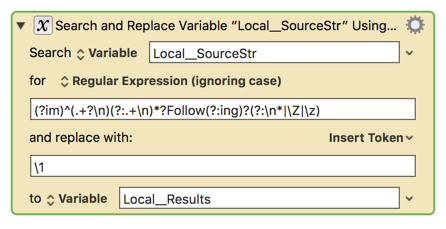
I made a mistake in my original post, I need to check for Follow and Following, also. How would that change the pattern? I came to edit once I got home but you were too quick! Thank you!
I haven’t yet (still away from my Mac) but the full text contains both “Follow” and “Following” and I thought that would change the required RegEx. I meant to include both in the sample but made an error.
There are many ways of doing this, and tastes vary about the balance between concision and maintainability.
If your source text consists of groups of three lines, delimited by a blank line, then another approach would be to reach for an Execute JavaScript action, and write a function which gathers the first line of each group:
// firstLinesOfGroups :: String -> [String]
const firstLinesOfGroups = strLines =>
// Groups of N lines,
strLines.split('\n\n')
// Mapped to a list
// which holds just the first line of each group.
.map(x => x.split('\n')[0]);
The action could then return a value with a final JS line like:
return firstLinesOfGroups(str).join('\n');
(Where str is your input text)
(Away from macOS at the moment, with only an iOS device, so this code was tested in the JSContext of iOS 1Writer)
All right! I've sat down to test it and this works great! Thank you! I have one minor request though:
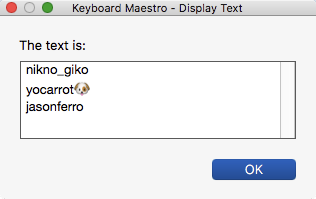
It turns out I was not thorough enough with checking my source. There are instances where there are only two lines, not three (where someone did not enter a "real name.") With this modified source data, how would I accomplish the same end result?
nikno_giko
🄺🄸🄲🄷
Follow
yocarrot🐶
Follow
jasonferro
🦊Jason F아리
Following
As I just discovered some of the text is only two lines. Would this JS approach still work?
Thank you all!
P.S.: MAN that regex101 link is COOL. What an awesome teaching tool.
It will work (without modification) with line groups of any length, but if the missing names take the form of blank lines, then it will overproduce – treating any group with a blank line in the middle as two groups.
I know you know better than to post incomplete examples, but for everyone's benefit: Please make sure you provide a real-world, complete example of all use cases in your original post asking for help.
I know, I'm ashamed I rushed to the forums too quickly. I didn't know you didn't have to put a name and could wind up with only two lines! This one works perfectly, thank you very much.
Let's see if I can add anything to this little conundrum...
Trudging on the RegEx Treadmill
With this sort of text parsing problem if I don't have confidence in the input format I usually make at least two passes.
First pass:
Strip leading and trailing vertical whitespace. Removing cruft often makes data extraction much easier.
\A\s+|\s+\Z
Second pass:
(?is)\v*(\S.+?\n).*?follow(?:ing)?
If I wanted to make just one pass in this task I'd probably do something like this:
(?is)\v*(\S.+?\n).*?follow(?:ing)?\s*
Or maybe this:
(?si)\v*(\S.+?\n).+?(\n{2,}|\z)
I would prefer to use \w (word-character) instead of \S (non-space-character), but the blinking username might start with an emoji or something else.
Perl's motto TIMTOWTDI is more than a little true for regular expressions as well.
(Pronounced Tim Toady – “There's More Than One Way To Do It.”)
First attempts to construct patterns tend to be clunky and ugly – then after beating your head against the wall for hours and/or taking a break (or sleeping on it) you may get that “I could have had a V8!” moment and find a simpler and more elegant approach.
The AppleScript Avenger
If this task's data structure is completely predictable then plain vanilla AppleScript can do the job easily.
Method 01 – The “hard” way:
----------------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2018/03/30 01:34
# dMod: 2018/03/30 03:13
# Appl: Vanilla AppleScript
# Task: Extract the first line of each paragraph of the given text.
# Libs: None
# Osax: None
# Tags: @Applescript, @Script, @Extract, @First, @Line, @Paragraph, @Text, @Parse
----------------------------------------------------------------
set dataStr to "nikno_giko
🄺🄸🄲🄷
Follow
yocarrot🐶
Follow
jasonferro
🦊Jason F아리
Following
"
set printIt to 1
set dataStr to paragraphs of dataStr
repeat with theLine in dataStr
if contents of theLine ≠ "" then
if printIt = 1 then
set printIt to 0
else
set contents of theLine to 0
end if
else
set printIt to 1
set contents of theLine to 0
end if
end repeat
set AppleScript's text item delimiters to linefeed
set dataStr to (text of dataStr) as text
----------------------------------------------------------------
Method one will tolerate uneven spacing between text-blocks – as long as there are at least two linefeeds between them. It will also tolerate leading and trailing vertical whitespace.
Method 02 – Easier and faster using TIDS:
(This method is less robust, because it is more dependent upon consistency of the input data structure, but AppleScript's text item delimiters are powerful and very fast when used appropriately.)
----------------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2018/03/30 01:34
# dMod: 2018/03/30 01:43
# Appl: Vanilla AppleScript
# Task: Extract the first line of each paragraph of the given text.
# Libs: None
# Osax: None
# Tags: @ccstone, @Applescript, @Script, @Extract, @First, @Line, @Paragraph, @Text, @Parse
----------------------------------------------------------------
set dataStr to "nikno_giko
🄺🄸🄲🄷
Follow
yocarrot🐶
Follow
jasonferro
🦊Jason F아리
Following
"
set AppleScript's text item delimiters to linefeed & linefeed
set dataList to text items of dataStr
repeat with listItem in dataList
set contents of listItem to paragraph 1 of listItem
end repeat
set AppleScript's text item delimiters to linefeed
set newDataStr to dataList as text
----------------------------------------------------------------
As a footnote to this set of jazz variations, for my own purposes I find that a fast and maintainable way of light scripting is to use a set of c. 300 generic functions, in both JavaScript and AppleScript.
