In my language (Portuguese) there are a lot of special "characters" (maybe they are called accents?) such as é, ã, etc...
Since my computer is all in English, because that's how I communicate 99.9% to the time, all my notes are in English, etc, it's very rare that I type in Portuguese.
Once in a while I save some words in the Text Replacement pane.
Today I had to write a looooong letter in Portuguese and since I'm already replacing some of the words with the accented words (for example when I wanted to type "healthy" in Portuguese, I typed "saudavel", but the real word is "saudável"). So since all words are now fixed, I would like to create a macro that searches all words that are not accented and delete them so I can have a list of all accented words. Then I can go and start adding those to the Text Replacement pane.
Is there a RegEx formula that includes all accents or do I have to manually type each option and then find a way to compare each word in the letter with each accented character?
Also, how would I be able to find duplicates? I know that I use some words a lot and I would like to just keep one of those words instead of 30 versions on the same word in the list.
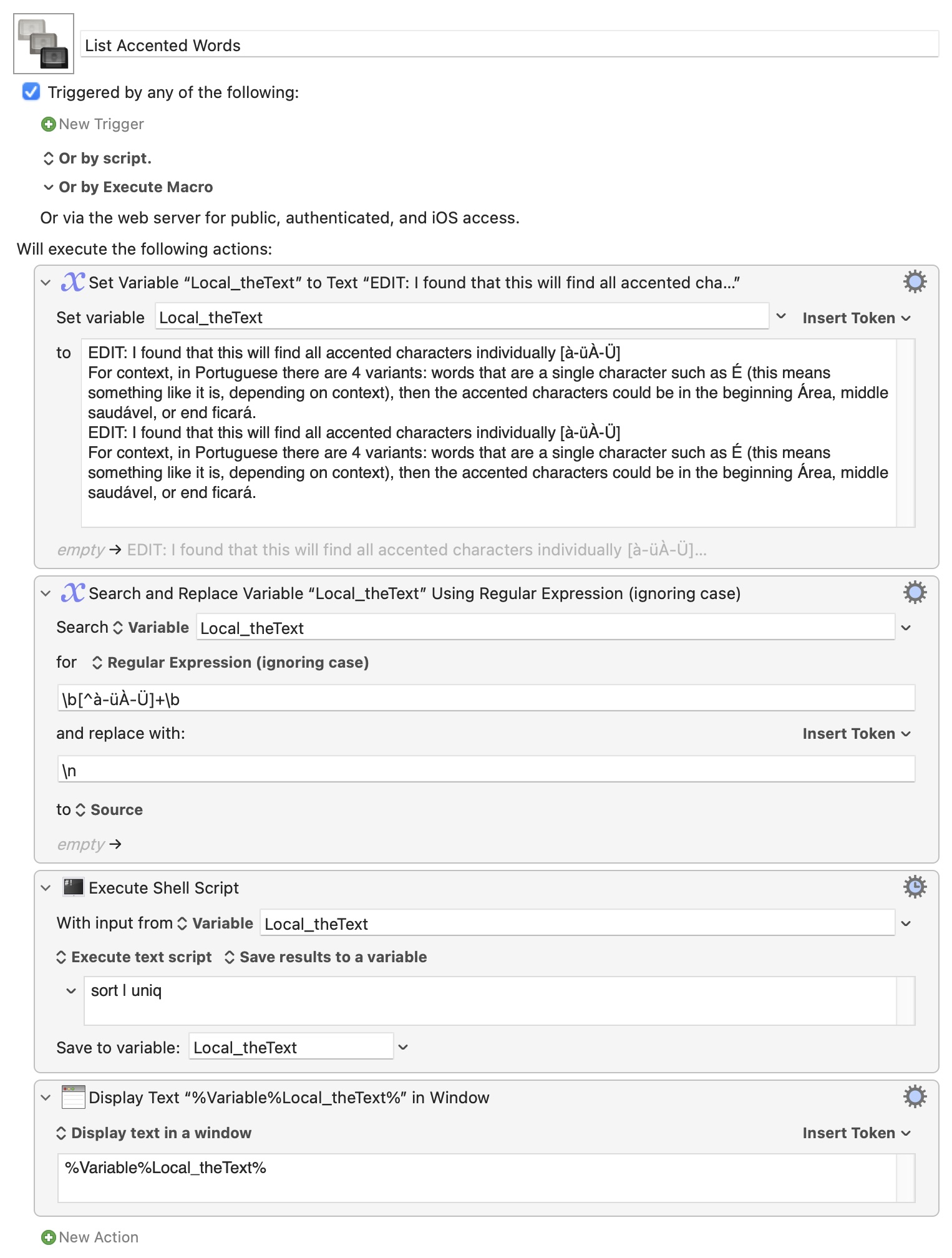
EDIT: I found that this will find all accented characters individually [à-üÀ-Ü]
For context, in Portuguese there are 4 variants: words that are a single character such as É (this means something like it is, depending on context), then the accented characters could be in the beginning Área, middle saudável, or end ficará.
