One quick sketch:
(UPDATED for punctuation and a fuller Unicode block)
(UPDATED again to converge case variants, and avoid word1/word2 conflations).
(FURTHER UPDATED (in failed attempt ![]() to improve Portuguese sort order)
to improve Portuguese sort order)
(FINAL update – better Portuguese sort order, I think)
(and subsequently delegated segmentation to Intl.Segmenter)
Words with Latinate diacritics.kmmacros (4.5 KB)
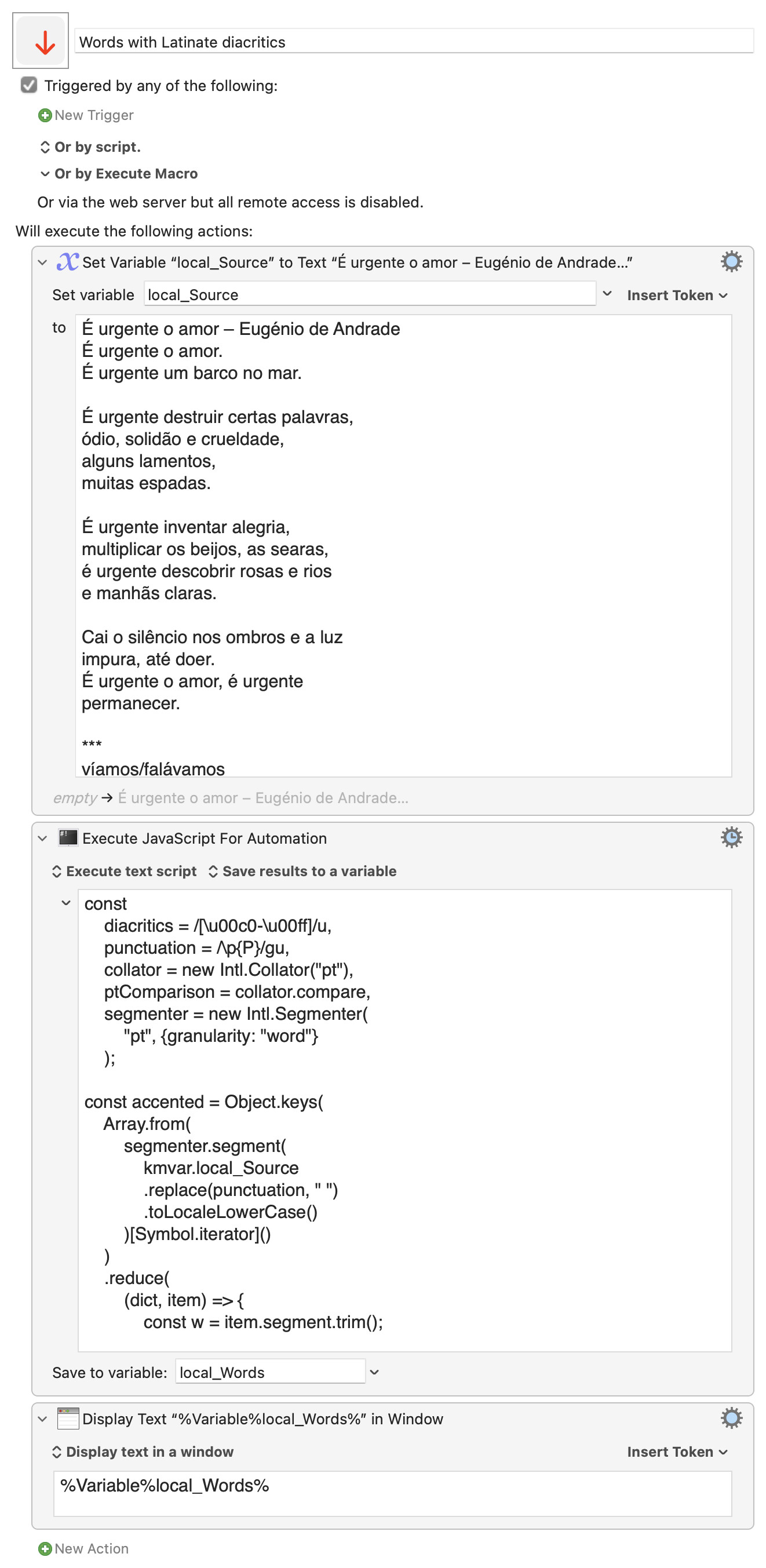

Expand disclosure triangle to view JS source
const
diacritics = /[\u00c0-\u00ff]/u,
punctuation = /\p{P}/gu,
collator = new Intl.Collator("pt"),
ptComparison = collator.compare,
segmenter = new Intl.Segmenter(
"pt", {granularity: "word"}
);
const accented = Object.keys(
Array.from(
segmenter.segment(
kmvar.local_Source
.replace(punctuation, " ")
.toLocaleLowerCase()
)[Symbol.iterator]()
)
.reduce(
(dict, item) => {
const w = item.segment.trim();
return !(w in dict) && diacritics.test(w)
? Object.assign(
dict, {
[w]: 1
}
)
: dict;
},
{}
)
);
return accented
.sort(ptComparison)
.join("\n");