If I needed this snippet myself, I might, (assuming a header for the function inclusions, or a macro which brings in only the generic functions used) have written something like:
Javascript
return unlines(
map(
x => head(lines(x)),
splitOn('\n\n', strInput)
)
);
Applescript
script firstLine
on |λ|(x)
head(lines(x))
end
end script
return unlines(map(firstLine, splitOn("\n\n", strInput)))
It really is incredible to see the three of y’all come up with so many ways to accomplish a task. It’s one of my favorite things about this forum. Thank you for all the examples.
Chris, I have no doubt that you can. I was hoping that you'd join in here. I always learn something from your posts.
Yep, mine too.
I really like having a lot of tools in my tool kit. It allows me to pick the best tool I know how to use, given the time constraints. I like and use both scripting and RegEx, while continuing to learn both, and of course, KM.
There is no doubt that this is the best forum I've ever belonged to, and there have been many over the decades.
But I have to say, that given the use case, my favorite solution here is:
Most Keyboard Maestro users don’t know that it can search and replace from AppleScript, so here’s an example using the current task.
NOTE – Remember to try AppleScripts in the Script Editor.app before fooling with the Execute an AppleScript action in Keyboard Maestro.
Anyone who uses AppleScript should be at least generally familiar with the SE (or Script Debugger), because it provides more feedback when running scripts than Keyboard Maestro can.
----------------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2018/03/30 20:29
# dMod: 2018/03/30 20:34
# Appl: Keyboard Maestro, Keyboard Maestro Engine
# Task: Use Keyboard Maestro's RegEx Search & Replace directly with AppleScript
# Libs: None
# Osax: None
# Tags: @Applescript, @Script, @Keyboard_Maestro_Engine, @RegEx, @Search, @Replace
----------------------------------------------------------------
set dataStr to "
nikno_giko
🄺🄸🄲🄷
Follow
yocarrot🐶
Follow
jasonferro
🦊Jason F아리
Following
"
tell application "Keyboard Maestro Engine"
set foundItemList to search dataStr for "(?is)\\v*(\\S.+?\\n).*?follow(?:ing)?\\s*" replace "$1" with regex
end tell
----------------------------------------------------------------
Here’s a single-pass method of doing the job with AppleScript and the Satimage.osax (AppleScript Extension).
----------------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2018/03/30 20:20
# dMod: 2018/03/30 20:26
# Appl: Satimage.osax, AppleScript
# Task: Using the Satimage.osax and RegEx to extract user-names from structured data.
# Libs: None
# Osax: Satimage.osax --> http://tinyurl.com/satimage-osaxen
# Tags: @Applescript, @Script, @Satimage.osax, @RegEx, @Extract, @User-Names, @Names, @Structured, @Data
----------------------------------------------------------------
# REQUIRES the Satimage.osax to be installed for RegEx support.
----------------------------------------------------------------
set dataStr to "
nikno_giko
🄺🄸🄲🄷
Follow
yocarrot🐶
Follow
jasonferro
🦊Jason F아리
Following
"
try
set foundItemsList to find text "(?im)[\\n\\r]*(\\S.+?)\\n.*?follow(?:ing)?" in dataStr using "\\1" with regexp, all occurrences and string result
on error
set foundItemsList to "false"
end try
if foundItemsList ≠ false then
set foundItemsList to join foundItemsList using linefeed
end if
----------------------------------------------------------------
Here’s the sort of method I’d use when I was a beginner with regular expressions. (Again using the Satimage.osax.)
----------------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2018/03/30 20:49
# dMod: 2018/03/30 21:05
# Appl: Satimage.osax, AppleScript
# Task: Using the Satimage.osax and RegEx to extract user-names from structured data.
# Libs: None
# Osax: Satimage.osax --> http://tinyurl.com/satimage-osaxen
# Tags: @Applescript, @Script, @Satimage.osax, @RegEx, @Extract, @User-Names, @Names, @Structured, @Data
----------------------------------------------------------------
# REQUIRES the Satimage.osax to be installed for RegEx support.
----------------------------------------------------------------
set dataStr to "
nikno_giko
🄺🄸🄲🄷
Follow
yocarrot🐶
Follow
jasonferro
🦊Jason F아리
Following
"
# Strip Vertical Whitespace from top and bottom of data.
set dataStr to change "\\A\\s+|\\s+\\Z" into "" in dataStr with regexp without case sensitive
# Normalize space between data records.
set dataStr to change "^(follow(?:ing)?)$\\s*" into "\\1\\n\\n" in dataStr with regexp without case sensitive
# Add two linefeed before the first data record for consistency.
set dataStr to linefeed & linefeed & dataStr
# Find the first line of each data record (preceded by two linefeeds).
set foundItemsList to find text "\\n{2}(\\S.+)" in dataStr using "\\1" with regexp, all occurrences and string result
set foundItemsList to join foundItemsList using linefeed
I’ve got three steps in there to prepare the data for easier parsing, and this makes the final pattern really simple.
Despite having more steps the script still runs in approximately 0.001 seconds on my system.
So this method can be much more efficient than spending 30 minutes (or hours) finding just the right one-pass pattern.