So I need to find a way to include all 4 options. I understand the concept, kinda, but I can't find the way to achieve it in RegEx
The trick is that you want to find all words that contain accented characters -- or, conversely, delete every word that doesn't -- so you'll need to include "word boundary" metacharacters in your pattern. \b matches a "word boundary", while \B matches any character that isn't a word boundary.
If going the deletion route you'll need to replace non-accented words with something so everything doesn't run together -- a new line seems a reasonable choice:
"Replace any word that doesn't contain at least one of the listed accented characters with a new-line."
When run on your text
EDIT: I found that this will find all accented characters individually [à-üÀ-Ü]
For context, in Portuguese there are 4 variants: words that are a single character such as É (this means something like it is , depending on context), then the accented characters could be in the beginning Área , middle saudável , or end ficará .
...that will return
à
üÀ
Ü
É
Área
saudável
ficará.
Is that near enough for starters?
You could then use a "Filter" action to sort the lines but, AFAIK, there's no easy way to remove duplicates. So I'd turn to a quick shell script: sort | uniq and do everything in one.
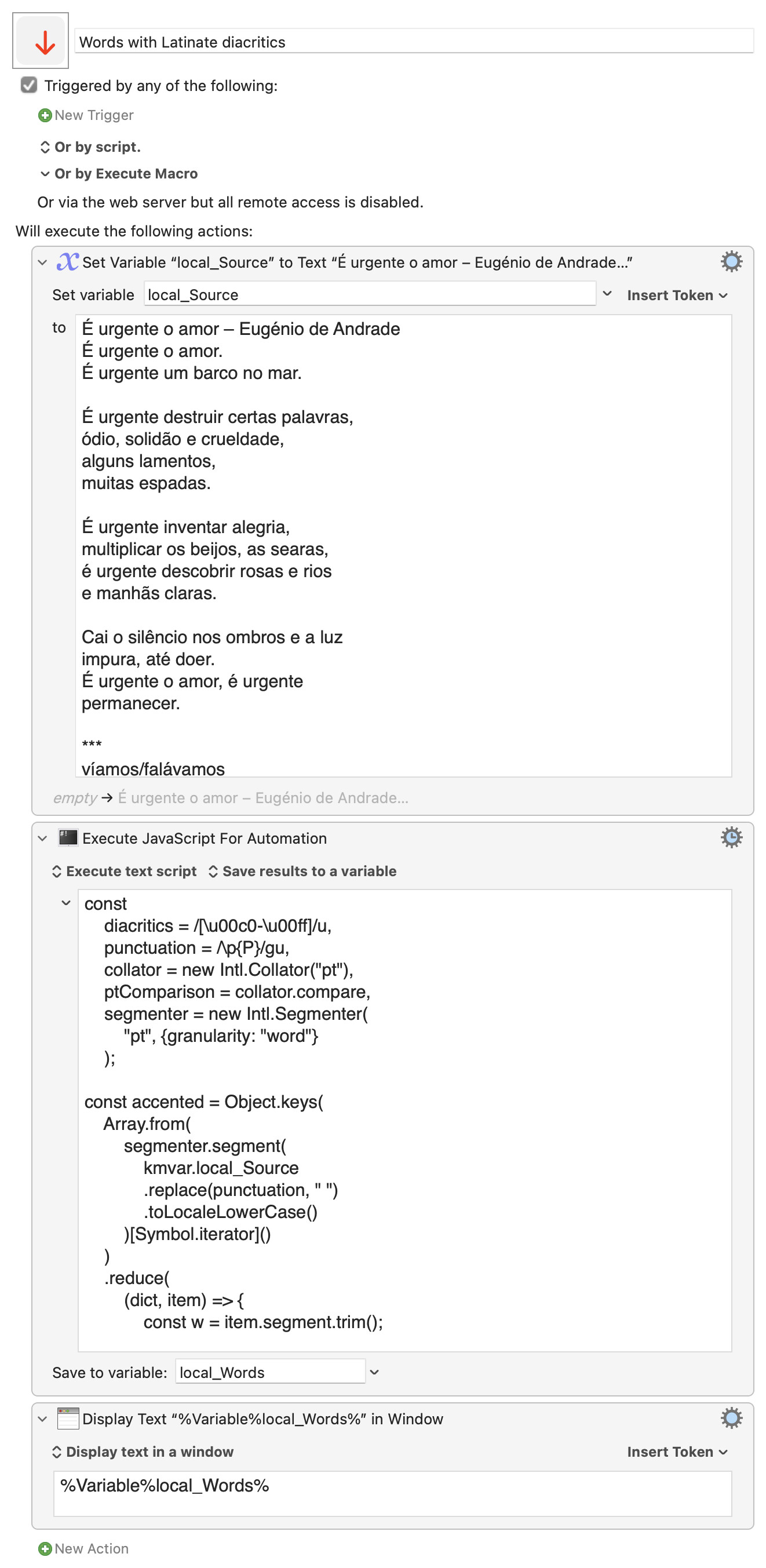
This could certainly be improved -- I'm sure there's a better, more general, way to determine accented characters -- but this may be a good start, or even "good enough" for a one-off.
