INPUT.?\R{2,}
(?s) = activate dot matches new line
Yes.
\R = than get a New Line and group it for $2 ???
You probably mean (\R)*: Zero or more newlines and capture it. Is then re-inserted with $1 in the replacement.
* = get 0 or more lines
Matches 0 or more times (see above).
INPUT = but only with starting-String after them
Yes, kind of. It is for getting these empty lines before a new keyword and replace them with exactly one newline (as you have requested in your desired output example).
. = get whole line
No. See above.
* = with 0 or more symbols
Yes, matches 0 or more times.
? = don't have to be anything
See above.
\R = than get a New Line
See above.
{2,} = at least 2 or more ???
Yes.
Ah, OK. I didn’t know if it should be part of the output or not.
When posting example/sample text it is often good to format it either as code block (as you have done above with your regex notes), or as blockquote, depending on the kind of text. This way it is clear if something belongs to the literal text.
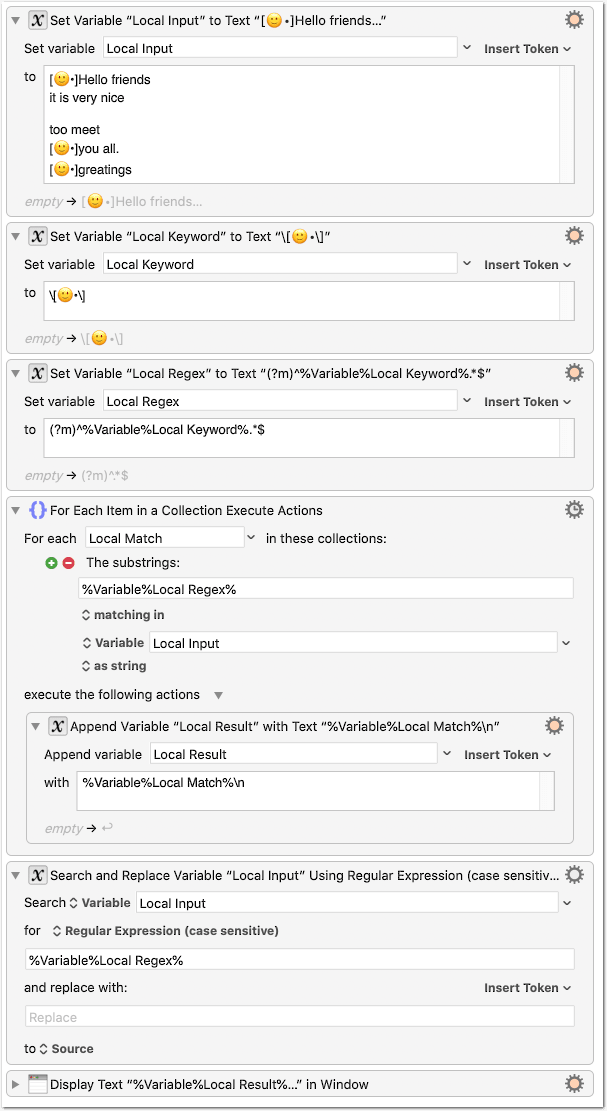
So, if I understood correctly, you want to separate the input tex – similarly as before – into…
(For easier testing I have replaced your Clipboard action with a simple variable declaration. It will also work via Clipboard --> input text variable.)
The m flag makes ^ and $ match begin/end of lines, as opposed to begin/end of text. Makes sense here because the things you want to match are all one-liners, which was not the case in your first example.
[ and ] are meta characters for describing character classes. So, since we want them as literals here, we have to escape them. (Unless it was intended to use 🙂 and • as class.)
The \n in the Append Variable action simply adds a line feed after each matched line. We could also match up to the existing line break with an additional \R in the regex, as in the first macro, but this way it simplifies the regex.
Strictly, the \R solution would be more correct, because it should give you the same type of line break in the output as in the input (LF, CR or CRLF).
Macro-technical stuff
Somehow the macro I downloaded from your post seems to be damaged. I get Danger icons on almost every action for no apparent reason, for example:
Do you see the same with your original macro, or is the upload or something with my KM corrupted?
When a variable starts with “local” or “Local” it is a local variable, as opposed to a global one.
That means also, it is not stored persistently by KM, so usually no need to delete it at the end of a macro. (This was necessary before KM8, where only global/persistent variables existed.)
You should use local variables, unless it is necessary to store the value or to make it available to other macros or scripts.
In this case, since we use two times the same regex, you could also pack the whole regex into a variable, so you have to change it only at one place:
Thank you so much for your very detailed work and help!
It really helps a lot on many levels! I will test all the macros after work today! Looking forward to it!
 Hello world!
Hello world!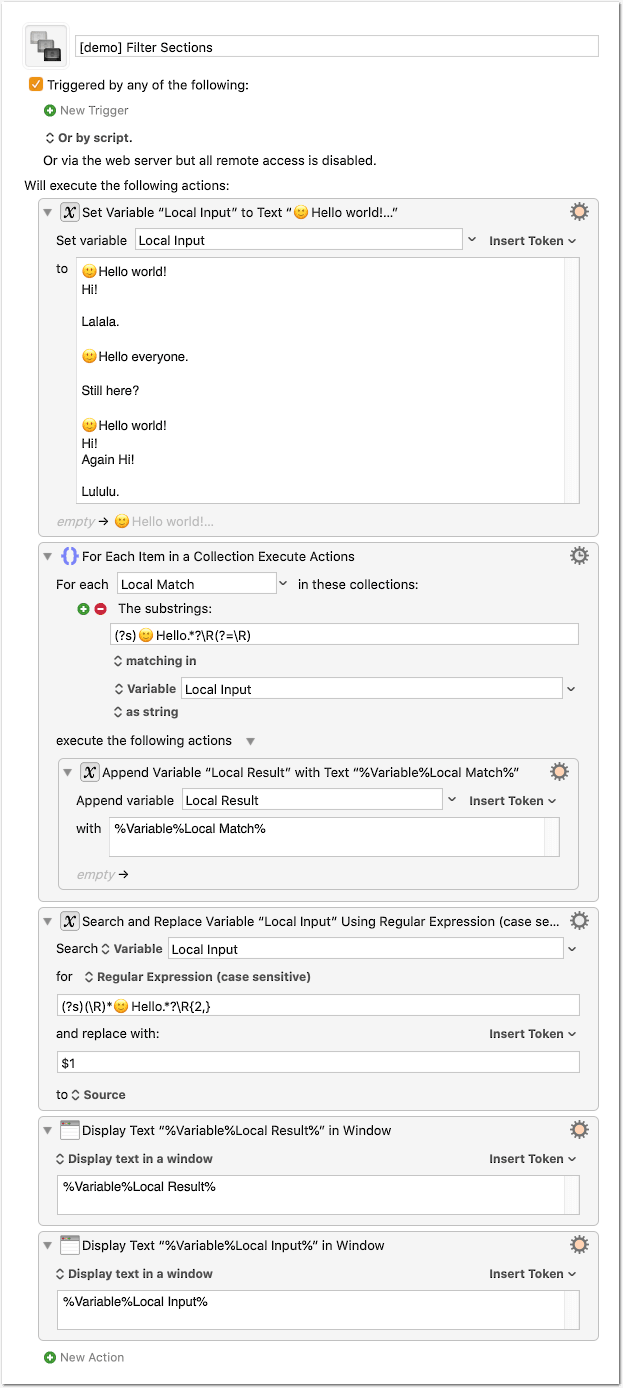

 Filter Sections Sicherheitskopie.kmmacros|attachment
Filter Sections Sicherheitskopie.kmmacros|attachment