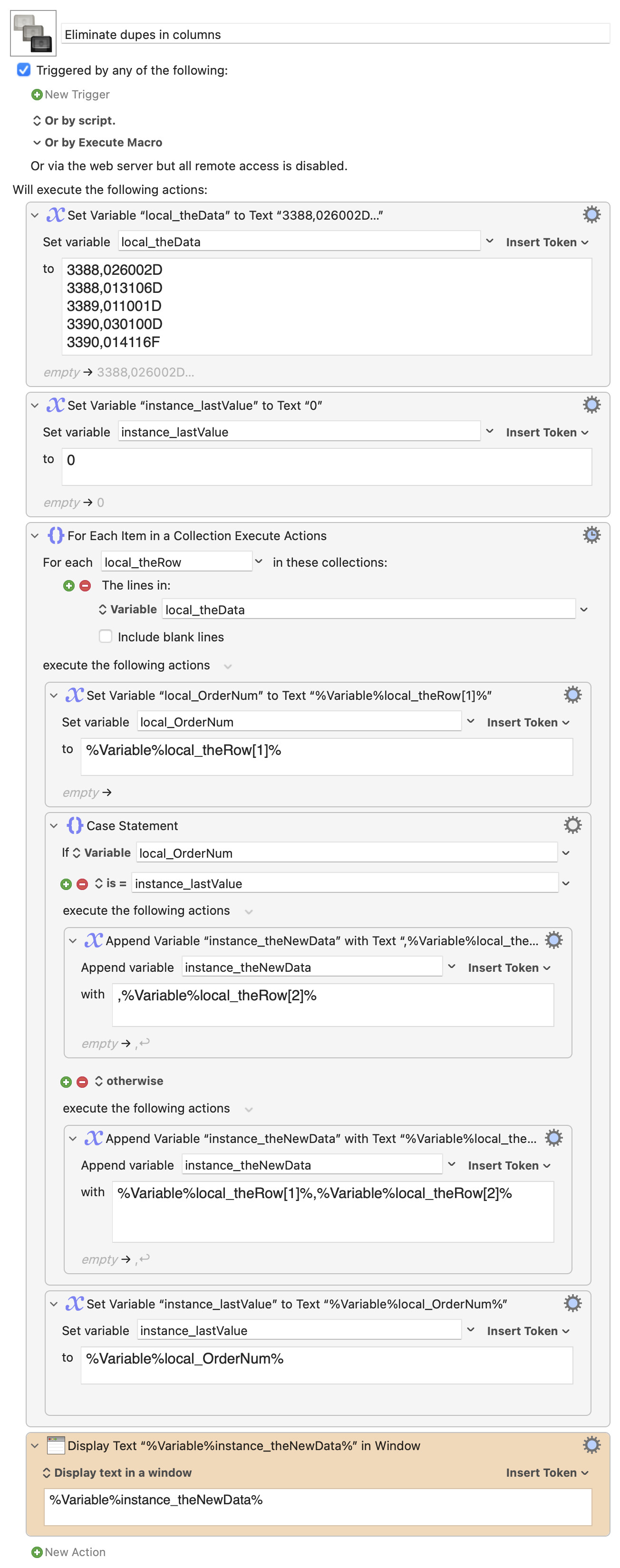
I have an exported CSV file that contains order numbers for each order line. I would like to delete all duplicates in this column so that only the first line item of each order contains the order number.
I tried to use Named Clipboards and comparing them with "If...Then...Else" but I can't manage to create a loop that works for every situation.
I'm wondering if anyone has a better approach. I just ask for your understanding that I prefer to use the native KM tools and don't want to work with scripts, as I can no longer maintain them afterwards.
Thanks in advance.
Here's a basic "proof of concept," as I don't know how you're dealing with the CSV file, nor what the rest of your macro looks like.
Eliminate dupes in columns.kmmacros (5.9 KB)
Screenshot of macro
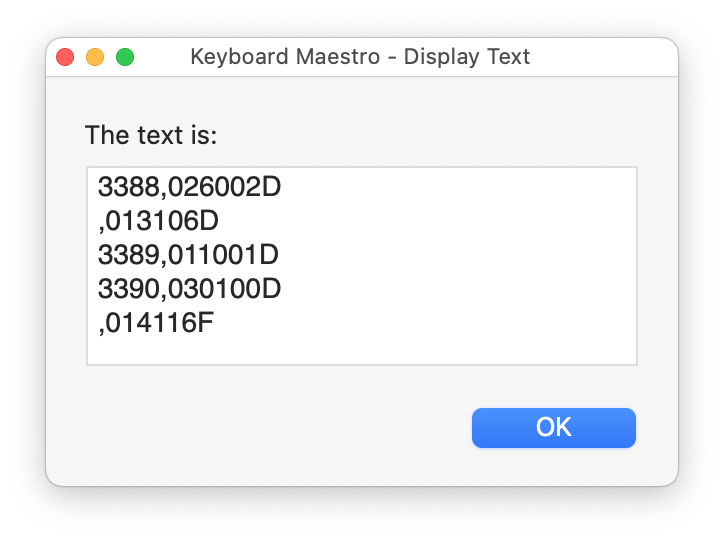
Results:
It works by reading each line in the CSV (or variable, in the case of the demo), and comparing the order number to the prior order number. If they're the same, it writes only the second value to a new variable, otherwise it writes both values. It then saves the current order number as the new target value, and processes the next row.
Hope that's enough to get you going;
-rob.
1 Like
Thanks so much Rob. I will give it a try.
@griffman Thanks again so much!
I adapted your "proof of concept" a bit to just use the data from the very first column which worked fine and is absolutely sufficient for my goal. This allows me to continue working with additional actions in this sheet.