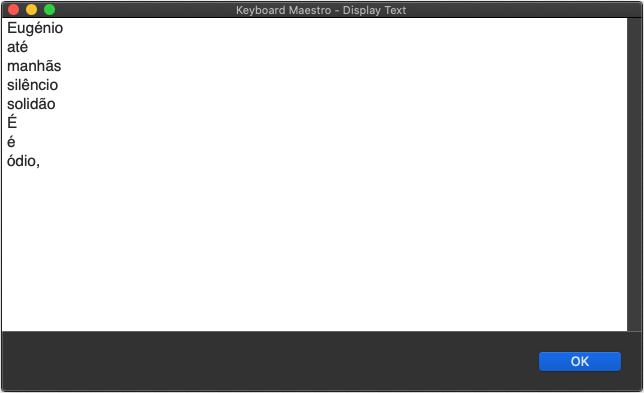
Oh wow this seems to do both things in one...
I noticed that the word ódio wasn't there, though.
It's a lower case ó in the beginning of a sentence. Maybe something in the script isn't including that option?
Thanks for sharing that.
I don't remember who mentioned that boundary trick, but I had it in my notes already.
Since it's something I don't use very often, I completely forgot about it.
I noticed that the üÀ was seen as a group, though, even tough that's not a combination we have in Portuguese, but I wonder why that is?
We have some words where we have 2 accented characters such as acção for example
I tested it and it indeed adds the word ódio, but it also adds the comma:
Not that this is a big deal, I can always run a Search and Replace action, but maybe you know what that's happening so we can have a script that doesn't include other characters?
I'm already super happy with the current macro anyway
Thank you so much for taking the time to create this.
I don't want to push my luck and it's totally fine if these 2 "requests" are too much work and time. Again, the current macro does all the work. I just noticed 2 things with my actual letter:
1 - Can we ignore words that are the same? For example the words Não, não, or NÃO, all mean the same. There's no difference between à and ã. Would it be simple to implement this? Basically when I use the Text Replacement, I always add the lower case version of words, because when it's the beginning of the sentence it always capitalizes the letter anyway.
2 - I noticed that when I have a slash / in between words, it puts the words together, for example this: víamos/falávamos became víamosfalávamos and unless I use it like this víamos / falávamos with a space before and after the slash, it will always show it as a single word.
Again, the current macro is already a blessing and I appreciate your contribution, if these 2 requests are too complex and time consuming
UPDATED again in the original post to fix these two issues (lower-cased, and replacing punctuation with a space – rather than empty string – to preserve word boundaries)
For this particular scenario, the Text Replacement, it doesn't make a big difference. It's even better that I use the lowercase, because if it saves the word Não instead of não, then it will look wrong in the middle of a sentence, but in the beginning of the sentence it will auto-capitalize anyway.
What do you mean?
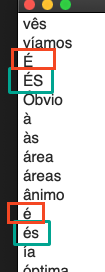
I just tried your solution and it's not removing the duplicates
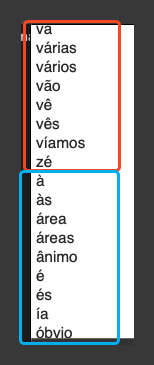
and it's also not sorting alphabetically, at least not "logically" speaking.
It seems to first sort all words where the first letter is capital, but no accented character. Then it sorts all lowercase first letter, no accent.
Then first letter capitalized and accented
Finally first letter lower case and accented
Thank you again!
I noticed that it indeed does what you said.
One thing I noticed, and that seems to be an "issue" with @Nige_S macro as well: it's sorting the words that don't start with an accented character, and then sorts the ones with accented first character, like this:
Is this fixable or is it a limitation of those characters?
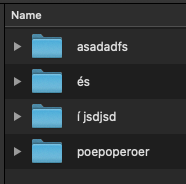
For example in Finder it doesn't make a difference:
EDIT: I just added a Filter set to "Sort" and it works, in case that's complicated to do with the script itself. Anyway, thank you so much for your help on this! Super valuable stuff!